


次のような鋭い意見を聞いたことがあるかもしれません:
1. NVIDIA の技術的な道をたどると、NVIDIA には決して追いつけないかもしれません。
2. DSA には NVIDIA に追いつくチャンスがあるかもしれませんが、現状では DSA は消滅の危機に瀕しており、希望はありません。大型モデルが現在最前線にあることは誰もが知っており、業界の多くの人々が大型モデルのチップの製造を望んでおり、多くの人々が大型モデルのチップへの投資を望んでいます。
しかし、大型モデルのチップの設計の鍵は何でしょうか?大きな帯域幅と大きなメモリの重要性は誰もが知っているようですが、チップの作り方は NVIDIA とどう違うのでしょうか?この記事では、疑問点を交えながら、インスピレーションを与えることを目的としています。
純粋に意見に基づいた記事は形式主義的に見えることがよくありますが、これはアーキテクチャの例で説明できます
SambaNova Systems は、米国のユニコーン企業トップ 10 に入る企業として知られています。 2021年4月、同社はソフトバンク主導のシリーズD投資で6億7,800万米ドルを受け取り、評価額は50億米ドルに達し、スーパーユニコーン企業となった。以前、SambaNova の投資家には、Google Ventures、Intel Capital、SK、Samsung Catalytic Fund などの世界トップのベンチャー キャピタル ファンドが含まれていました。では、世界トップクラスの投資機関の支持を集めるこのスーパーユニコーン企業は、どのような破壊的な取り組みを行っているのでしょうか?初期の宣伝資料を観察すると、SambaNova が AI の巨人 NVIDIA とは異なる開発の道を選択したことがわかります。
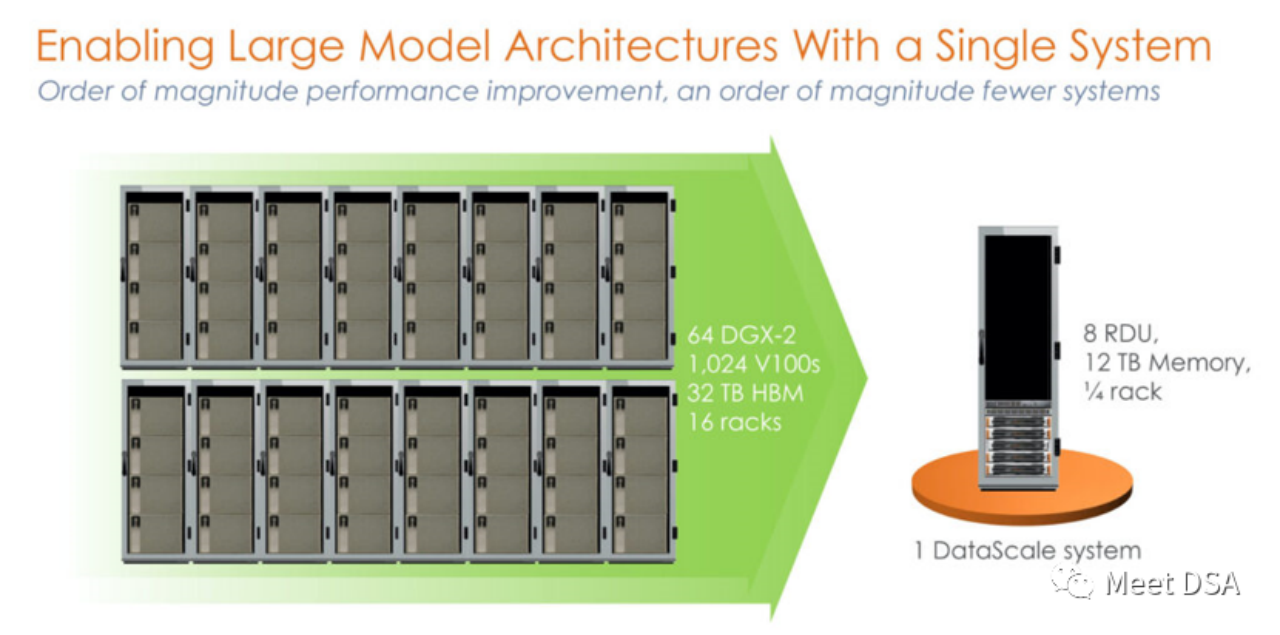 ちょっとショックでしょうか? NVIDIA プラットフォーム上で前例のないパワーで構築された 1024 V100 クラスターは、実際には SambaNova の 1 台のマシンと同等ですか? !これは第 1 世代の製品で、SN10 RDU をベースにしたスタンドアロン 8 カード マシンです。
ちょっとショックでしょうか? NVIDIA プラットフォーム上で前例のないパワーで構築された 1024 V100 クラスターは、実際には SambaNova の 1 台のマシンと同等ですか? !これは第 1 世代の製品で、SN10 RDU をベースにしたスタンドアロン 8 カード マシンです。
この比較は不公平だという人もいるかもしれませんが、NVIDIA には DGX A100 はないのですか? SambaNova 自体もそれに気づいたのか、第 2 世代製品 SN30 は次のように変更されました。
DGX A100 の計算能力は 5 ペタ FLOPS で、SambaNova の第 2 世代 DataScale の計算能力も 5 ペタ FLOPS です。 320GB HBM と 8TB DDR4 のメモリ比較 (編集者は記事を間違って書いた可能性があると推測しています。3TB * 8 であるはずです)。 第 2 世代チップは、実際には SN10 RDU の Die-to-Die バージョンです。 SN10 RDU のアーキテクチャ指標は、320TFLOPS@BF16、320M SRAM、1.5T DDR4 です。以下に説明するように、SN30 RDU はこれに基づいて 2 倍になります。
