


言語モデルはさまざまな語彙リストによってどのような影響を受けますか?これらの効果のバランスをとるにはどうすればよいでしょうか?
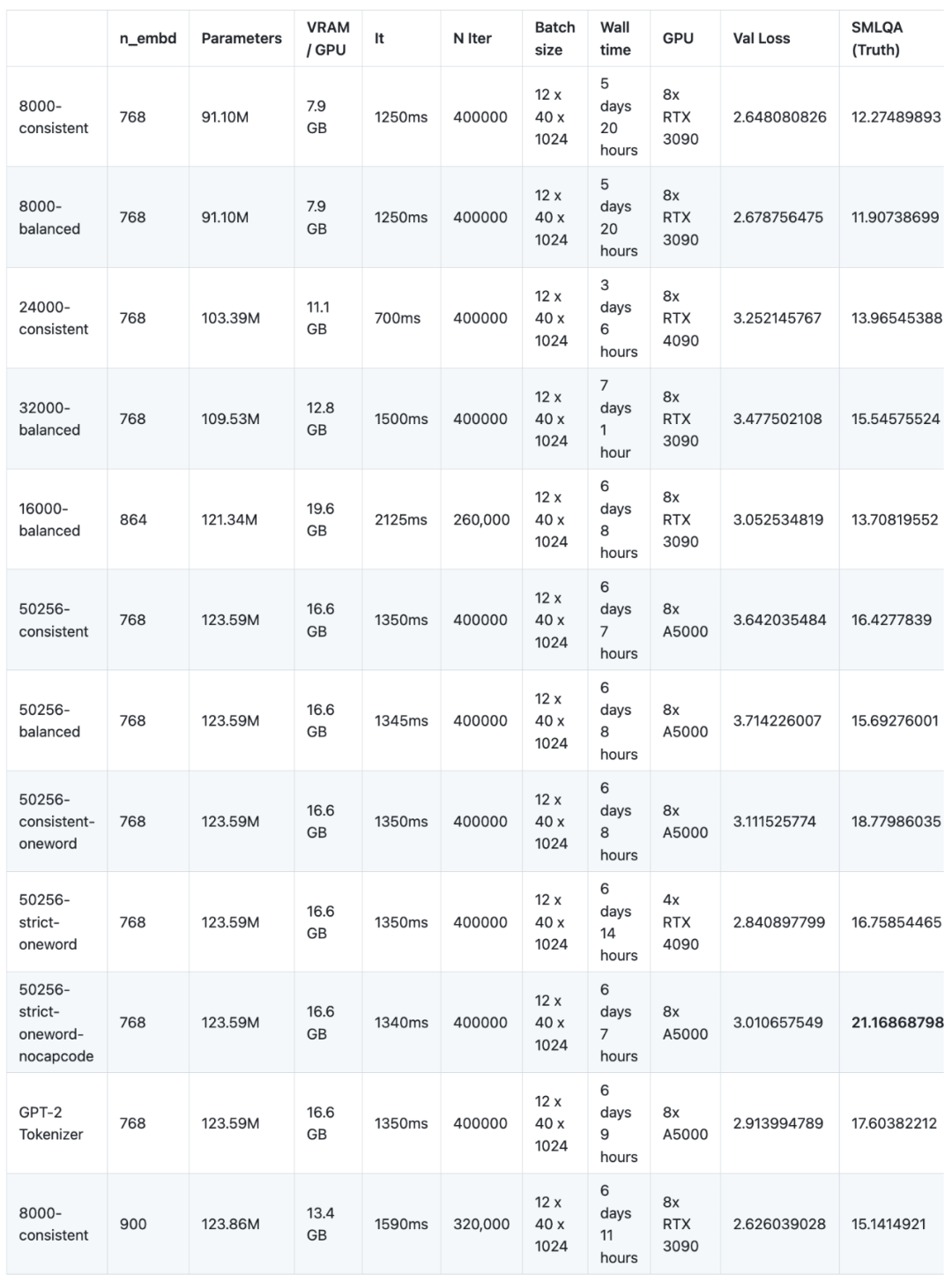
最近の実験では、研究者はさまざまなコーパスを使用して 16 の言語モデルを事前トレーニングし、微調整しました。この実験では、小規模アーキテクチャ (GPT-2 SMALL に基づく) NanoGPT を使用し、合計 12 個のモデルをトレーニングしました。 NanoGPT のネットワーク アーキテクチャ構成は、12 個のアテンション ヘッド、12 層のトランスフォーマー、ワード埋め込み次元は 768、約 400,000 回の反復 (約 10 エポック) が実行されました。次に、4 つのモデルが GPT-2 MEDIUM でトレーニングされ、GPT-2 MEDIUM のアーキテクチャは 16 個のアテンション ヘッド、24 層のトランスフォーマー、単語埋め込み次元 1024 に設定され、600,000 回の反復が実行されました。すべてのモデルは、NanoGPT および OpenWebText データセットを使用して事前トレーニングされています。微調整の観点から、研究者らは baize-chatbot が提供する指示データセットを使用し、2 種類のモデルにそれぞれ 20,000 と 500,000 の「辞書」エントリを追加しました。研究者らは将来、コード、事前トレーニングされたモデル、命令調整されたモデル、および微調整されたデータセットをリリースする予定です
# ただし、GPU スポンサーが不足しているため (これはは無料のオープンソースプロジェクトです)、コスト削減のため、研究者は現在継続していませんが、研究内容をさらに改善する余地があります。事前トレーニング段階では、これら 16 のモデルを 8 つの GPU で合計 147 日間実行する必要があります (1 つの GPU を 1,176 日間使用する必要があります)。費用は 8,000 米ドルです。
調査結果は次のように要約できます:
エンコード方式に関しては、TokenMonster (550256-strict-nocapcode) ボキャブラリは GPT-2 Tokenizer よりも優れたパフォーマンスを発揮します。すべてのインジケーターのtiktoken p50k_base。
