


近年、大規模な実世界データに対する視覚的な事前トレーニングが大幅に進歩し、ピクセル観察に基づくロボット学習に大きな可能性が示されています。ただし、これらの研究は、トレーニング前のデータ、方法、モデルの点で異なります。したがって、どのタイプのデータ、事前トレーニング方法、モデルがロボット制御をより効果的に支援できるかはまだ未解決の問題です。
これに基づいて、ByteDance 研究チームの研究者は次のことから始めました事前トレーニング データセット、モデル アーキテクチャ、トレーニング方法の 3 つの基本的な視点 視覚的な事前トレーニング戦略がロボット操作タスクに与える影響を包括的に研究し、ロボット学習に有益ないくつかの重要な実験結果を提供しました。さらに、自己教師あり学習と教師あり学習を組み合わせた、 Vi-PRoMと呼ばれるロボット操作のための視覚事前学習スキームを提案しました。 前者は対照学習を使用して大規模なラベルなしデータから潜在的なパターンを取得し、後者は視覚的な意味論と時間的な動的変化を学習することを目的としています。さまざまなシミュレーション環境や実際のロボットで行われた多数のロボット動作実験により、このソリューションの優位性が証明されています。

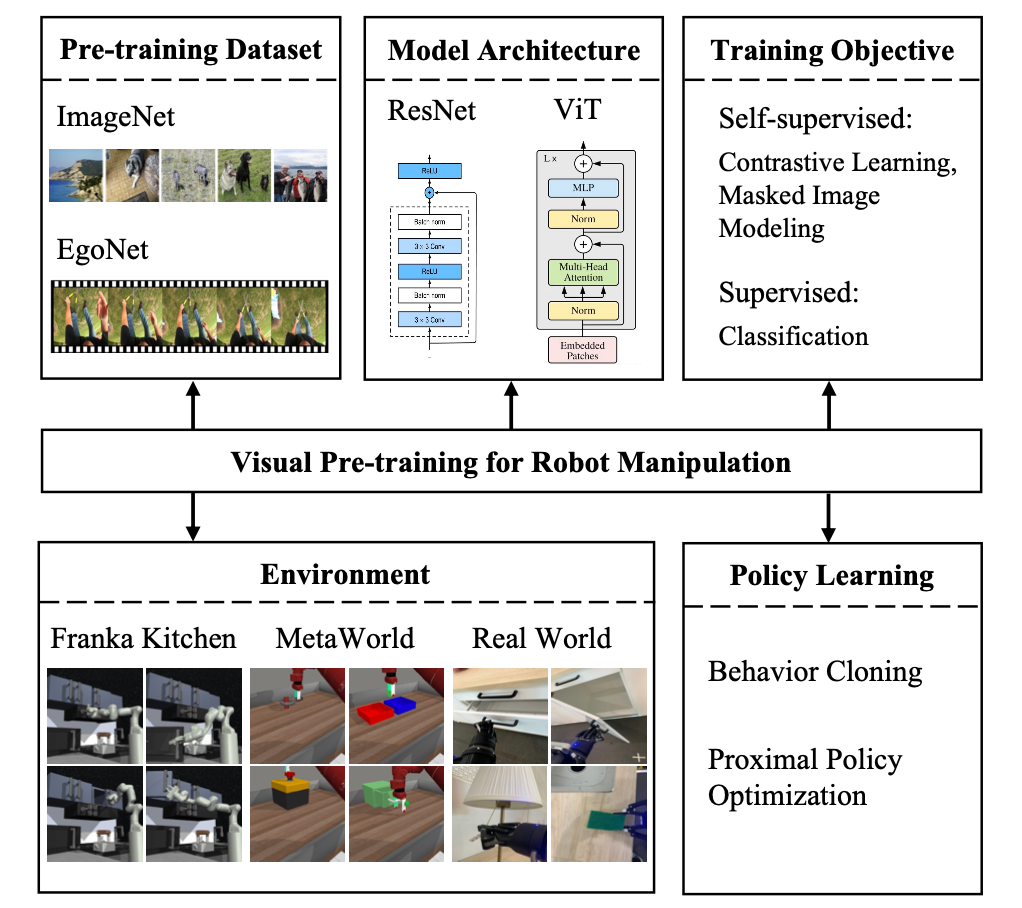
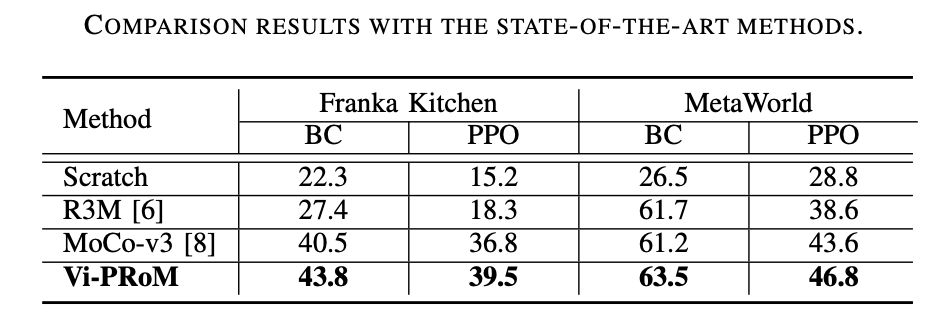
EgoNet は ImageNet よりも強力です。対照的な学習方法を通じてさまざまなデータセット (つまり、ImageNet と EgoNet) でビジュアル エンコーダーを事前トレーニングし、ロボット操作タスクでのパフォーマンスを観察します。以下の表 1 からわかるように、EgoNet で事前トレーニングされたモデルは、ロボット操作タスクで優れたパフォーマンスを達成しました。明らかに、ロボットは操作タスクに関してビデオに含まれるインタラクティブな知識と時間的関係を好みます。さらに、EgoNet の自己中心的な自然画像には世界に関するよりグローバルなコンテキストがあり、より豊富な視覚的特徴を学習できることを意味します
