


Taotian Group と Aicheng Technology は 9 月 12 日、大規模モデル トレーニング フレームワーク Megatron-LLaMA を正式にオープンソース化し、技術開発者が大規模言語モデルのトレーニング パフォーマンスをより便利に向上させ、トレーニング コストを削減できるようにすることを目指しています。 LLaMAコミュニティ。テストの結果、32 枚のカードのトレーニングでは、Megatron-LLaMA は HuggingFace から直接取得したコード バージョンと比較して 176% の高速化を達成でき、大規模なトレーニングでは、Megatron-LLaMA は 32 枚のカードと比較してほぼ直線的なスケーラビリティを有し、高い耐性を示します。ネットワークが不安定になるため。現在、Megatron-LLaMA はオープンソース コミュニティでオンラインになっています。
オープンソースアドレス: https://github.com/alibaba/Megatron-LLaMA
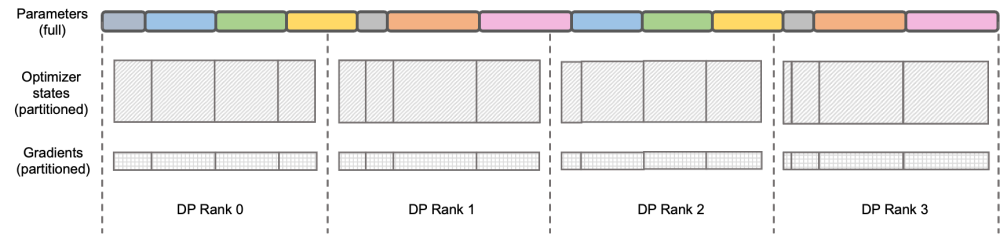 ## igue: DEEPSPEED ZERO Stage-2 DeepSpeed ZeRO は Microsoft が立ち上げた分散トレーニング フレームワークであり、そこで提案されたテクノロジはその後の多くのフレームワークに大きな影響を与えました。 DeepSpeed ZeRO Stage-2 (以下、ZeRO-2) は、計算や通信の負荷を追加することなくメモリ使用量を節約するフレームワークのテクノロジです。上の図に示すように、計算要件により、各ランクにはすべてのパラメータが必要です。ただし、オプティマイザ状態の場合、各ランクはその一部のみを担当し、すべてのランクが完全に繰り返される操作を同時に実行する必要はありません。したがって、ZeRO-2 では、オプティマイザーの状態を各ランクに均等に分割することを提案しています (各変数が均等に分割されているか、特定のランクに完全に保持されていることを保証する必要はないことに注意してください)。各ランクはトレーニング プロセス中にのみ使用する必要があります。 . オプティマイザのステータスと対応する部分のモデル パラメータを更新します。この設定では、この方法でグラデーションを分割することもできます。デフォルトでは、ZeRO-2 は Reduce メソッドを使用してすべてのランク間の勾配を逆に集計します。その後、各ランクは担当するパラメーターの一部を保持するだけで済みます。これにより、冗長な繰り返し計算が排除されるだけでなく、メモリも削減されます。使用法。 。
## igue: DEEPSPEED ZERO Stage-2 DeepSpeed ZeRO は Microsoft が立ち上げた分散トレーニング フレームワークであり、そこで提案されたテクノロジはその後の多くのフレームワークに大きな影響を与えました。 DeepSpeed ZeRO Stage-2 (以下、ZeRO-2) は、計算や通信の負荷を追加することなくメモリ使用量を節約するフレームワークのテクノロジです。上の図に示すように、計算要件により、各ランクにはすべてのパラメータが必要です。ただし、オプティマイザ状態の場合、各ランクはその一部のみを担当し、すべてのランクが完全に繰り返される操作を同時に実行する必要はありません。