##この現象は、トレーニング プロセス中に発見された興味深い機能です。モデル トレーニングの仕組みを考えると、当然のことです。研究者は自分の推論を正当化する証拠を何も持っていない。しかし本質的には、言語の流暢さは言語の事実性(非常に微妙で文脈に依存する)よりもバックプロパゲーション中に修正するのが簡単であるため、トークナイザーの効率の向上は言語の事実性よりも一貫性が低いことを意味します。性別に関係なくSMLQA (Ground Truth) ベンチマークで見られるように、情報の忠実度の向上に直接つながる波及効果が生じます。簡単に言えば、より優れたトークナイザーはより現実的なモデルですが、必ずしもよりスムーズなモデルであるとは限りません。逆に、非効率なトークナイザーを備えたモデルでも流暢に書くことを学習できますが、流暢さによる追加コストによりモデルの信頼性が低下します。
語彙サイズの影響
研究者らは TokenMonster をテストし、バランス、一貫性、厳密という 3 つの特定の最適化モードをテストしました。さまざまな最適化モードは、句読点とキャップコードを単語トークンと組み合わせる方法に影響します。研究者らは当初、一貫性モードのほうが (複雑さが少ないため) パフォーマンスは向上するが、単語比率 (つまり、文字とトークンの比率) はわずかに低くなるだろうと予測していました。実験結果は上記の推測を裏付けるようですが、研究者はいくつかの現象も観察しています。まず、SMLQA (Ground Truth) ベンチマークでは、コンシステント モードのパフォーマンスがバランス モードよりも約 5% 優れているようです。ただし、コンシステント モードのパフォーマンスは、SQuAD (データ抽出) ベンチマークで大幅に低下します (28%)。ただし、SQuAD ベンチマークは大きな不確実性 (繰り返し実行すると異なる結果が得られる) を示しており、説得力がありません。研究者らはバランスの取れたパターンと一貫性のあるパターンの間の収束をテストしなかったので、これは単純に一貫したパターンの方が学習しやすいことを意味しているのかもしれません。実際、SQuAD は学習が難しく、幻覚を起こす可能性が低いため、SQuAD (データ抽出) では一貫性がより優れている可能性があります。
