
背景紹介
マルチデバイス、複数人、複数ノイズのシナリオなど、さまざまな複雑な音声およびビデオ通信シナリオに対処するために、ストリーミングメディアコミュニケーション技術は徐々に人々の生活の一部となり、なくてはならない技術となっています。より良い主観的体験を実現し、ユーザーが明瞭かつ真に聞こえるようにするために、ストリーミング オーディオ テクノロジー ソリューションは、従来の機械学習と AI ベースの音声強化ソリューションを組み合わせ、ディープ ニューラル ネットワーク テクノロジー ソリューションを使用して音声ノイズの低減とエコー キャンセルを実現します。リアルタイム通信における音声品質を保護するために、干渉音声の除去やオーディオのエンコードとデコードなどを行います。
Interspeech は、音声信号処理研究分野の主力国際会議として、音響分野における最先端の研究の方向性を常に代表してきました。Interspeech 2023 には、音声信号の音声強化に関する多数の記事が含まれています。 volcanoengine ストリーミング オーディオ チームからの音声強調、AI ベースのエンコードとデコード #、エコーなど、合計 4 件の研究論文がカンファレンスに採択されました。キャンセル、および教師なし適応音声強調。
教師なし適応音声強化の分野では、ByteDance と NPU の共同チームが今年の CHiME (マルチソース環境におけるコンピュータ聴覚) チャレンジで教師なしドメイン適応会話音声のサブタスクを成功裏に完了したことは言及する価値があります。強化 (会話音声強化のための教師なしドメイン適応、UDASE) が優勝しました (https://www.chimechallenge.org/current/task2/results)。 CHiME Challengeは、フランスのコンピュータ科学オートメーション研究所、英国のシェフィールド大学、米国の三菱電子研究所などの著名な研究機関によって2011年に開始された重要な国際コンテストです。音声研究分野における遠隔の問題に挑戦するこのイベントは、今年で7回目となります。これまでの CHiME コンテストの参加チームには、英国のケンブリッジ大学、米国のカーネギー メロン大学、ジョンズ ホプキンス大学、日本の NTT、日立研究院、その他の国際的に有名な大学や研究機関、清華大学、中国科学院大学、中国科学院音響研究所、NPU、iFlytekなどの国内トップクラスの大学や研究機関。
この記事では、これら 4 つの論文によって解決されたシナリオの中核問題と技術的解決策を紹介します。
AI エンコーダ、エコー キャンセル、教師なし適応型音声強化に基づく音声強化における Volcano Engine ストリーミング オーディオ チームの進捗状況を共有します。現場で考え、実践する。
学習可能なくし型フィルタに基づく軽量音声高調波強調手法
論文アドレス: https://www.isca-speech.org/archive/interspeech_2023/ le23_interspeech.html
背景
リアルタイム オーディオおよびビデオ通信シナリオにおける音声強調は、遅延とコンピューティング リソースによって制限されるため、通常、フィルター バンクに基づく入力機能を使用します。 Mel や ERB などのフィルター バンクを通じて、元のスペクトルは低次元のサブバンドに圧縮されます。サブバンド ドメインでは、深層学習ベースの音声強調モデルの出力は、ターゲット音声エネルギーの割合を表すサブバンドの音声ゲインです。ただし、圧縮されたサブバンド領域で強化されたオーディオは、スペクトルの詳細が失われるためぼやけており、多くの場合、高調波を強化するための後処理が必要です。 RNNoise と PercepNet は高調波を強化するためにコム フィルターを使用しますが、基本周波数推定とコム フィルターのゲイン計算とモデルのデカップリングのため、エンドツーエンドで最適化することはできません。DeepFilterNet は時間周波数ドメイン フィルターを使用して高調波間ノイズを抑制します。ただし、音声の基本周波数情報を明示的に利用するわけではありません。上記の問題に対処するために、研究チームは、基本周波数推定とコムフィルタリングを組み合わせ、エンドツーエンドでコムフィルタのゲインを最適化できる学習可能なコムフィルタに基づく音声高調波強調手法を提案しました。実験により、この方法は既存の方法と同様の計算量でより優れた高調波強調を実現できることが示されています。
