


私たちは、ラージ言語モデル (LLM) によって推進される AI の新時代に突入しています。LLM は、カスタマー サービス、仮想アシスタント、コンテンツ作成、プログラミング支援などのさまざまなアプリケーションでますます重要な役割を果たしています。
しかし、LLM の規模が拡大し続けるにつれて、大規模なモデルの実行に必要なリソースの消費も増加し、その実行速度がますます遅くなり、AI アプリケーション開発者に大きな課題をもたらしています。
この目的を達成するために、インテルは最近、BigDL-LLM[1] という大規模モデルのオープンソース ライブラリをリリースしました。これは、インテル ## の AI 開発者と研究者を支援します。 #® は、プラットフォーム上で大規模な言語モデルの最適化を加速し、インテル ® プラットフォーム上で大規模な言語モデルを使用するエクスペリエンスを向上させます。

[2] を示しています。 Intel® Xeon® Platinum 8468 プロセッサを搭載したサーバー上で実行されます。
® Xeon® Platinum 8468 プロセッサを搭載したサーバー上で 330 億パラメータのラージ言語を実行 実際の速度モデル (リアルタイム画面録画)
BigDL-LLM: Intel® CPU 統合ハードウェア アクセラレーション テクノロジ (AVX/VNNI/AMX など) と最新のソフトウェア最適化を活用することで、大規模な言語モデルを Intel® ## 上でより効率的な最適化を実現できます。 # プラットフォームを使用すると、より高速に実行できます。 BigDL-LLM の重要な機能は、Hugging Face Transformers API に基づくモデルの場合、コードを 1 行変更するだけでモデルを高速化できることです。理論的には、
# の実行をサポートできます。 ##anyTransformers モデル。Transformers API に精通している開発者にとって非常に使いやすいモデルです。 Transformers API に加えて、多くの人が LangChain を使用して大規模な言語モデル アプリケーションを開発しています。
この目的のために、BigDL-LLM は使いやすい LangChain 統合も提供します[3]
これにより、開発者は BigDL-LLM を簡単に使用して、新しいアプリケーションを開発したり、既存のアプリケーション ベースを移行したりできます。 Transformers API または LangChain API で。さらに、一般的な PyTorch の大規模言語モデル (Transformer または LangChain API を使用しないモデル) の場合、BigDL-LLM optimize_model API のワンクリック アクセラレーションを使用してパフォーマンスを向上させることもできます。詳細については、GitHub README[4]
および公式ドキュメント[5]を参照してください。 BigDL-LLM は、一般的に使用されるオープンソース LLM アクセラレーションの例も多数提供します (例: Transformers API[6]
を使用した例や LangChain API[7] 、およびチュートリアル (jupyter ノートブックのサポートを含む) [8]、開発者がすぐに使い始めるのを容易にする インストールと使用: シンプルなインストール プロセスと使いやすい API インターフェイス
BigDL-LLM のインストールは非常に便利です。次のコマンドを実行するだけです。pip install --pre --upgrade bigdl-llm[all]
#△
コードが完全に表示されない場合は、 Sliding のままにしてくださいBigDL-LLM を使用して大規模なモデルを高速化することも非常に簡単です (ここでは例として Transformers スタイル API のみが使用されています)。BigDL-LLM を使用するモデルを高速化する Transformer スタイル API は、モデルの読み込み部分のみを変更する必要があり、その後の使用プロセスはネイティブ Transformers と完全に一致します。
BigDL-LLM API を使用してモデルを読み込む方法は次のとおりです。 Transformers API とほぼ同じ - ユーザーは from_pretrained パラメータでインポートを変更するだけで済みます
load_in_4bit=True
と設定するだけで.BigDL-LLM が実行されますモデル読み込みプロセス中に 4 ビットの低精度量子化を行い、その後の推論プロセスで使用します。 さまざまなソフトウェアおよびハードウェア アクセラレーション テクノロジが最適化されています#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)ログイン後にコピー
△
# #コードが完全に表示されない場合は、左または右にスライドしてください 下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分: 以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程: 在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。 只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。 △若代码显示不全,请左右滑动 第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。 △若代码显示不全,请左右滑动 在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。 可以使用这个 API 来加载 Hugging Face Transformers 的任何模型 △若代码显示不全,请左右滑动 然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。 △若代码显示不全,请左右滑动 以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下: △若代码显示不全,请左右滑动 最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧! 黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作示例:快速实现一个基于大语言模型的语音助手应用
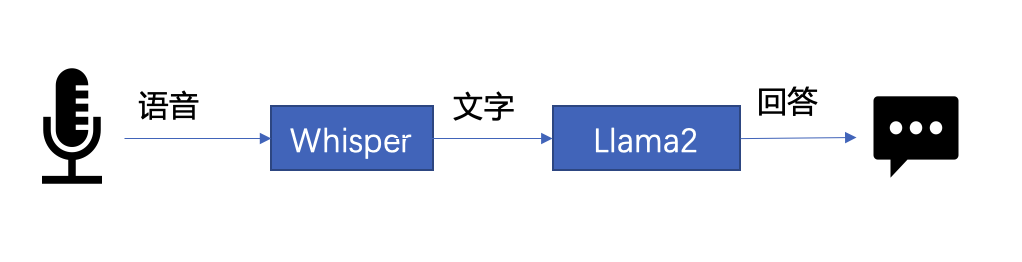
△图 1. 语音助手工作流程示意
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
ログイン後にコピーinput_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
ログイン後にコピーllm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)ログイン後にコピー# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
ログイン後にコピーresponse_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
ログイン後にコピー作者简介
以上がBigDL-LLM を使用して、数百億のパラメータ LLM 推論を瞬時に高速化しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