これは、句読点と単語を 1 つのトークンに組み合わせることに明らかな問題がないことを意味するため、それ自体興味深い発見です。これまでの他のすべてのトークナイザーは、句読点を文字から分離する必要があると主張してきましたが、ここでの結果からわかるように、目立ったパフォーマンスの低下なしに単語と句読点を単一のトークンにマージできます。これは、50256-consistent-oneword によっても確認されており、この組み合わせは 50256-strict-oneword-nocapcode と同等のパフォーマンスを発揮し、p50k_base を上回ります。 50256-consistent-oneword は、単純な句読点と単語トークンを組み合わせます (他の 2 つの組み合わせはそうではありません)。
capcode の厳密モードを有効にすると、明らかな悪影響が生じます。 SMLQA では、50256-strict-oneword-nocapcode のスコアは 21.2、SQuAD では 23.8、50256-strict-oneword のスコアはそれぞれ 16.8 と 20.0 です。理由は明らかです。厳密な最適化モードでは、キャップコードと単語トークンのマージが防止され、その結果、同じテキストを表すためにより多くのトークンが必要となり、単語比率が 8% 減少します。実際、strict-nocapcode は、strict モードよりも一貫したモードに似ています。さまざまな指標において、50256-consistent-oneword と 50256-strict-oneword-nocapcode はほぼ同等です。
ほとんどの場合、研究者は、このモデルがインクルージョンの学習に役立つと結論付けました。句読点や単語のトークンはそれほど難しくありません。つまり、一貫性モデルは、平衡モデルよりも文法精度が高く、文法エラーが少ないということです。研究者らは、あらゆることを考慮して、全員が整合性モードを使用することを推奨しています。 Strict モードは、capcode が無効になっている場合にのみ使用できます
構文の精度への影響
#MTLD への影響
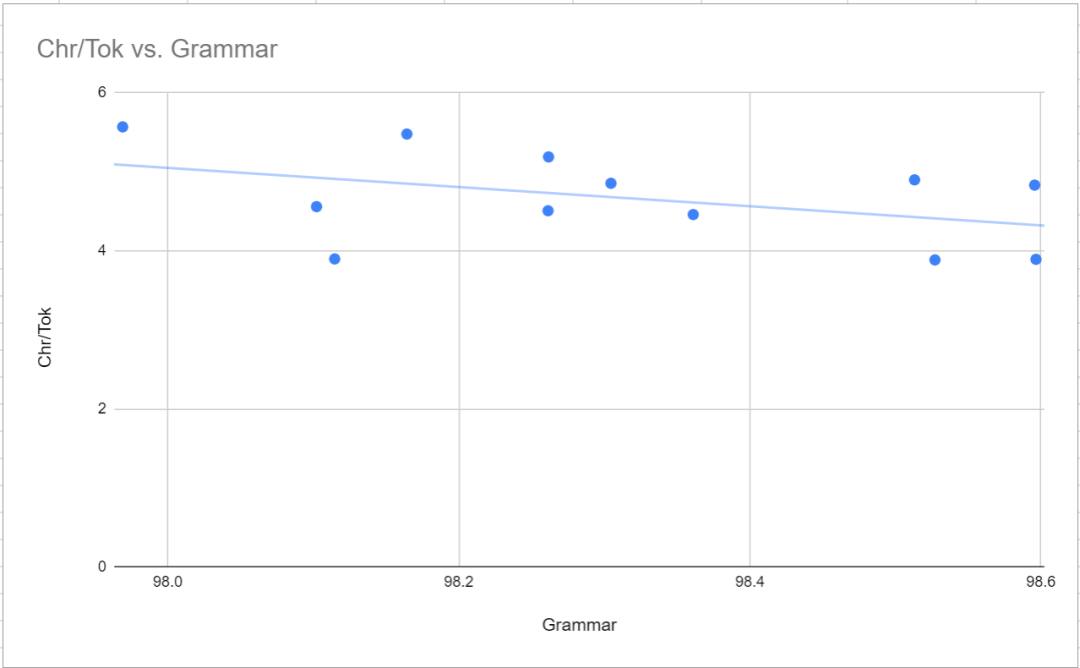
中規模モデルでは、p50k_base の MTLD が最も高くなります。 , これは 43.85 ですが、文法スコアも最低です。この理由は不明ですが、研究者らはトレーニングデータの選択が少し奇妙だったのではないかと推測しています。