モデル フレームワーク構造
基本周波数推定器 (F0 推定器)
基本周波数推定の困難さを軽減し、リンク全体をエンドツーエンドで実行できるようにするためターゲットの基本周波数範囲は N 個の離散基本周波数に離散化され、分類器を使用して推定されます。非有声フレームを表すために 1 次元が追加され、最終的なモデル出力は N 個の 1 次元確率になります。 CREPE と一致して、チームはトレーニング ターゲットとしてガウス平滑特徴を使用し、損失関数としてバイナリ クロス エントロピーを使用します。コム フィルター
上記の個別の基本周波数ごとに、チームは PercepNet に似た FIR フィルターをコム フィルターに使用し、変調されたパルス列として表現できます。
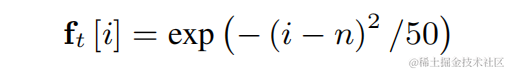
2 次元畳み込み層 (Conv2D) を使用して、トレーニング中にすべての離散基本周波数のフィルタリング結果を同時に計算します。2 次元畳み込みの重みは、下図の行列として表現できます。行列には N があります。 1 次元であり、各次元は上記のフィルターを使用して初期化されます。
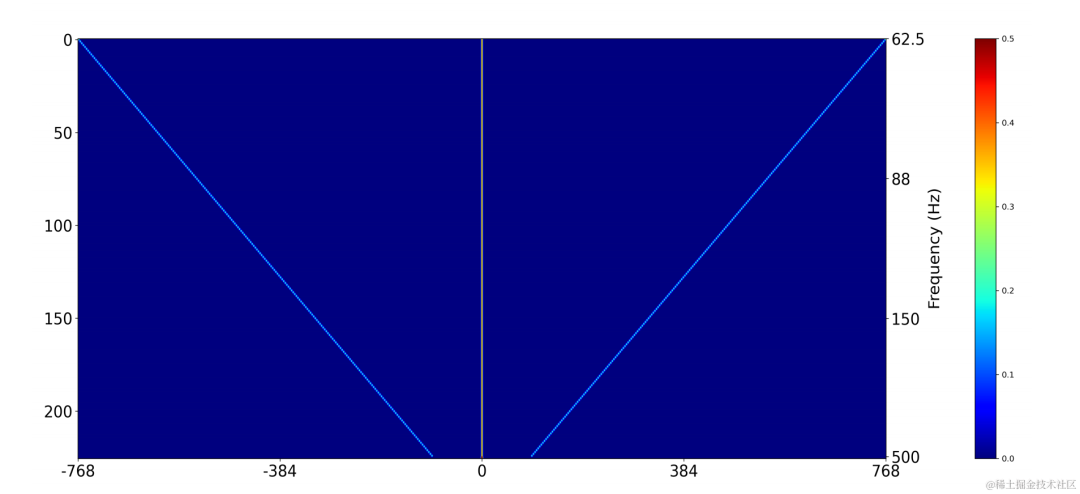
各フレームの基本周波数に対応するフィルター結果は、ターゲット基本周波数と 2 次元畳み込みの出力:

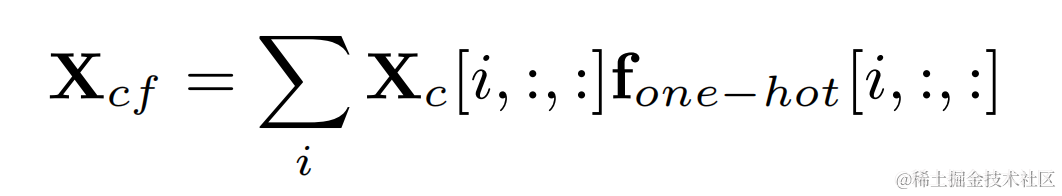
高調波強化オーディオは重み付けされて元のオーディオに追加され、サブ周波数で乗算されます。最終出力を取得するためのバンド ゲイン:
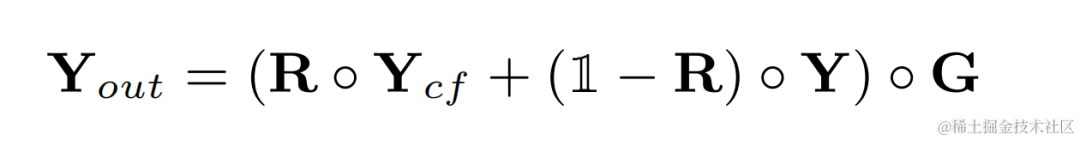
推論中、各フレームは 1 つの基本周波数のフィルター結果を計算するだけでよいため、この方法の計算コストは低くなります。 。
モデル構造
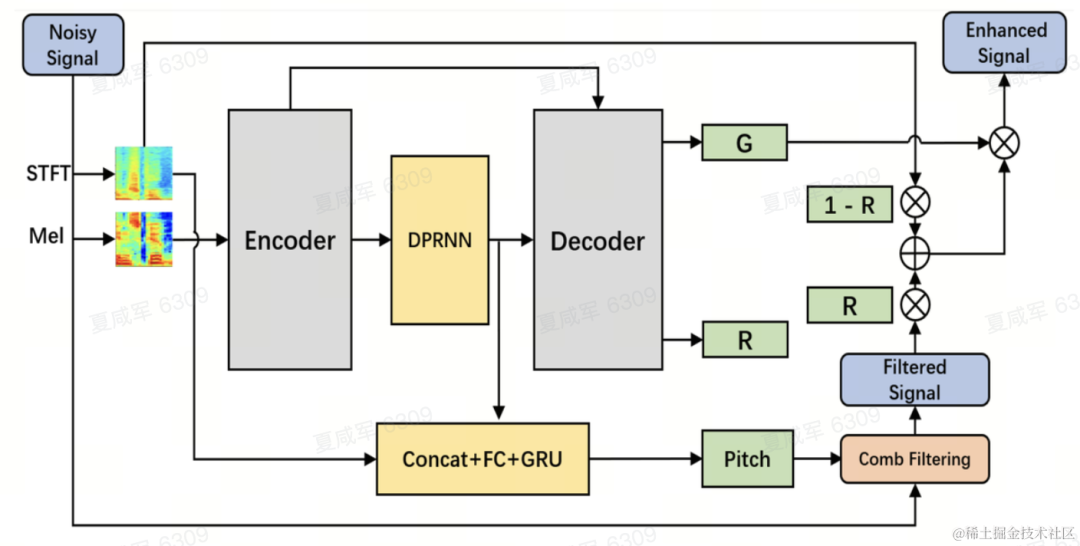
チームは、音声強調モデルのバックボーンとしてデュアルパス畳み込み再帰ネットワーク (DPCRN) を使用し、基本周波数推定器を追加しました。エンコーダとデコーダは深さ分離可能な畳み込みを使用して対称構造を形成し、デコーダにはサブバンド ゲイン G と重み付け係数 R をそれぞれ出力する 2 つの並列ブランチがあります。基本周波数推定器への入力は、DPRNN モジュールの出力と線形スペクトルです。このモデルの計算量は約300M MACであり、そのうちコムフィルタ計算量は約0.53M MACである。
モデル トレーニング
実験では、VCTK-DEMAND および DNS4 チャレンジ データセットがトレーニングに使用され、音声強調の損失関数と基本周波数推定がマルチタスク学習に使用されました。
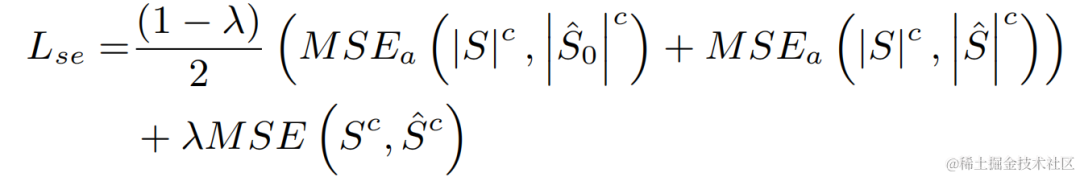
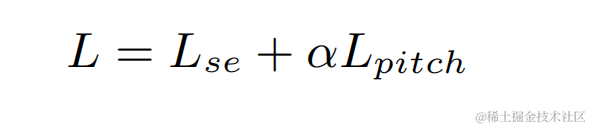
実験結果
ストリーミング オーディオ チームは、提案された学習可能なコム フィルタリング モデルと、PercepNet および DeepFilterNet を使用したコム フィルタリングを組み合わせました。フィルタリング アルゴリズム モデルは次のとおりです。これらはそれぞれ DPCRN-CF、DPCRN-PN、DPCRN-DF と呼ばれます。 VCTK テスト セットでは、この記事で提案された方法は既存の方法よりも優れていることがわかります。
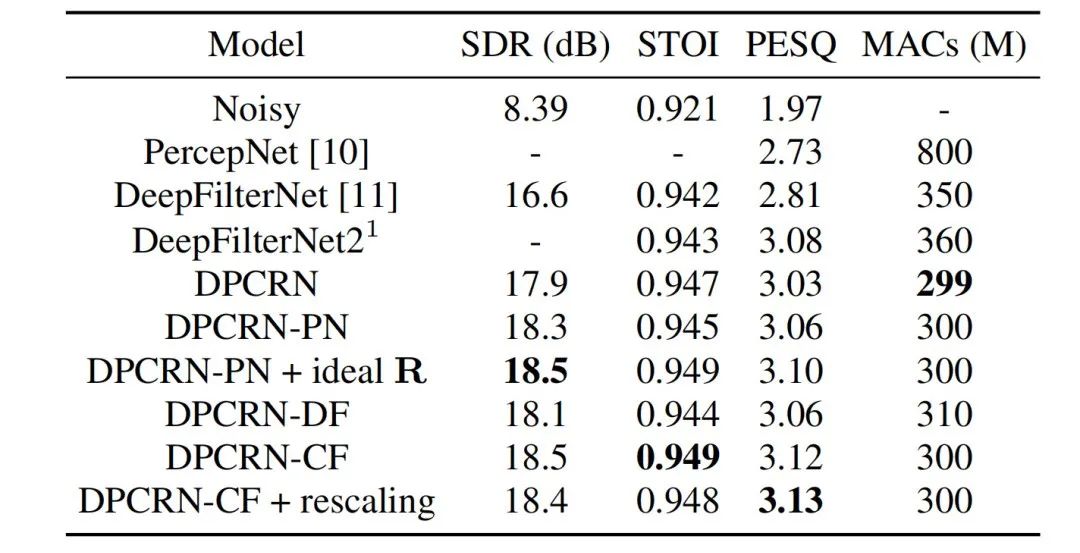
