


これは普通の自動運転ビデオだと思いますか?
 画像
画像
このコンテンツは、元の意味を変更せずに中国語に書き直す必要があります。
どのフレームも「本物」ではありません。
 写真
写真
さまざまな道路状況、さまざまな気象条件、20 以上の状況をシミュレートでき、その効果は本物とまったく同じです。
 写真
写真
世界モデルが再び多大な貢献を果たしました。これを見たルカンさんは熱心にリツイートした。
 写真
写真
最新バージョンの GAIA-1 によってもたらされる上記の効果によると、
このプロジェクトの規模4,700 時間の運転ビデオ トレーニングを通じて 90 億のパラメータに達し、ビデオ、テキスト、または操作を入力して自動運転ビデオを生成する効果を達成することに成功しました。
最も直接的な利点は、将来のイベントをより適切に予測できることです。 20 さまざまなシナリオをシミュレーションできるため、自動運転の安全性がさらに向上し、コストが削減されます。
 写真
写真
私たちのクリエイティブチームは、これは自動運転ゲームのルールを完全に変えるだろうと率直に述べました。
それでは、GAIA-1 はどのように実装されるのでしょうか?
GAIA-1 は複数のモードを備えた生成世界モデルです
ビデオ、テキスト、アクションを入力として利用することで、システムはリアルな運転を実現します自動運転車の動作とシーンの特性を細かく制御しながら、シーン ビデオを生成できます。
テキスト プロンプトのみを使用してビデオを生成できます。
 画像
画像
モデルの原理は、大規模な言語モデルの原理と似ています。つまり、次のマークを予測します。
モデルは、ベクトル量子化表現を使用してビデオ フレームを離散化し、変換される将来のシーンを予測できます。予測シーケンスへの次のトークン。次に、拡散モデルを使用して、ワールド モデルの言語空間から高品質のビデオが生成されます。
具体的な手順は次のとおりです。
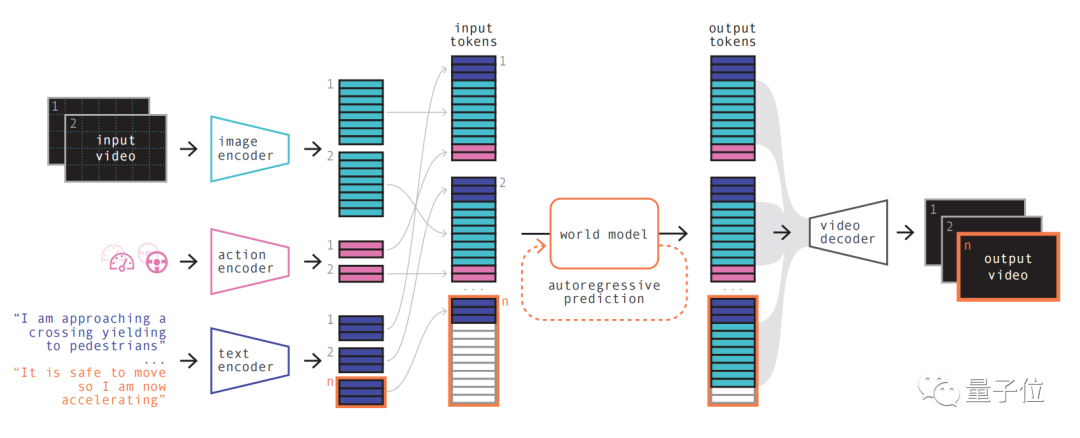 図
図
#最初のステップは理解しやすいもので、再コード化して配置し、さまざまな入力を組み合わせます。
特殊なエンコーダを使用してさまざまな入力をエンコードし、さまざまな入力を共有表現に投影します。テキストおよびビデオ エンコーダは入力を分離して埋め込みますが、操作表現は共有表現に個別に投影され、これらのエンコードされた表現は時間的に一貫しています。
配置が完了すると、ワールド モデルの重要な部分が表示されます。
自己回帰トランスフォーマーとして、シーケンス内の次のイメージ トークンのセットを予測できます。また、前の画像トークンだけでなく、テキストや操作のコンテキスト情報も考慮されます。
モデルによって生成されたコンテンツは、画像の一貫性を維持するだけでなく、予測されたテキストやアクションとの一貫性も維持します
チームは、GAIA の世界モデルのサイズを紹介しました。 1 は 65 億のパラメータで、A100 の 64 ブロックで 15 日間トレーニングされました。
最後に、ビデオ デコーダとビデオ拡散モデルを使用して、これらのトークンをビデオに変換します。
このステップの重要性は、ビデオのセマンティック品質、画像精度、時間的一貫性を確保することです
