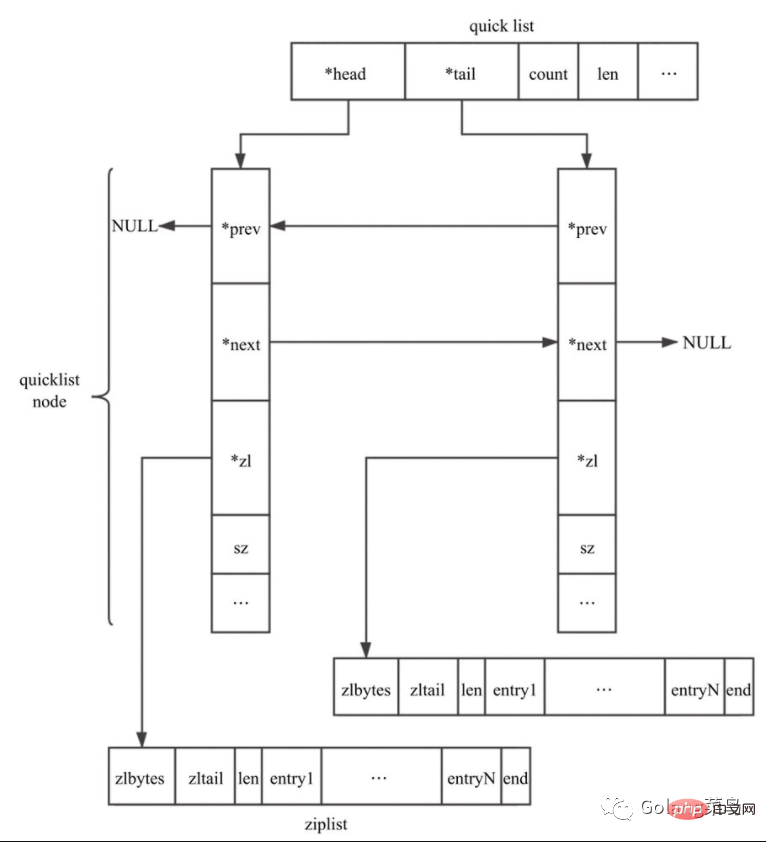
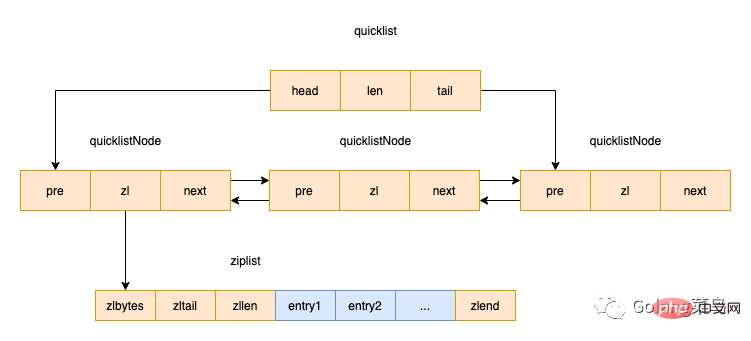
quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为A doubly linked list of ziplists。顾名思义,quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
typedef struct quicklist {
// 指向quicklist的首节点
quicklistNode *head;
// 指向quicklist的尾节点
quicklistNode *tail;
// quicklist中元素总数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNode节点个数
unsigned long len; /* number of quicklistNodes */
// ziplist大小设置,存放list-max-ziplist-size参数的值
int fill : 16; /* fill factor for individual nodes */
// 节点压缩深度设置,存放list-compress-depth参数的值
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: 4;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;
ログイン後にコピー
quicklistNode定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