同時に、チームは基本周波数推定と学習可能なフィルターに関するアブレーション実験を実施しました。実験結果は、信号処理ベースの基本周波数推定アルゴリズムとフィルター重みを使用するよりも、エンドツーエンド学習の方が良い結果を生み出すことを示しています。
Intra-BRNN および GB-RVQ に基づくエンドツーエンドのニューラル ネットワーク オーディオ エンコーダ
論文アドレス: https://www.isca- speech .org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
背景
近年、低ビットレートの音声コーディング タスクに多くのニューラル ネットワーク モデルが使用されていますが、一部のニューラル ネットワーク モデルはエンドツー-end モデルは失敗しました。フレーム内関連情報を最大限に活用し、導入された量子化器は量子化誤差が大きく、エンコード後の音質が低下します。エンドツーエンドのニューラル ネットワーク オーディオ エンコーダーの品質を向上させるために、ストリーミング オーディオ チームはエンドツーエンドのニューラル音声コーデック、つまり CBRC (Convolutional and Bidirectional Recurrent neural Codec) を提案しました。 CBRC は、1D-CNN (1 次元畳み込み) と Intra-BRNN (フレーム内双方向リカレント ニューラル ネットワーク) のインターリーブ構造を使用して、フレーム内相関をより効果的に利用します。さらに、チームは CBRC のグループごとのビーム探索残差ベクトル量子化器 (GB-RVQ) を使用して、量子化ノイズを削減します。 CBRC は、システム遅延を追加することなく、20 ミリ秒のフレーム長で 16 kHz オーディオをエンコードし、リアルタイム通信シナリオに適しています。実験結果は、ビットレート 3kbps の CBRC エンコーディングの音声品質が、12kbps の Opus の音声品質よりも優れていることを示しています。
モデルフレームワーク構造
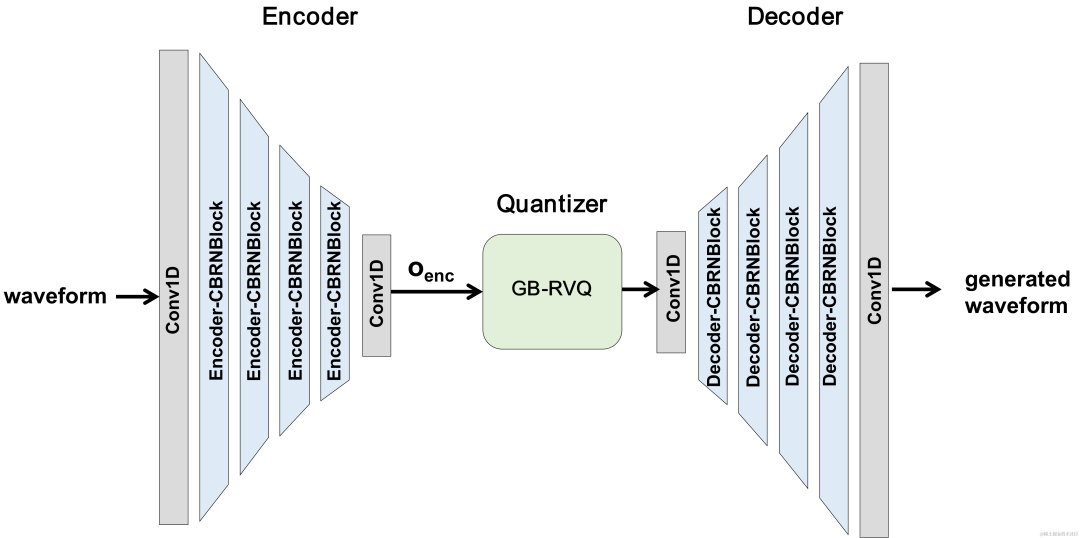
CBRC 全体構造
エンコーダとデコーダのネットワーク構造
エンコーダは、オーディオ特徴を抽出するために 4 つのカスケード CBRNBlock を使用します。各 CBRNBlock は、特徴を抽出するための 3 つの ResidualUnits と、ダウンサンプリング レートを制御する 1 次元の畳み込みで構成されます。エンコーダー内の特徴がダウンサンプリングされるたびに、特徴チャンネルの数は 2 倍になります。 ResidualUnit は、残差畳み込みモジュールと残差双方向リカレント ネットワークで構成されます。このネットワークでは、畳み込み層は因果畳み込みを使用しますが、Intra-BRNN の双方向 GRU 構造は 20 ミリ秒のフレーム内オーディオ機能のみを処理します。 Decoder ネットワークは Encoder のミラー構造であり、アップサンプリングに 1 次元の転置畳み込みを使用します。 1D-CNN とイントラ BRNN のインターリーブ構造により、エンコーダとデコーダは追加の遅延を発生させることなく 20 ミリ秒のオーディオフレーム内相関を最大限に活用できます。
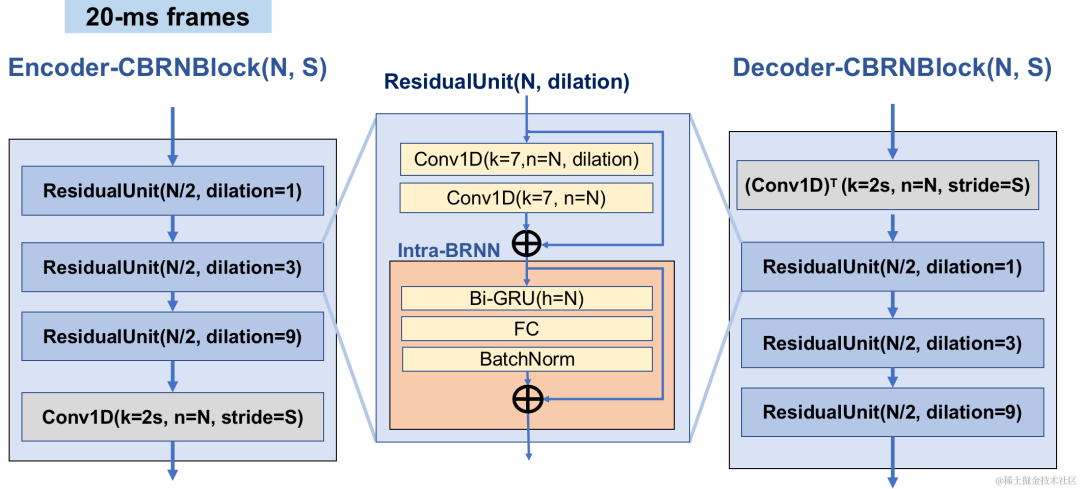
CBRNBlock 構造
グループおよびビーム検索残差ベクトル量子化器 GB-RVQ
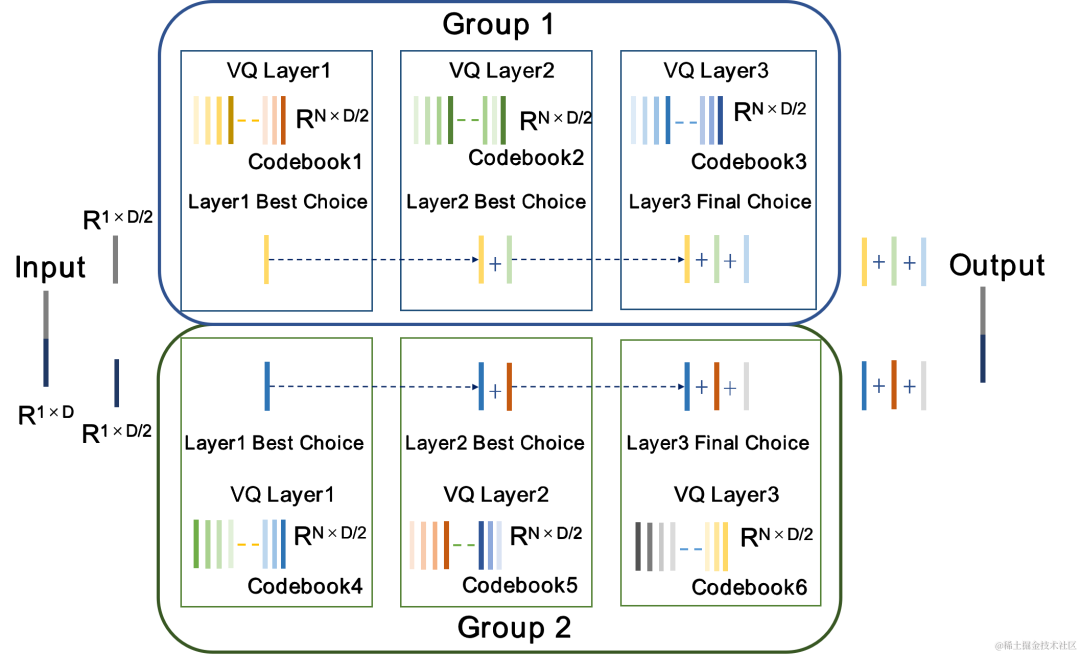
CBRC は残差を使用します。ベクトル量子化器 (RVQ) は、エンコード ネットワークの出力特徴を量子化して、指定されたビット レートに圧縮します。 RVQ は、多層ベクトル量子化器 (VQ) カスケードを使用して特徴を圧縮します。VQ の各層は、VQ の前の層の量子化残差を量子化するため、同じビットでの VQ の単一層のコードブック パラメータの量を大幅に削減できます。レート。研究チームは、CBRC における 2 つのより優れた量子化器構造、すなわちグループごとの RVQ とビーム探索残差ベクトル量子化器 (ビーム探索 RVQ) を提案しました。
