
Redis は、データベース、キャッシュ、およびメッセージキューブローカー。 #文字列、ハッシュテーブル、#をサポートします。 ##List、Set、Ordered Set 、 bitmap、hyperloglogs およびその他のデータ型。組み込みレプリケーション、Lua スクリプト、LRU エビクション、トランザクション などディスクのレベル 永続化機能は、Redis Sentinel による高可用性と、Redis Cluster による自動 パーティショニング # も提供します。
Redis の速度 シングルスレッド モデルの KV データベース 、 は C 言語で書かれています 、提供される公式データは 100,000 QPS (1 秒あたりのクエリ数) に達することがあります。 #横軸は接続数、縦軸は QPS です。 公式データを確認したところ、非常に速いことがわかりました。夢を持つプログラマーとして、なぜこれがそんなに速いのかを知る必要があります。それは間違いです。 次に、Web ページ上のいくつかの情報を確認しました。一般的な状況は次のとおりです。 完全に基づいています一部のリクエストは純粋にメモリ操作であり、非常に高速です。データは HashMap と同様にメモリに保存されます。HashMap の利点は、検索と操作の時間計算量が O(1) であることです。 データ構造がシンプルであり、データ操作もシンプルです。Redis のデータ構造は特別に設計されており、
要約すると、実際には 3 つのポイントがあります: epoll ネットワーク モデルを使用し、単一のスレッドを使用してリクエストを処理します。 #ニーズを満たすさまざまな高性能データ構造を使用します。 #redis はメモリ操作を使用し、C 言語で書かれています。 この一連の記事は、epoll ネットワーク モデルの説明に焦点を当てているわけではなく、主にRedis データ構造の原則を学習するプロセス。 Redis のデータ処理が非常に高速である理由を教えてください。 #redis の文字列実装原則 redis のリスト実装原則 ##Redis のソート セットの実装原則 Redis ハッシュの実装原則 ##他のデータ型の紹介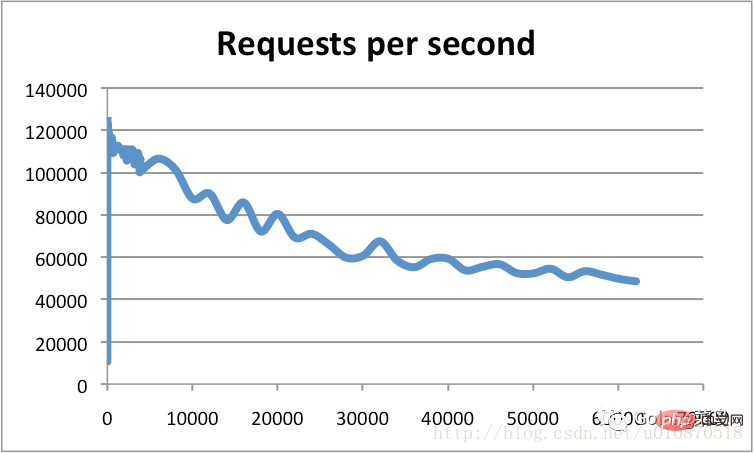
マルチチャネル I/O 多重化モデルは、select、poll、および epoll を使用して、複数の I/O イベントを監視します。アイドル状態の場合、現在のスレッドはブロックされ、1 つ以上のストリームに I/O イベントがあると、ブロック状態から復帰するため、プログラムはすべてのストリームをポーリングします (epoll は、実際に発行したストリームのみをポーリングします)イベント)、準備ができたストリームのみが順次処理されるため、多数の無駄な操作が回避されます。
出発点
以上がRedis ノートの記録の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