SQuAD ベンチマークの目的は、テキストからデータを抽出するモデルの能力を評価することです。具体的な方法は、テキストの段落を提供して質問し、そのテキストの段落で答えが見つかる必要があるというものです。テスト結果はあまり意味がなく、明らかなパターンや相関関係はなく、モデルの全体的なパラメーターの影響を受けません。実際、SQuAD では、9,100 万個のパラメーターを含む 8000 バランス モデルの方が、3 億 5,400 万個のパラメーターを含む 50256-consistent-oneword モデルよりも高いスコアを獲得しました。この理由としては、このスタイルの例が十分にないか、微調整データセット内の質問と回答のペアが多すぎることが考えられます。あるいは、これは単に理想的とは言えないベンチマークである可能性があります。
#SMLQA ベンチマークは、Test によって提案されています。 「ジャカルタはどこの国の首都ですか?」「ハリー・ポッターの本を書いたのは誰ですか?」などの常識的な質問に客観的に答えた「真実」。
このベンチマーク テストでは、2 つのリファレンス トークナイザー、GPT-2 Tokenizer と p50k_base が非常に優れたパフォーマンスを示したことは注目に値します。研究者らは当初、数カ月の時間と数千ドルを無駄にしたと考えていたが、tiktokenのパフォーマンスがTokenMonsterよりも優れていたことが判明した。ただし、この問題は各トークンに対応する単語の数に関連していることが判明しました。これは、以下の図に示すように、「MEDIUM」モデルで特に顕著です
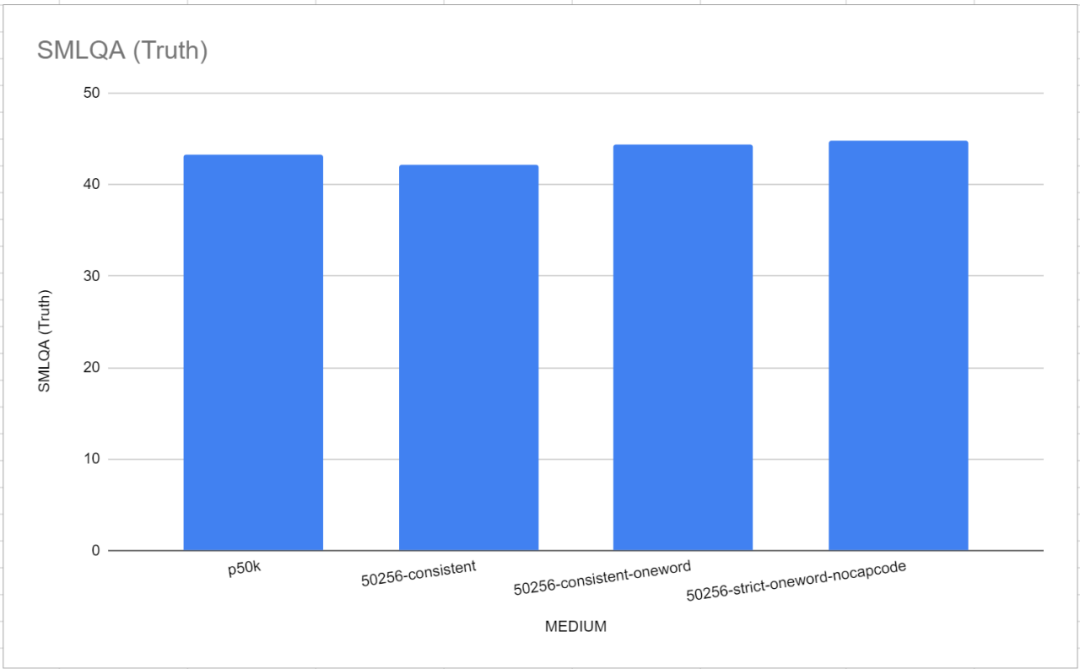
##単一単語の語彙のパフォーマンスは、各トークンが複数の単語に対応する TokenMonster のデフォルトの語彙よりもわずかに優れています。 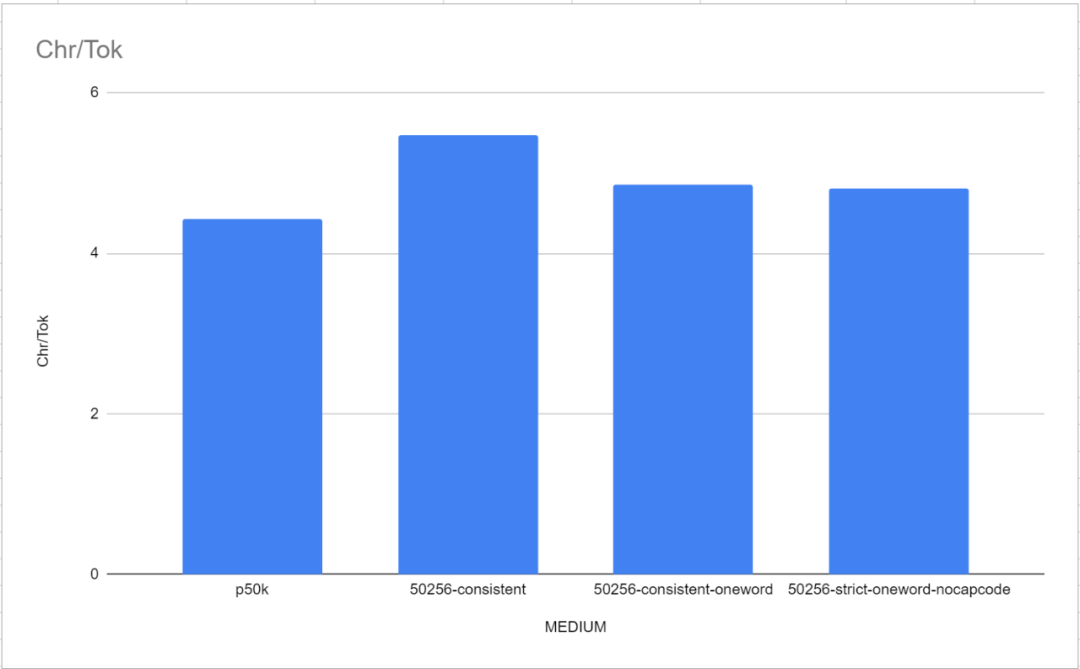
小規模モデルのピアソン相関:
#小規模モデルの結論:
 書き直された内容: 語彙数が 32,000 のときに最適な語彙レベルに達します。 8,000 から 32,000 への語彙増加段階では、語彙を増やすことでモデルの精度が向上します。ただし、語彙サイズが 32,000 から 50,257 に増加すると、モデルの合計パラメーターもそれに応じて増加しますが、精度の向上はわずか 1% です。 32,000 を超えると、ゲインは急激に減少します。
書き直された内容: 語彙数が 32,000 のときに最適な語彙レベルに達します。 8,000 から 32,000 への語彙増加段階では、語彙を増やすことでモデルの精度が向上します。ただし、語彙サイズが 32,000 から 50,257 に増加すると、モデルの合計パラメーターもそれに応じて増加しますが、精度の向上はわずか 1% です。 32,000 を超えると、ゲインは急激に減少します。