| #グループ残差ベクトル量子化器グループごとの RVQ
| ビームサーチ残差ベクトル量子化器ビームサーチ RVQ
|
| 
|
##グループごとの RVQ はエンコーダー出力をグループ化し、グループ化された RVQ を使用してグループ化された特徴を個別に定量化し、グループ化された量子化された出力を入力デコーダーに接続します。グループごとの RVQ はグループ量子化を使用して、コードブック パラメーターと量子化器の計算の複雑さを軽減すると同時に、CBRC エンドツーエンド トレーニングの難しさを軽減し、CBRC エンコードされたオーディオの品質を向上させます。
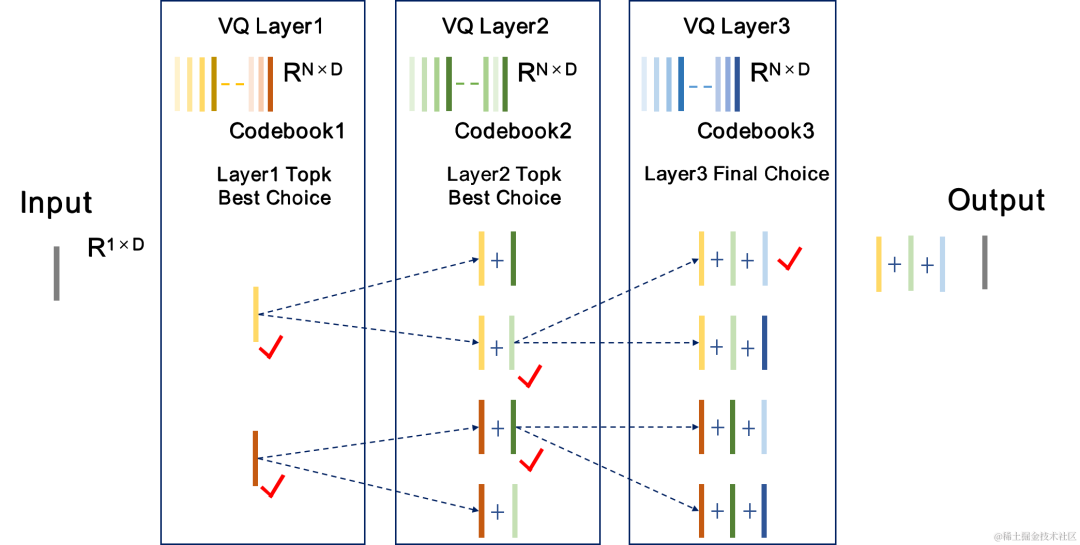
チームは、ニューラル オーディオ エンコーダーのエンドツーエンド トレーニングにビーム検索 RVQ を導入し、ビーム検索アルゴリズムを使用して RVQ の量子化パス誤差が最小となるコードブックの組み合わせを選択し、量子化器の量子化誤差。元の RVQ アルゴリズムは、VQ 量子化の各層で誤差が最小のコードブックを出力として選択しますが、VQ 量子化の各層に最適なコードブックの組み合わせが必ずしも全体的に最適なコードブックの組み合わせであるとは限りません。チームはビームサーチ RVQ を使用して、最小量子化パス誤差基準に基づいて VQ の各層に k 個の最適な量子化パスを保持し、より大きな量子化探索空間でより適切なコードブックの組み合わせを選択できるようにし、量子化誤差を削減します。
|
|
##ビームサーチ RVQ アルゴリズムの簡単なプロセス: |
1. 各層 VQ が前層候補を入力します。 VQの量子化パスが得られます。
#2. 候補量子化パスから量子化パス誤差が最小の量子化パスを現在の VQ レイヤ出力として選択します。
#3. VQ の最後の層で量子化パス エラーが最小のパスを量子化器の出力として選択します。
|

|
#モデルトレーニング
実験では、LibriTTSデータセット内の245時間の16kHzの音声がトレーニングに使用され、音声の振幅にランダムゲインが乗算されてモデルに入力されました。トレーニングにおける損失関数は、スペクトル再構成マルチスケール損失、識別子敵対的損失と特徴損失、VQ 量子化損失、および知覚損失で構成されます。
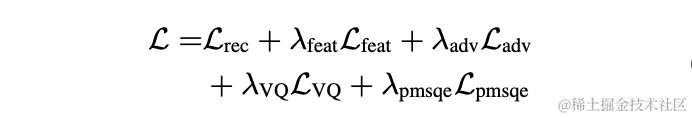
実験結果
主観的スコアと客観的スコア
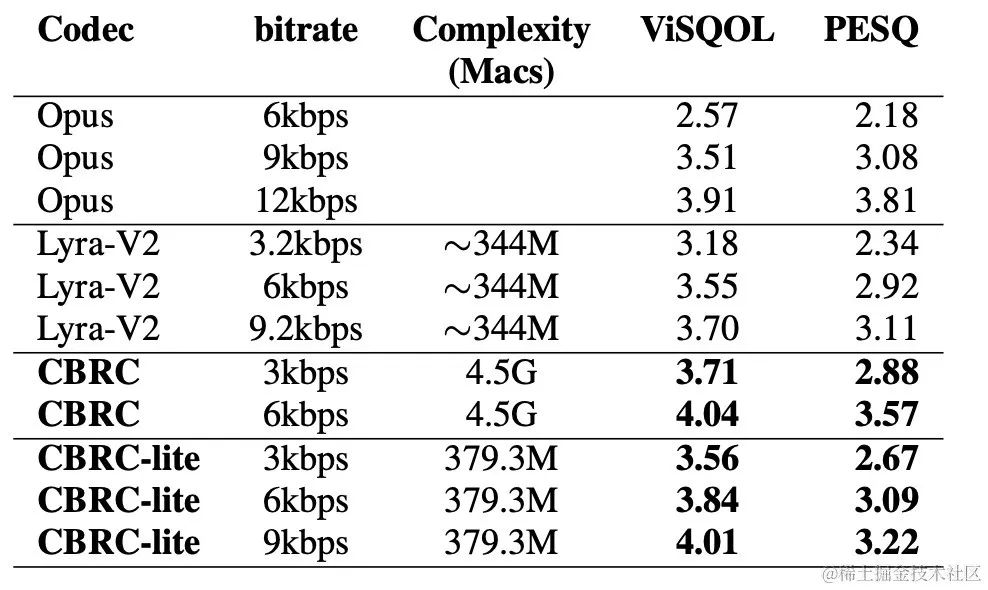
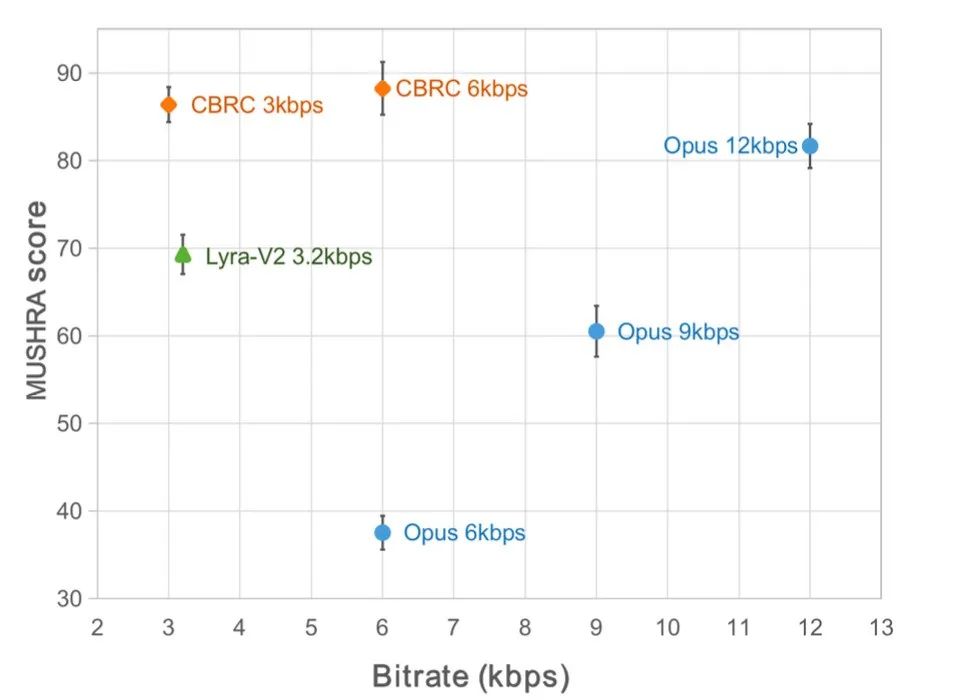
CBRC エンコードされた音声品質を評価するために、10 個の多言語音声比較セットが構築されました。 . この比較セットは、他のオーディオ コーデックと比較します。計算の複雑さの影響を軽減するために、チームは軽量の CBRC-lite を設計しました。その計算の複雑さは Lyra-V2 よりわずかに高くなります。主観聴取比較の結果から、CBRC の音声品質は 3kbps で Opus の 12kbps を上回り、3.2kbps で Lyra-V2 を上回っており、提案手法の有効性が示されている。 CBRC エンコードされたオーディオ サンプルは、https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb で提供されます。
| ##客観的なスコア
|
主観的なリスニング体験のスコア
|
|
|
アブレーション実験
