


近年、MidjourneyやStable Diffusionに代表される人工知能画像生成ツールの台頭により、2D人工知能画像生成技術は欠かせないものとなっています。実際のプロジェクトでエンジニアが使用する補助ツールは、さまざまなビジネスシーンに適用され、ますます実用的な価値を生み出しています。同時に、メタバースの台頭により、多くの産業が大規模な 3D 仮想世界を構築する方向に向かっており、ゲーム、ロボット、建築、建築などの産業において、多様で高品質な 3D コンテンツの重要性がますます高まっています。そしてソーシャルプラットフォーム。ただし、3D アセットを手動で作成するには時間がかかり、特定の芸術的およびモデリングのスキルが必要です。主な課題の 1 つはスケールの問題です。3D マーケットプレイスには多数の 3D モデルが存在しますが、ゲームや映画ですべて異なって見えるキャラクターや建物のグループを作成するには、依然としてアーティストの多大な投資が必要です。時間。その結果、3D コンテンツの量、質、多様性を拡張できるコンテンツ作成ツールの必要性がますます明らかになってきています。
 #写真
#写真
2D 画像は明示的な 3D 形状よりも一般的であるため、監視に 2D 画像を使用することが可能です。パート 023D 生成モデルの概要コンテンツをわかりやすくするため作成プロセスを改善し、実用的なアプリケーションを可能にするジェネレーティブ 3D ネットワークは、高品質で多様な 3D アセットを作成できる活発な研究分野となっています。毎年、ICCV、NeurlPS、ICML およびその他のカンファレンスで、次のような最先端のモデルを含む多くの 3D 生成モデルが公開されています。Textured3DGAN は、テクスチャ付き 3D メッシュを生成する畳み込み手法を拡張した生成モデルです。 。 2D の監視下で GAN を使用して、物理画像からテクスチャ メッシュを生成する方法を学習できます。以前の方法と比較して、Textured3DGAN は姿勢推定ステップのキーポイントの要件を緩和し、ラベルのない画像コレクションや ImageNetDIB-R などの新しいカテゴリ/データセットに方法を一般化します。これは微分可能なレンダラー ベースです。補間には、下部にある PyTorch 機械学習フレームワークを使用します。このレンダラーは、3D Deep Learning PyTorch GitHub リポジトリ (Kaolin) に追加されました。この方法では、画像内のすべてのピクセルの勾配を分析的に計算できます。中心となるアイデアは、前景のラスタライゼーションをローカル属性の加重補間として扱い、背景のラスタライゼーションをグローバル ジオメトリの距離ベースの集約として扱うことです。このようにして、単一の画像から形状、テクスチャ、光などの情報を予測できます。PolyGen: PolyGen は、メッシュを直接モデリングするための Transformer アーキテクチャに基づく自己回帰生成モデルです。モデルはメッシュの頂点と面を順番に予測します。 ShapeNet Core V2 データセットを使用してモデルをトレーニングし、得られた結果は人間が構築したメッシュ モデル SurfGen: 明示的な表面識別器を使用した敵対的 3D 形状合成に非常に近いものでした。エンドツーエンドでトレーニングされたモデルは、さまざまなトポロジーで忠実度の高い 3D 形状を生成できます。 GET3D は、画像を学習することで高品質な 3D テクスチャ形状を生成できる生成モデルです。その核となるのは、微分可能サーフェス モデリング、微分可能レンダリング、および 2D 生成敵対的ネットワークです。 GET3D は、2D 画像のコレクションをトレーニングすることにより、複雑なトポロジー、豊富な幾何学的詳細、および忠実度の高いテクスチャを備えた、明示的にテクスチャー処理された 3D メッシュを直接生成できます。 ##書き換えが必要な内容は以下のとおりです: 図2 GET3D生成モデル (出典: GET3D論文公式Webサイト https://nv-tlabs.github.io/GET3D/) GET3Dは最近提案された3Dです生成モデル。椅子、オートバイ、車、人物、建物などの複雑なジオメトリを持つ複数のカテゴリに対して、ShapeNet、Turbosquid、Renderpeople を使用して 3D 形状を無制限に生成する最先端のパフォーマンスを実証します。
 写真
写真
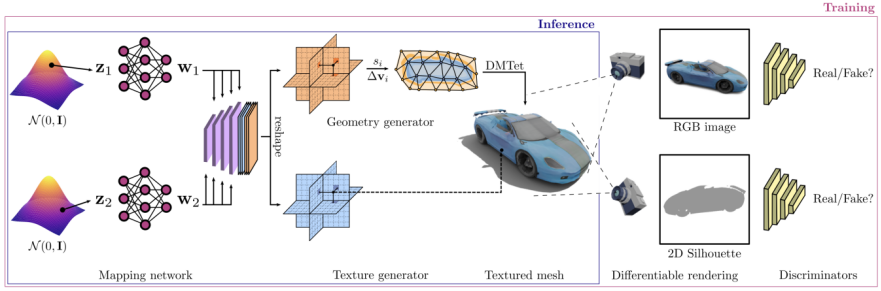
GET3D アーキテクチャは GET3D Paper 公式 Web サイトから引用しています。図 3 は、このアーキテクチャを示しています。
は 2 つの潜在エンコーディングを通じて 3D SDF (Directed Distance Field) とテクスチャ フィールドを生成し、DMTet (Deep Marching Tetrahedra) を使用して SDF から 3D サーフェス メッシュを抽出して追加します。クラウドはテクスチャ フィールドをクエリして色を取得します。プロセス全体は、2D 画像で定義された敵対的損失を使用してトレーニングされます。特に、RGB イメージと輪郭は、ラスタライズベースの微分可能レンダラーを使用して取得されます。最後に、入力が本物か偽物かを区別するために、それぞれ RGB 画像と輪郭に対して 2 つの 2D 識別器が使用されます。モデル全体をエンドツーエンドでトレーニングできます。
GET3D は他の面でも非常に柔軟で、出力式としての明示的なメッシュに加えて、次のような他のタスクにも簡単に適応できます。ジオメトリとテクスチャの分離の実装: モデルのジオメトリとテクスチャの間で適切な分離が実現され、ジオメトリ 潜在コードとテクスチャ 潜在コードの有意義な補間が可能になります。
異なるカテゴリの形状の生成間のスムーズな移行が可能になります。潜在空間内でランダム ウォークを実行し、対応する 3D 形状を生成することで実現します。
新しい形状の生成: 小さなノイズを追加することで、ローカルの潜在コードを混乱させて、類似しているが局所的にわずかに異なる形状を生成できます。
教師なしマテリアル生成: DIBR と組み合わせることで、マテリアルは完全に教師なしで生成され、意味のあるビュー依存の照明効果を生成します。
テキストガイドによる形状生成へ: StyleGAN NADA を組み合わせることにより、 - 計算上レンダリングされた 2D 画像とユーザーが指定したテキストの指向性クリップ損失を使用して 3D ジェネレーターを調整します。ユーザーはテキスト プロンプトを使用して多数の意味のある形状を生成できます
画像 図 4 を参照してください。テキストに基づいて図形を生成するプロセスが示されています。この図のソースは GET3D 論文の公式 Web サイトで、URL は https://nv-tlabs.github.io/GET3D/
図 4 を参照してください。テキストに基づいて図形を生成するプロセスが示されています。この図のソースは GET3D 論文の公式 Web サイトで、URL は https://nv-tlabs.github.io/GET3D/
Part 04
以上がGET3D の生成モデルに関する 5 分間の詳細な技術トークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