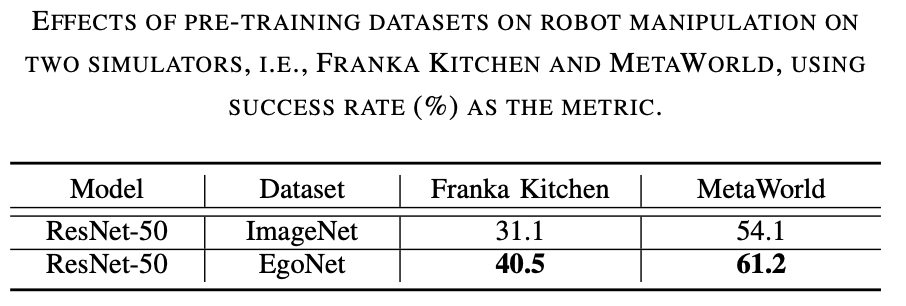
ResNet-50 のパフォーマンスが向上します。以下の表 2 からわかるように、ResNet-50 と ResNet-101 はロボット操作タスクにおいて ResNet-34 よりも優れたパフォーマンスを発揮します。さらに、モデルが ResNet-50 から ResNet-101 に増加してもパフォーマンスは向上しません。
 #事前トレーニング方法
#事前トレーニング方法
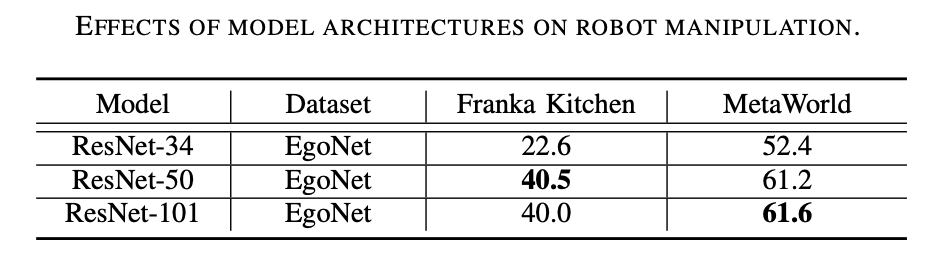
に従って書き直す必要があります。原文の意味 内容は「事前学習法には対照学習が好ましい。以下の表3に示すように、MoCo-v3はImageNetとEgoNetデータセットの両方でMAEを上回っており、マスクと比較して対照学習の方が効果的であることが証明されている」さらに、ロボットの動作には、マスク画像モデリングを通じて学習した構造情報よりも、対照学習を通じて得られた視覚的意味論の方が重要です。」 書き直された内容: 対照学習は、推奨される事前トレーニング方法です。表 3 からわかるように、MoCo-v3 は ImageNet と EgoNet データセットの両方で MAE よりも優れたパフォーマンスを示し、対照学習がマスク画像モデリングよりも効果的であることを示しています。さらに、マスク画像モデリングによって学習された構造情報よりも、対照学習によって得られた視覚的意味論の方がロボットの動作にとって重要です。
アルゴリズムの紹介 
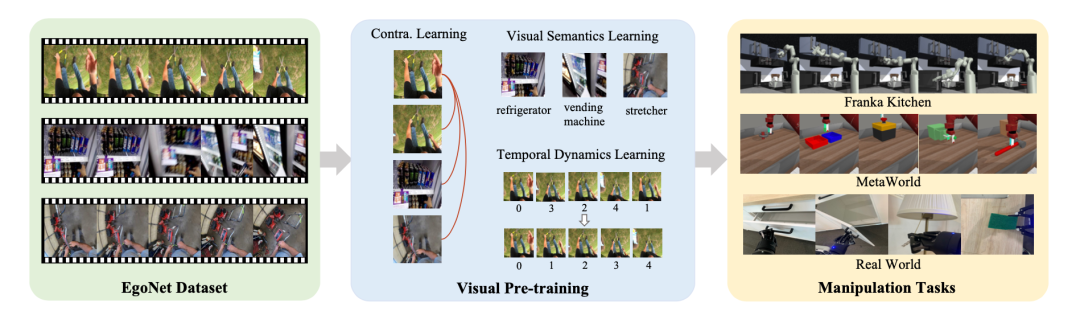
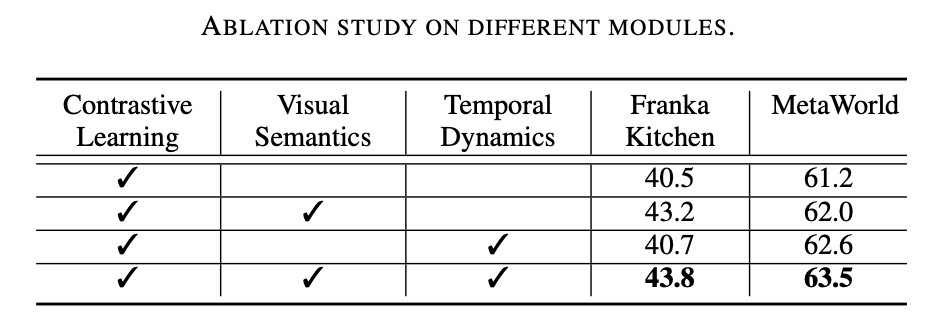
この研究作業では、2 つのシミュレーション環境 (Franka Kitchen と MetaWorld) で広範な実験が行われました。実験結果は、提案された事前トレーニングスキームがロボット操作においてこれまでの最先端の方法よりも優れていることを示しています。アブレーション実験の結果は以下の表に示されており、ロボット操作における視覚的意味学習と時間的動的学習の重要性を証明できます。さらに、両方の学習ターゲットが存在しない場合、Vi-PRoM の成功率は大幅に低下し、視覚的意味学習と時間的動的学習の連携の有効性が実証されました。