第 2 世代チップは、実際には SN10 RDU の Die-to-Die バージョンです。 SN10 RDU のアーキテクチャ指標は、320TFLOPS@BF16、320M SRAM、1.5T DDR4 です。以下に説明するように、SN30 RDU はこれに基づいて 2 倍になります。
「このチップには、BF16 浮動小数点精度で 320 テラフロップスを超える計算能力を持つ 640 個のパターン計算ユニットがあり、また 320 MB の容量を持つ 640 個のパターン メモリ ユニットもありました。 「オンチップ SRAM と 150 TB/秒のオンチップ メモリ帯域幅を備えています。各 SN10 プロセッサは、1.5 TB の DDR4 補助メモリにも対応できました。」「Cardinal SN30 RDU では、RDU の容量が 2 倍になり、その理由は次のとおりです。」それは、SambaNova が最初からマルチダイ パッケージングを利用するようにアーキテクチャを設計したことです。この場合、SambaNova は 2 つの新しい RDU を詰め込むことで DataScale マシンの容量を 2 倍にしています。これは 2 つの微調整された SN10 であると推測されます。 「マイクロアーキテクチャの変更により、大規模な基盤モデルのサポートを改善し、SN30 と呼ばれる単一の複合体に統合されました。DataScale システムの各ソケットは、第 1 世代のマシンの 2 倍の計算能力、2 倍のローカル メモリ容量、2 倍のメモリ帯域幅を備えています。」
要点抽出:
大帯域か大容量かの選択しかなく、NVIDIA は大帯域の HBM を選択し、SambaNova は大容量 DDR4 を選択しました。成績ではSambaNovaが勝利。DGX H100 に切り替えた場合、FP8 などの低精度テクノロジーに切り替えても、差は縮まるだけです。 「DGX-H100 が 16 ビット浮動小数点演算で DGX-A100 の 3 倍のパフォーマンスを提供したとしても、SambaNova システムとの差は縮まりません。ただし、精度が低い FP8 では、 Nvidia はパフォーマンスのギャップを埋めることができるかもしれませんが、より低精度のデータと処理に移行することでどれだけの精度が犠牲になるかは不明です。」
もし誰かがそのような効果を達成できるとしたら、それはそうではないでしょうか。完璧な大規模チップソリューションでしょうか?また、NVIDIA との競合と直接対決することもできます。
(おそらく、Grace CPU は LPDDR にも接続でき、容量を増やすのに役立つと言うでしょう。一方、SambaNova はこの問題をどう考えていますか。Grace は単なる大規模なメモリ コントローラーですが、 Hopper は 512GB の DRAM しか搭載できませんが、SN30 には 3TB の DRAM が搭載されています。
Nvidia の「Grace」Arm CPU は、Hopper GPU 用の過大評価されたメモリ コントローラにすぎないと冗談を言っていました。単なるメモリ コントローラーであり、Grace-Hopper スーパー チップ セットの各 Hopper GPU には最大 512 GB のメモリしか搭載されていません。これでも、SambaNova がソケットごとに提供する 3 TB のメモリよりはかなり少ないです
#History帝国がどれほど繁栄していても、目立たない亀裂に注意する必要がある可能性があることを示しています!