不適切なトークナイザーの設計はモデルの精度に影響を与えますが、文法の正しさや言語の多様性には影響しません。パラメータ範囲が 9,000 万から 1 億 2,500 万の、より複雑な文法ルール (複数の単語に対応するトークン、単語と句読点の組み合わせ、キャップコード エンコード トークン、総語彙削減など) を使用したトークナイザーのグラウンド トゥルース ベンチマークのパフォーマンス 悪い。ただし、この洗練されたトークナイザーの設計は、生成されたテキストの言語の多様性や文法の正しさに対して統計的に有意な影響を及ぼしませんでした。 9,000 万個のパラメータを持つモデルなどのコンパクトなモデルでも、より複雑なマーカーを効果的に利用できます。複雑な語彙ほど学習に時間がかかり、基本的な事実に関連する情報を取得するのにかかる時間が短縮されます。これらのモデルはいずれも完全にトレーニングされていないため、パフォーマンスのギャップを埋めるためのさらなるトレーニングの可能性はまだわかりません。
中国語で書き直すと次のようになります。 3. 検証損失は、異なるトークナイザーを使用したモデルを比較するための有効な指標ではありません。検証損失には、特定のトークナイザーの単語比率 (トークンあたりの平均文字数) と非常に強い相関関係 (0.97 ピアソン相関) があります。トークナイザー間で損失値を比較するには、損失値は各トークンに対応する文字の平均数に比例するため、トークンではなく文字に関連して損失を測定する方が便利な場合があります。
4. F1 スコアは、言語モデルを評価するための指標としては適していません。これらの言語モデルは、可変長の応答を生成するようにトレーニングされているためです (完了はテキスト終了マーカーによって示されます)。これは、テキスト シーケンスが長くなるほど、F1 式のペナルティが厳しくなるためです。 F1 スコアは、より短い応答モデルを生成する傾向があります。文法的に一貫した応答を生成する能力は微調整できます。これらの回答は多くの場合不正確または幻想的ですが、比較的一貫性があり、文脈上の背景を理解していることを示しています。有意であり、単語比率とわずかに負の相関がありました。これは、単語対単語の比率が大きい語彙では、文法的および語彙の多様性の学習が若干難しくなるということを意味します