チームは、Intra-BRNN、グループワイズ RVQ、およびビームサーチ RVQ のアブレーション実験を設計しました。実験結果は、エンコーダとデコーダの両方で Intra-BRNN を使用すると、音声品質が大幅に向上することを示しています。さらに、チームは RVQ でのコードブックの使用頻度をカウントし、エントロピー復号を計算して、さまざまなネットワーク構造下でのコードブックの使用率を比較しました。完全な畳み込み構造と比較して、Intra-BRNN を使用する CBRC では、潜在的なエンコード ビット レートが 4.94kbps から 5.13kbps に増加します。同様に、CBRC でグループワイズ RVQ とビームサーチ RVQ を使用すると、エンコードされた音声の品質を大幅に向上させることができ、ニューラル ネットワーク自体の計算の複雑さと比較すると、GB-RVQ によってもたらされる複雑さの増加はほとんど無視できます。


#サンプルオーディオ
オリジナルオーディオ
##arctic_a0023_16k、Bytedance 技術チーム、5 秒
es01_l_16k、Bytedance 技術チーム、10 秒
CBRC 3kbps
##arctic_a0023_16k_CBRC_3kbps、ByteDance 技術チーム、5 秒
es01_l_16k_CBRC_3kbps 、ByteDance 技術チーム、10 秒 ##CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps
、Bytedance 技術チーム、5 秒 es01_l_16k_CBRC_lite_3kbps
、Bytedance 技術チーム、10 秒 2 段階に基づくエコー キャンセル方法プログレッシブ ニューラル ネットワーク論文アドレス: https://www.isca-speech.org/archive/pdfs/interspeech_2023/chen23e_interspeech.pdf
背景
ハンズフリーで通信システムでは、音響エコーは迷惑な背景妨害です。エコーは、遠端の信号がスピーカーから再生され、近端のマイクで録音されるときに発生します。音響エコー キャンセル (AEC) は、マイクが拾う不要なエコーを抑制するように設計されています。現実の世界には、リアルタイム通信、スマート教室、車両のハンズフリー システムなど、エコー キャンセルを必要とするアプリケーションが数多くあります。
最近、深層学習 (DL) 手法を採用したデータ駆動型 AEC モデルが、より堅牢で強力であることが証明されています。これらの方法では、AEC を教師あり学習問題として定式化し、入力信号と近位ターゲット信号の間のマッピング関数がディープ ニューラル ネットワーク (DNN) を通じて学習されます。ただし、実際のエコー パスは非常に複雑であるため、DNN のモデリング機能に対してより高い要件が課されます。ネットワークのモデリング負担を軽減するために、既存の DL ベースの AEC 方式のほとんどは、フロントエンド線形エコー キャンセル (LAEC) モジュールを採用して、エコーの線形成分の大部分を抑制します。ただし、LAEC モジュールには 2 つの欠点があります。1) 不適切な LAEC により近端音声に歪みが生じる可能性がある、2) LAEC 収束プロセスにより線形エコー抑制性能が不安定になる。 LAEC は自己最適化を行うため、LAEC の欠点により、後続のニューラル ネットワークに追加の学習負担がかかります。
LAEC の影響を回避し、より良好な近端音声品質を維持するために、この文書では、エンドツーエンド DL に基づく新しい 2 段階処理モデルを検討し、粗粒度 (粗い) な処理モデルを提案します。エコー キャンセル タスクには、ステージとファイングレイン (ファインステージ) で構成される 2 ステージ カスケード ニューラル ネットワーク (TSPNN) が使用されます。多くの実験結果は、提案された 2 段階のエコー キャンセル方法が他の主流の方法よりも優れたパフォーマンスを達成できることを示しています。
モデル フレームワーク構造