Xia He 氏 (Huawei の達人) は最近、NVIDIA 帝国の弱点はコストの観点から見た GB あたりのコストにあるのではないかと推測し、大規模な内部入出力用に安価な DDR メモリを奇抜にスタッキングすることを提案しました。 NVIDIA に革命的な影響を与える可能性があります。 DSA を研究している別の Zhihu マスターは、$/GBps (データ移行) の観点から見ると、LLM はメモリ容量に対する需要が比較的大きいものの、HBM の方がコスト効率が高いと意見を述べています。帯域幅が必要であり、トレーニングには DRAM 内で交換する必要がある多数のパラメータが必要です。
(拡張子://m.sbmmt.com/link/a56ee48e5c142c26cf645b2cc23d78fc)
SambaNova アーキテクチャ例より、大容量で安価な DDR は LLM の問題を解決でき、Xia Core の判断が裏付けられます。しかし、データ移行に必要な膨大な帯域幅もマックラー氏の観点では問題です。では、SambaNova はどのようにしてそれを解決するのでしょうか? RDU アーキテクチャの特性をさらに理解する必要がありますが、実際には、理解するのは簡単です:
A は、RDU アーキテクチャのデータ交換のパラダイムです。従来の GPU アーキテクチャ 各オペレータはすべて、オフチップ DRAM とデータを交換する必要があります。この往復の交換は大量の DDR 帯域幅を占有するため、理解しやすくなるはずです。 B は、SambaNova のアーキテクチャが実現できることです。モデル計算プロセス中、データ移動の大部分はオンチップで保持され、交換のために DRAM を行ったり来たりする必要はありません。
したがって、Bのような効果が得られるのであれば、大帯域と大容量のどちらかを選択する必要がある場合、大容量を選択するのが安全です
。これは次の一節にあるとおりです: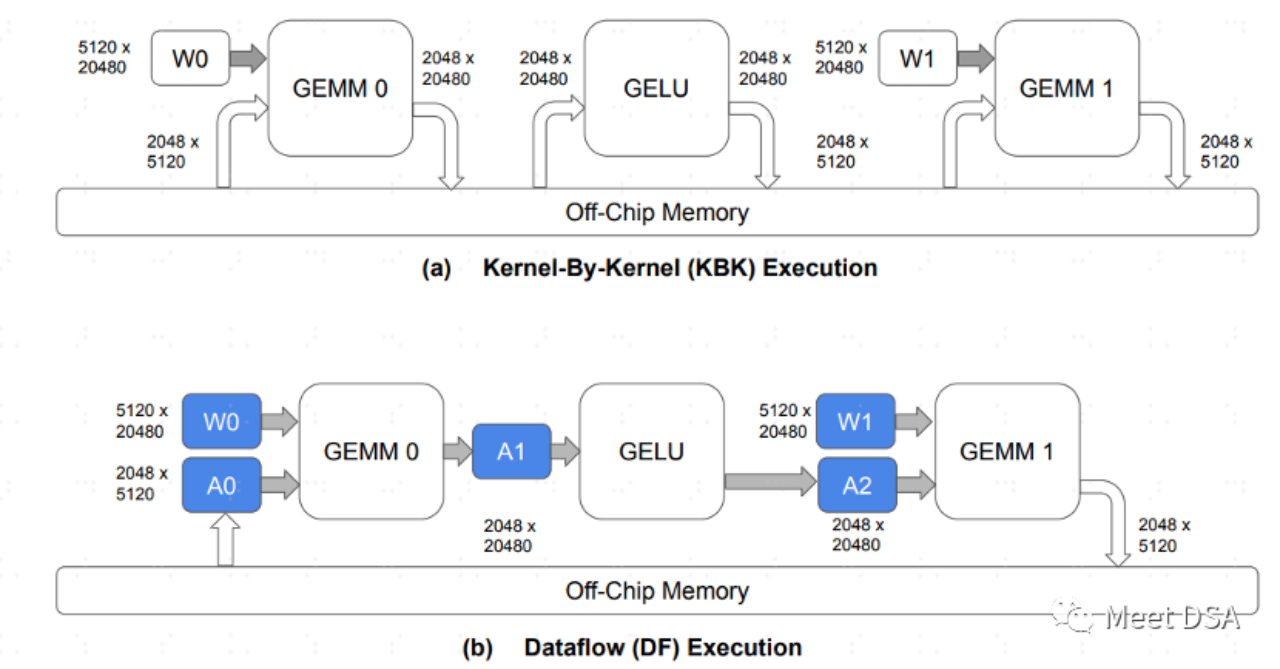 「私たちが抱いている疑問は次のとおりです。基礎モデルをサポートするハイブリッド メモリ アーキテクチャにおいて、メモリ容量とメモリ帯域幅のどちらがより重要ですか? 両方をベースにすることはできません。どのようなアーキテクチャでも単一のメモリ テクノロジを使用できます。また、高速で細いメモリと低速で太いメモリが混在している場合でも、Nvidia と SambaNova の境界線は異なります。」
「私たちが抱いている疑問は次のとおりです。基礎モデルをサポートするハイブリッド メモリ アーキテクチャにおいて、メモリ容量とメモリ帯域幅のどちらがより重要ですか? 両方をベースにすることはできません。どのようなアーキテクチャでも単一のメモリ テクノロジを使用できます。また、高速で細いメモリと低速で太いメモリが混在している場合でも、Nvidia と SambaNova の境界線は異なります。」
SambaNova の RDU/DataFlow アーキテクチャはどのようにして B の効果を実現しますか?それとも、B と同様の効果を達成する他の方法はありますか?次回はそれを共有します。ご興味のあるお友達は、今後も私たちの最新情報に注目してください。
多読資料:[1] https://sambanova.ai/blog/a-new-state-of-the-art-in-nlp-beyond-gpus/
[2]https://www .nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase-ai-foundation-models/
[3]https://hc33. hotchips.org /assets/program/conference/day2/SambaNova HotChips 2021 8 23 v1.pdf
[4]《疎性とデータフローを使用した大規模言語モデルの効率的なトレーニング》
[5]//m.sbmmt.com/link/617974172720b96de92525536de581fa
##書き換える必要がある内容は次のとおりです: [6]https:/ /www.php .cn/link/a56ee48e5c142c26cf645b2cc23d78fc
以上がDSA はどのようにしてコーナーで NVIDIA GPU を追い越すのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