7. モデル パラメーターのサイズを調整するとき、単語対単語の比率は、ワード比率は、SMLQA (Ground Truth の間に統計的に有意な相関関係はありません) または SQuAD (情報抽出) ベンチマークに関連しています。これは、単語対単語の比率が高いトークナイザーがモデルのパフォーマンスに悪影響を及ぼさないことを意味します。
「バランスのとれた」カテゴリと比較すると、「一貫性のある」カテゴリは、SMLQA (グラウンド トゥルース) ベンチマークではわずかに優れたパフォーマンスを示しているようですが、SQuAD (情報抽出) ベンチマークではパフォーマンスが劣ります。 。これを確認するにはさらに多くのデータが必要ですが、
#16 層のアテンション ヘッドと 24 層のトランス層を備えた中型モデル
#小規模モデルのトレーニングとベンチマークを行った後、研究者らは、測定結果がモデルの学習能力ではなく、モデルの学習速度を反映していることを明らかに発見しました。さらに、デフォルトの NanoGPT パラメータが使用されたため、研究者らは GPU の計算能力を最適化しませんでした。この問題を解決するために、研究者らは 50,257 個のトークンを備えたトークナイザーと中言語モデルを使用して 4 つのバリアントを研究することにしました。研究者らは、24GB GPU の VRAM 機能を最大限に活用するために、バッチ サイズを 12 から 36 に調整し、ブロック サイズを 1024 から 256 に削減しました。次に、小規模モデルの場合の 400,000 回の反復ではなく、600,000 回の反復が実行されました。各モデルの事前トレーニングには平均 18 日強かかりました。これは、小規模なモデルに必要な 6 日の 3 倍です。 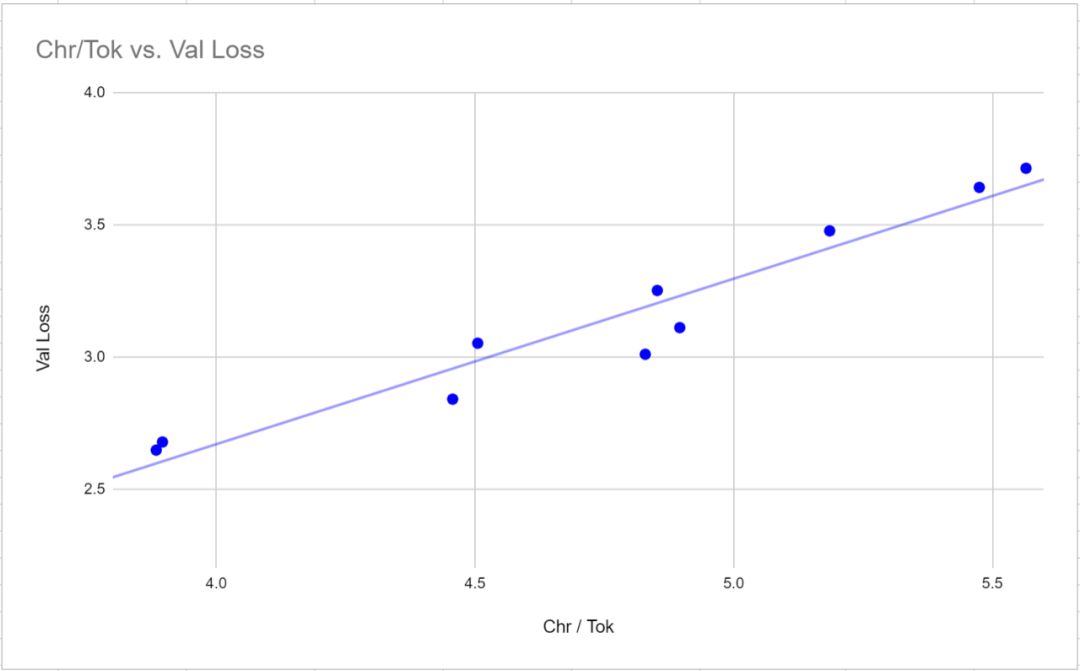
560000 回の反復後、すべてのモデルが収束し始めました。下に示された:###############
次のフェーズでは、englishcode-32000-consistent を使用して MEDIUM モデルのトレーニングとベンチマークを行います。この語彙には 80% の単語トークンと 20% の複数単語トークンが含まれています
以上が言語モデルのトレーニングに対する語彙選択の影響の調査: 画期的な研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