次の図に示すように、TSPNN は主に 3 つの部分で構成されます。遅延補償モジュール (TDC)、粗粒度処理モジュール (粗段階)、および細粒度処理モジュールです。粒度の高い処理モジュール (ファインステージ)。 TDC は、入力遠端基準信号 (ref) と近端マイク信号 (mic) を調整する役割を果たします。これは、後続のモデルの収束に有益です。粗段階はマイクからほとんどのエコーとノイズを除去する役割を果たし、後続の微段階段階でのモデル学習の負担を大幅に軽減します。同時に、粗いステージでは、マルチタスク学習用の音声アクティビティ検出 (VAD) タスクを組み合わせて、近端音声に対するモデルの認識を強化し、近端音声へのダメージを軽減します。微調整ステージは、残留エコーとノイズをさらに除去し、近端のターゲット信号をより適切に再構築するために隣接周波数点の情報を結合する役割を果たします。
各ステージのモデルを個別に最適化することによって引き起こされる次善の解決策を回避するために、この記事では、カスケード最適化の形式を使用して粗ステージと微ステージを同時に最適化し、同時に粗ステージの制約を緩和して回避します。ニアエンドスピーチはダメージを与えます。さらに、モデルが近端音声を知覚できるようにするために、本発明はマルチタスク学習用のVADタスクを導入し、VADの損失を損失関数に追加する。最終的な損失関数は次のとおりです:
ここで はターゲット近端信号の複素スペクトル、粗い段階と細かい段階でそれぞれ推定された近端信号の複素スペクトルを表します。それぞれ coarse-stage によって推定された近端信号の複素スペクトル 端音声アクティブ状態、近端音声アクティビティ検出ラベル; は制御スカラーであり、主に音声のさまざまな段階への注意度を調整するために使用されます。トレーニング段階。本発明は、#####を制限して粗動ステージの制約を緩和し、粗動ステージの近位端への損傷を効果的に回避する。 実験結果
実験データ
Volcano Engine ストリーミング オーディオ チームによって提案された 2 段階エコー キャンセル システムは、他の方法とも比較されました。実験結果は、次のことを示しています。提案されたシステムは、他の主流の方法よりも優れた結果を達成できます。
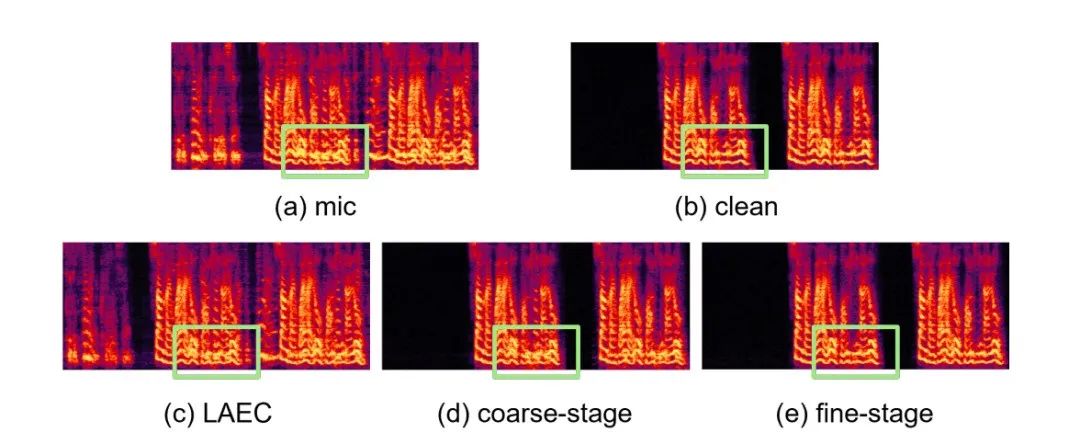
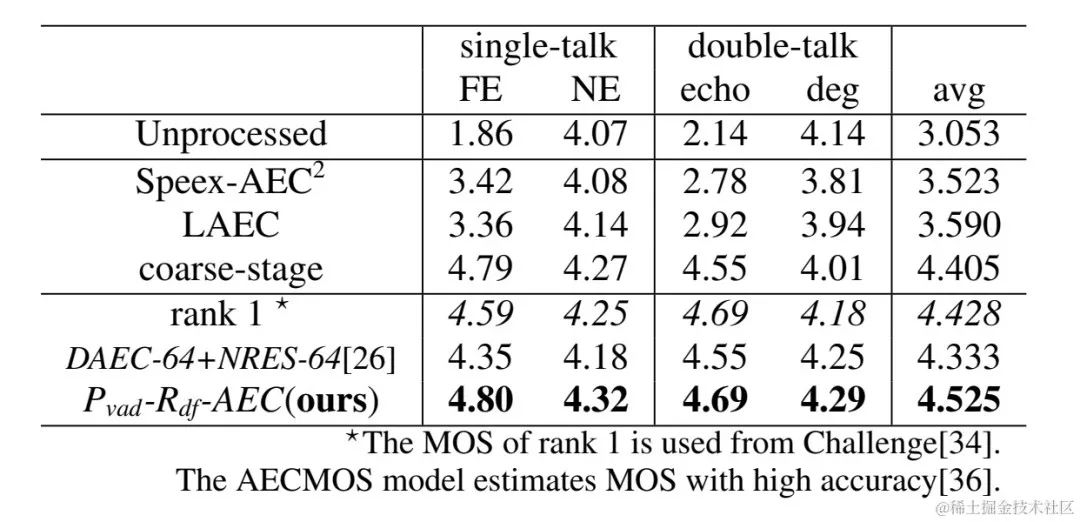 具体例
具体例
実験結果 Githubリンク: https://github.com/enhancer12/TSPNN
- ダブルレクチャーシーンエフェクトのパフォーマンス:
-
 CHiME-7 Unsupervised Domain Adaptive Speech Enhancement (UDASE) Challenge Champion Solution
CHiME-7 Unsupervised Domain Adaptive Speech Enhancement (UDASE) Challenge Champion Solution
論文アドレス: https://www .chimechallenge.org/current/task2/documents/Zhang_NB.pdf
背景:
近年、ニューラルネットワークやデータ駆動型ディープラーニング技術の発展に伴い、音声強調技術の研究が進んでいます。は徐々に深層学習に基づく方法に目を向けており、深層ニューラルネットワークに基づく音声強調モデルがますます提案されています。ただし、これらのモデルのほとんどは教師あり学習に基づいており、トレーニングには大量のペア データが必要です。ただし、実際のシナリオでは、ノイズの多いシーンの音声と、ペアになったクリーンな音声タグを同時に干渉なくキャプチャすることは不可能です。通常、データ シミュレーションを使用して、クリーンな音声とさまざまなノイズを別々に収集し、特定の信号に従ってそれらを結合します。対ノイズ比が混合すると、ノイズの多い周波数が生成されます。これにより、トレーニング シナリオと実際のアプリケーション シナリオの間に不一致が生じ、実際のアプリケーションでのモデルのパフォーマンスが低下します。