GAIA-1 のビデオ デコーダは 26 億パラメータの規模を持ち、32 台の A100 を使用してトレーニングされています15日以内に届きます。
GAIA-1 は原理的に大規模な言語モデルに似ているだけでなく、モデルの規模が拡大するにつれて生成品質が向上するという特徴も示していることは注目に値します。
#Picture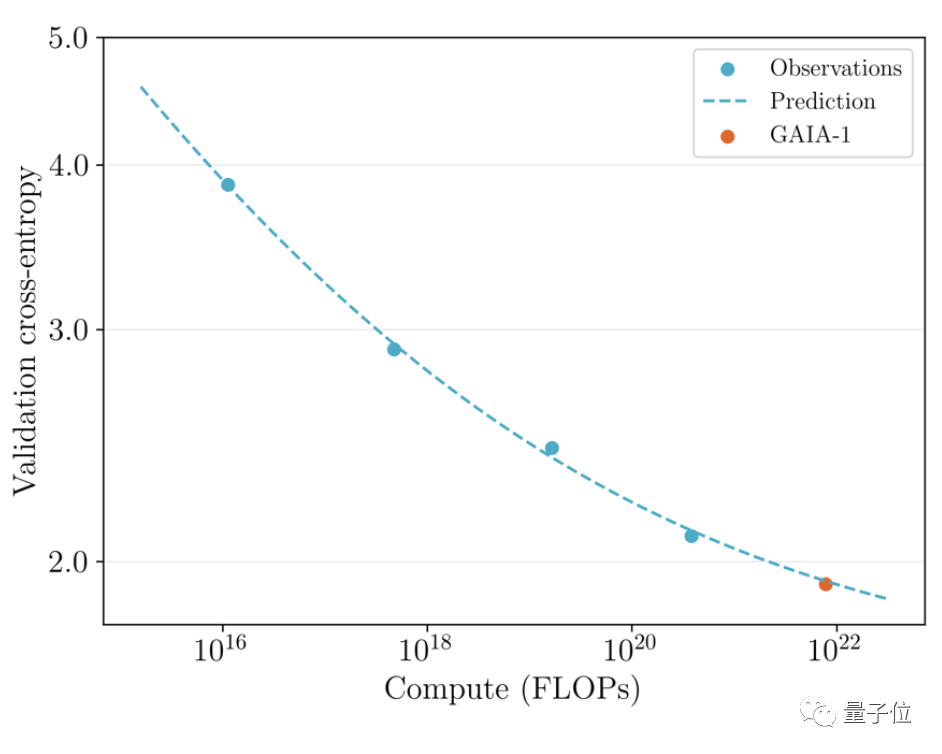 チームは、6 月に以前にリリースされた初期バージョンと最新の効果を比較しました。
チームは、6 月に以前にリリースされた初期バージョンと最新の効果を比較しました。
後者は前者の 480 倍の大きさです。
動画のディテールや解像度などが大幅に向上していることが直感的にわかります。
写真 実用化の観点から見ると、GAIA-1 の登場も一定の影響を与えており、主要クリエイティブチームはこれが変わるだろうと述べています。自動運転のルール
実用化の観点から見ると、GAIA-1 の登場も一定の影響を与えており、主要クリエイティブチームはこれが変わるだろうと述べています。自動運転のルール
 写真
写真
その理由は 3 つの側面から説明できます:
まず、安全性の観点から言えば、世界モデルは未来をシミュレーションし、AIに自律走行車の安全性にとって重要な独自の決定を実現する能力を与えることができます。運転中。
第二に、トレーニング データも自動運転にとって非常に重要です。生成されるデータは、より安全で、コスト効率が高く、無限に拡張可能です。
生成 AI は、自動運転が直面するロングテール シナリオの課題の 1 つを解決できます。霧の天候で道路を横断する歩行者に遭遇するなど、よりエッジなシナリオに対応できます。これにより、自動運転の機能がさらに向上します。
GAIA-1 は英国の自動運転スタートアップ Wayve によって開発されました
Wayve は 2017 年に設立されました。投資家には Microsoft などが含まれ、その評価額はユニコーンに達しています。
創設者は Alex Kendall と Amar Shah で、二人ともケンブリッジ大学で機械学習の博士号を取得しています
 写真
写真
技術的な路線では、テスラと同様に、ウェイブはカメラを使用した純粋に視覚的なソリューションの使用を提唱し、高精度の地図を非常に早い段階で放棄し、「瞬時認識」路線をしっかりと守ります。
少し前に、チームがリリースした別の大型モデル LINGO-1 も広く注目を集めました。
この自動運転モデルは、走行中にリアルタイムでコメントを生成できるため、モデルの精度がさらに向上します。説明可能性
今年3月、ビル・ゲイツ氏もウェイブの自動運転車に試乗した。
 写真
写真
紙のアドレス: //m.sbmmt.com/link/1f8c4b6a0115a4617e285b4494126fbf
参考リンク:
[1]//m.sbmmt.com/link/85dca1d270f7f9aef00c9d372f114482[2]//m.sbmmt.com/link/a4c22565dfafb162a17a7c357ca9e0be
以上がルカン氏、自動運転ユニコーン詐欺に深く失望の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