したがって、ZeRO-2 では、オプティマイザーの状態を各ランクに均等に分割することを提案しています (各変数が均等に分割されているか、特定のランクに完全に保持されていることを保証する必要はないことに注意してください)。各ランクはトレーニング プロセス中にのみ使用する必要があります。 . オプティマイザのステータスと対応する部分のモデル パラメータを更新します。この設定では、この方法でグラデーションを分割することもできます。デフォルトでは、ZeRO-2 は Reduce メソッドを使用してすべてのランク間の勾配を逆に集計します。その後、各ランクは担当するパラメーターの一部を保持するだけで済みます。これにより、冗長な繰り返し計算が排除されるだけでなく、メモリも削減されます。使用法。 。 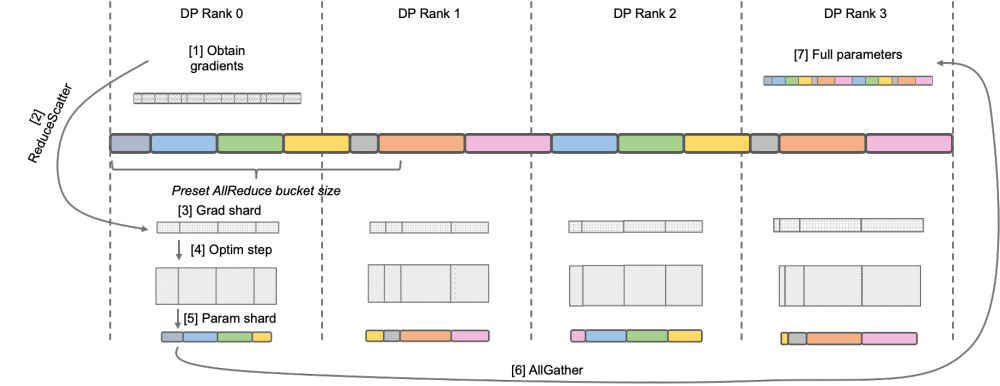 over ‐ over ‐‐ over‐ over‐‐‐‐‐‐ C S PC C _ ‐ ‐ L ‐ L's-M-‐‐‐‐‐'' の DistributedOptimizer を使用して勾配を伝達します。演算子は計算と並行して実行できます。特に、Megatron-LLaMA は、ZeRO の実装と比較して、よりスケーラブルな集合通信方式を使用し、並列処理を前提としたオプティマイザ分割戦略の賢明な最適化を通じてスケーラビリティを向上させます。OverlappedDistributedOptimizer の主な設計は、次の点を保証します: a) 単一セットの通信事業者のデータ量が、通信帯域幅を最大限に活用するのに十分な大きさであること、b) 新しい分割方法で必要な通信データ量が最小限に等しいことデータ並列処理に必要な通信データ量 c) 完全なパラメータまたは勾配およびセグメント化されたパラメータまたは勾配の変換プロセス中に、多すぎるビデオ メモリ コピーを導入することはできません。
over ‐ over ‐‐ over‐ over‐‐‐‐‐‐ C S PC C _ ‐ ‐ L ‐ L's-M-‐‐‐‐‐'' の DistributedOptimizer を使用して勾配を伝達します。演算子は計算と並行して実行できます。特に、Megatron-LLaMA は、ZeRO の実装と比較して、よりスケーラブルな集合通信方式を使用し、並列処理を前提としたオプティマイザ分割戦略の賢明な最適化を通じてスケーラビリティを向上させます。OverlappedDistributedOptimizer の主な設計は、次の点を保証します: a) 単一セットの通信事業者のデータ量が、通信帯域幅を最大限に活用するのに十分な大きさであること、b) 新しい分割方法で必要な通信データ量が最小限に等しいことデータ並列処理に必要な通信データ量 c) 完全なパラメータまたは勾配およびセグメント化されたパラメータまたは勾配の変換プロセス中に、多すぎるビデオ メモリ コピーを導入することはできません。 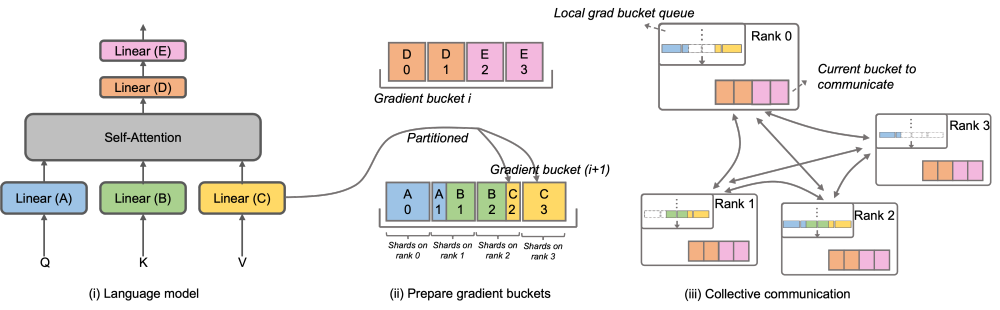
以上がTaotian GroupとAicheng Technologyが協力して、オープンソースの大規模モデルトレーニングフレームワークMegatron-LLaMAをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