上記のドメイン不一致の問題をより適切に解決するために、実際のシーンで大量のラベルなしデータを使用して、教師なしおよび自己教師ありの音声強調技術が提案されています。 CHiME Challenge Track 2 は、ラベルなしデータを使用して、人工的に生成されたラベル付きデータでトレーニングされた音声強調モデルの、トレーニング データと実際のアプリケーション シナリオの不一致によるパフォーマンス低下の問題を克服することを目的としています。ドメインのデータとセット外のラベル付きデータは、ターゲット ドメインの拡張結果を向上させるために使用されます。
モデル フレームワークの構造:
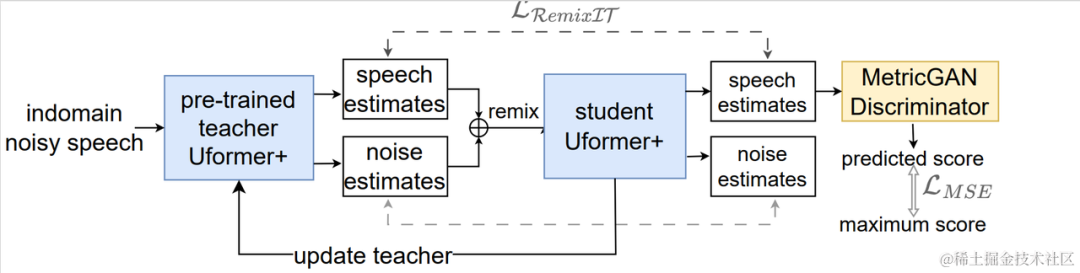 教師なしドメイン適応型音声強調システムのフローチャート
教師なしドメイン適応型音声強調システムのフローチャート
上図に示すように、提案されたフレームワークは次のとおりです。教師と生徒のネットワーク。まず、ドメイン内のデータに対して音声アクティビティ検出、UNA-GAN、シミュレートされた室内インパルス応答、動的ノイズなどのテクノロジーを使用して、ターゲット ドメインに最も近いラベル付きデータ セットを生成し、教師ノイズ低減ネットワーク Uformer を事前トレーニングします。ドメイン外のラベル付きデータセット。次に、ドメイン内のラベルなしデータに対してこのフレームワークを利用して学生ネットワークが更新されます。つまり、事前トレーニングされた教師ネットワークを使用して、ノイズの多い音声からきれいな音声とノイズを擬似ラベルとして推定し、シャッフルされます。擬似ラベルを使用した学生ネットワークの教師ありトレーニング。学生ネットワークによって生成されたクリーンな音声品質スコアは、事前トレーニング済みの MetricGAN 弁別器を使用して推定され、最高スコアを使用して損失が計算され、学生ネットワークがより高品質のクリーンな音声を生成するように導きます。各トレーニング ステップの後、より高品質の教師あり学習擬似ラベルなどを取得するために、生徒ネットワークのパラメーターが特定の重みで教師ネットワークに更新されます。
Ufomer Network
Uformer は、Uformer ネットワークに基づいて MetricGAN を追加することで改善されています。 Uformer は、Unet 構造に基づく複素実数デュアルパス コンバータ ネットワークであり、振幅スペクトル ブランチと複素スペクトル ブランチの 2 つの並列ブランチを持ち、ネットワーク構造は次の図に示されています。振幅ブランチはメインのノイズ抑制機能に使用され、ほとんどのノイズを効果的に抑制できます。複雑なブランチは、スペクトルの詳細や位相偏差などの損失を補償する補助として機能します。 MetricGAN の主なアイデアは、ニューラル ネットワークを使用して微分不可能な音声品質評価指標をシミュレートし、ネットワーク トレーニングで使用して、トレーニング中と実際のアプリケーション中に一貫性のない評価指標によって引き起こされるエラーを削減できるようにすることです。ここでチームは、MetricGAN ネットワーク推定のターゲットとして知覚音声品質評価 (PESQ) を使用します。
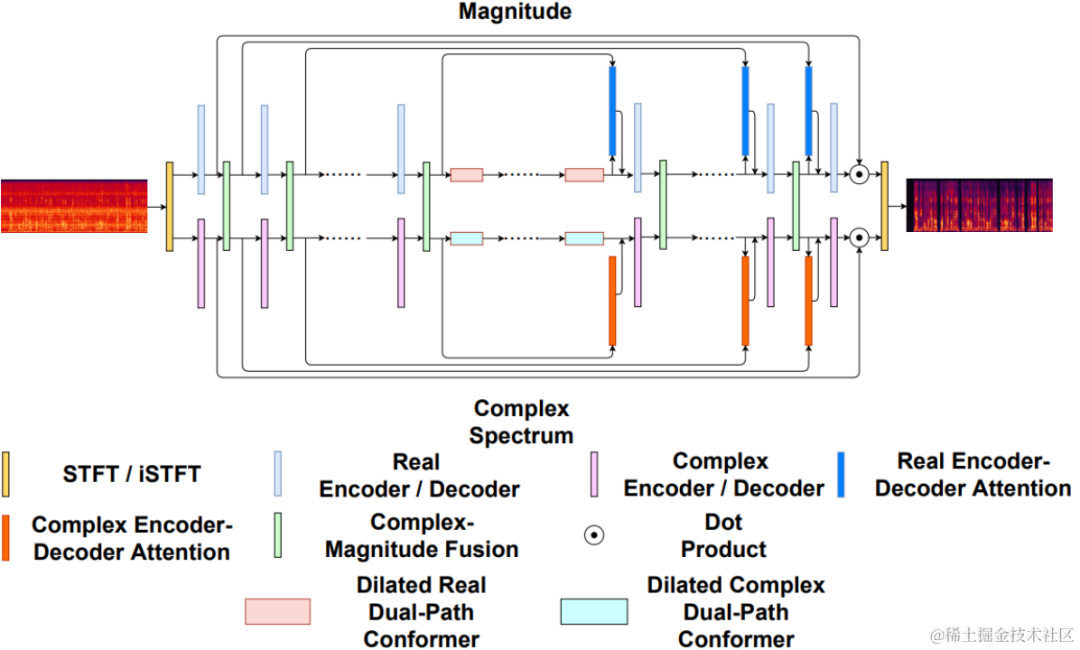
以前のネットワーク構造図
RemixIT-G フレームワーク
RemixIT-G は、最初にラベル付きデータで事前トレーニングされた教師と生徒のネットワークです。ドメイン教師 Uformer モデルの外では、この事前トレーニング済み教師モデルを使用して、ドメイン内のノイズの多い音声をデコードし、騒音と音声を推定します。次に、推定された騒音と音声の順序が同じバッチ内でスクランブルされ、騒音と音声がシャッフルされた順序でノイズの多い音声にリミックスされ、これが学生ネットワークをトレーニングするための入力として使用されます。教師ネットワークによって擬似ラベルとして推定された騒音と音声。学生ネットワークは、リミックスされたノイズのある音声をデコードし、ノイズと音声を推定し、擬似ラベルを使用して損失を計算し、学生ネットワーク パラメータを更新します。学生ネットワークによって推定された音声は、PESQ を予測するために事前にトレーニングされた MetricGAN 弁別器に入力され、PESQ の最大値を使用して損失が計算されて、学生ネットワーク パラメーターが更新されます。