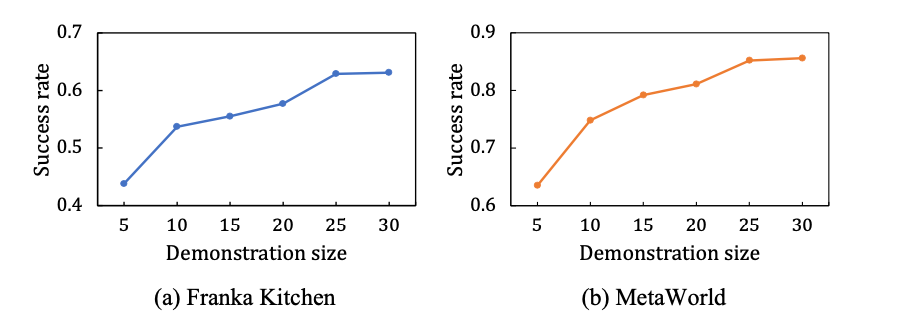
この研究では、Vi-PRoM のスケーラビリティも調査します。以下の左図に示すように、Franka Kitchen および MetaWorld のシミュレーション環境では、デモ データのサイズが大きくなるにつれて Vi-PRoM の成功率が着実に向上しています。大規模なエキスパートのデモンストレーション データセットでトレーニングした後、Vi-PRoM モデルはロボット操作タスクでのスケーラビリティを示します。

# Vi-PRoM の強力なビジュアル表現機能により、本物のロボット引き出しやキャビネットのドアを開けることができます
フランカ キッチンでの実験結果では、Vi-PRoM の成功率が高く、5 つのタスクにおいて R3M よりも効率的であることが示されています。 。
R3M:









 ##Vi-PRoM のビジュアルにより、MetaWorld 上で表現は、アクションの予測に効果的に使用できる優れたセマンティックおよび動的特徴を学習するため、R3M と比較して、Vi-PRoM は操作を完了するために必要なステップが少なくなります。
##Vi-PRoM のビジュアルにより、MetaWorld 上で表現は、アクションの予測に効果的に使用できる優れたセマンティックおよび動的特徴を学習するため、R3M と比較して、Vi-PRoM は操作を完了するために必要なステップが少なくなります。
R3M:

#Vi-PRoM:


以上がタイトル変更: Byte、ロボット操作の成功率と効果を向上させるための Vi-PRoM ビジュアル事前トレーニング プログラムを開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