すべてのトレーニング データが 1 ラウンドの反復を完了した後、教師ネットワークのパラメーターは次の式に従って更新されます。ここで、 は教師ネットワークの K 回目のトレーニング ラウンドのパラメーター、および は、学生ネットワークの K 回目のパラメータです。つまり、生徒ネットワークのパラメータが一定の重みを持って教師ネットワークに追加されます。
データ拡張手法 UNA-GAN
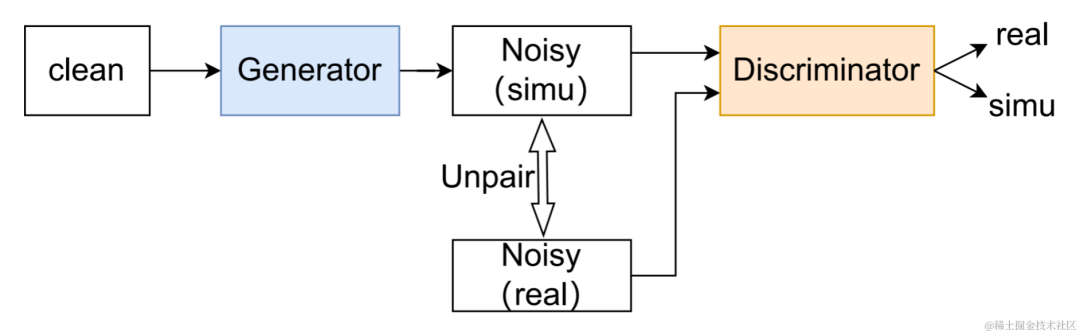
UNA-GAN 構造図
教師なしノイズ適応データnetwork UNA-GAN は、敵対的生成ネットワークに基づいたノイズの多いオーディオ生成モデルです。その目的は、独立したノイズ データが取得できない場合に、ドメイン内のノイズの多いオーディオのみを使用して、クリーンな音声をドメイン内ノイズを含むノイズの多いオーディオに直接変換することです。ジェネレーターはクリーンな音声を入力し、シミュレートされたノイズの多いオーディオを出力します。弁別器は、生成されたノイズのあるオーディオまたはドメイン内の実際のノイズのあるオーディオを入力し、入力されたオーディオが実際のシーンからのものであるか、シミュレーションによって生成されたものであるかを判断します。識別器は主に背景雑音の分布に基づいて音源を識別しますが、この過程で人間の音声は無効な情報として扱われます。上記の敵対的トレーニング プロセスを実行することにより、ジェネレーターは、ディスクリミネーターを混乱させるために入力クリーン オーディオにドメイン内ノイズを直接追加しようとし、ディスクリミネーターはノイズのあるオーディオのソースを区別しようとします。ジェネレーターが過度のノイズを追加して、入力オーディオ内の人間の音声を覆い隠すことを避けるために、対照学習が使用されます。生成されたノイズの多い音声と入力されたきれいな音声に対応する位置で 256 ブロックをサンプリングします。同じ位置にあるブロックのペアは正の例とみなされ、異なる位置にあるブロックのペアは負の例とみなされます。正の例と負の例を使用してクロスエントロピー損失を計算します。
実験結果
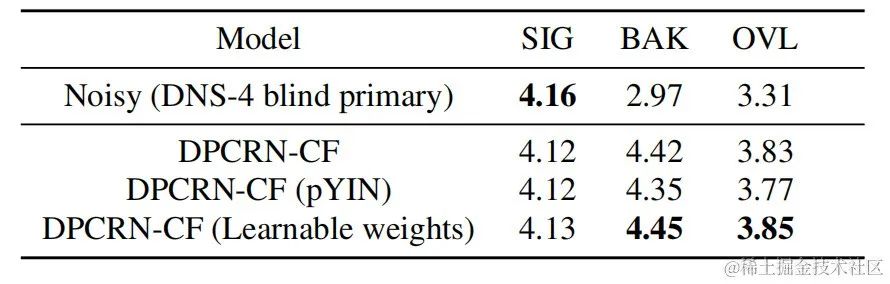
結果は、提案された Uformer がベースライン Sudo rm-rf よりも強力なパフォーマンスを持ち、データ拡張手法 UNA-GAN がノイズの多い周波数を生成する機能も備えていることを示しています。ドメイン。ドメイン アダプテーション フレームワーク RemixIT ベースラインは、SI-SDR で大幅な改善を達成しましたが、DNS-MOS ではパフォーマンスが劣っています。チームが提案した改善 RemixIT-G は、両方の指標で同時に効果的な改善を達成し、競争ブラインドテストセットで最高の主観的リスニング MOS スコアを達成しました。最終的なリスニングテストの結果を次の図に示します。
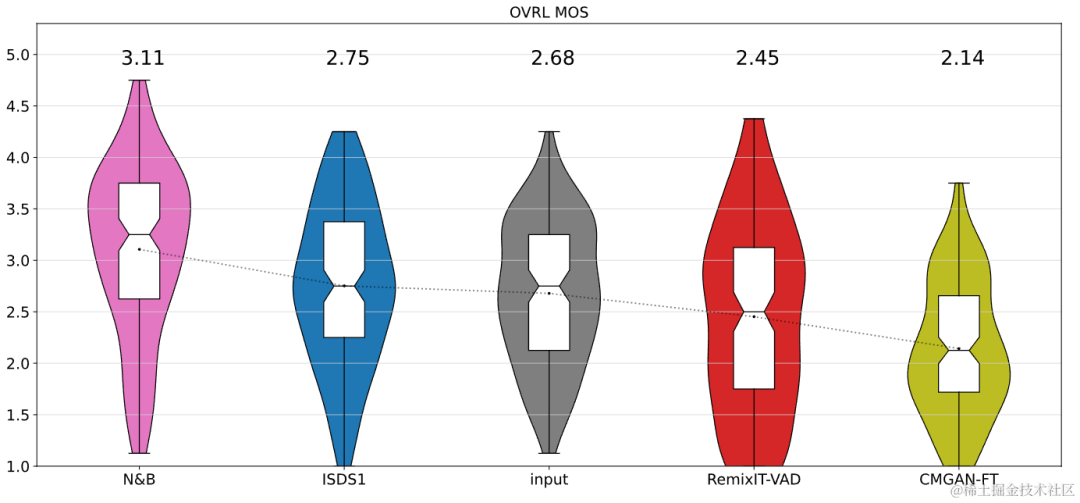
概要と展望
上記では、話者固有のノイズ リダクション、AI エンコーダー、エコー キャンセルなどに基づく Volcano Engine ストリーミング オーディオ チームのディープ ラーニングを紹介します。教師なし適応型音声強調の方向でソリューションと効果が作られてきましたが、将来のシナリオでは、さまざまな端末上で軽量かつ複雑さの低いモデルを展開して実行する方法や、マルチデバイス効果の堅牢性を実現する方法など、さまざまな方向で課題に直面しています。ストリーミング オーディオ チームの今後の研究の方向性の焦点にもなります。
以上がInterspeech 2023 | Volcano Engine ストリーミング オーディオ テクノロジー音声強化と AI オーディオ コーディングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



