


安定拡散 (SD) は、現在最も一般的なテキストから画像へ (テキストから画像へ) 生成する拡散モデルです。その強力な画像生成機能は衝撃的ですが、明らかな欠点は、膨大なコンピューティング リソースを必要とし、推論速度が非常に遅いことです。SD-v1.5 を例に挙げると、半精度ストレージを使用した場合でも、そのモデル サイズは 1.7GB です。パラメータが 10 億個ある場合、デバイス上の推論時間は 2 分近くになることがよくあります。
推論速度の問題を解決するために、学界と産業界は主に 2 つのルートに焦点を当てて SD 高速化の研究を開始しました。 (1) 推論ステップ数の削減、このルート2 つのサブルートに分かれており、1 つはより優れたノイズ スケジューラを提案することでステップ数を削減するもので、代表的な成果は DDIM [1]、PNDM [2]、DPM [3] などです。順蒸留のステップ数(Progressive Distillation) ステップ数、代表的な作品としては、プログレッシブ蒸留[4]、w-コンディショニング[5]などがあります。 (2) エンジニアリング スキルの最適化. 代表的な成果としては、Qualcomm が int8 定量化フルスタック最適化を使用して Android 携帯電話で SD-v1.5 を 15 秒で達成 [6]、Google がオンエンド GPU 最適化を使用して SD-v1 を達成していることです。 Samsung 携帯電話では .4。12 秒まで加速します [7]。
これらの取り組みは長い道のりを歩んできましたが、まだ十分なスピードで進んでいません。
最近、スナップ研究所は、ネットワーク構造、学習プロセス、損失関数の包括的な最適化により、2 秒で画像を生成できる最新の高性能安定拡散モデルを発表しました。 iPhone 14 Pro. (512x512) で、SD-v1.5 よりも優れた CLIP スコアを達成します。これは既知の最速のエンドツーエンド安定拡散モデルです。

次の表は、SD-v1.5 モデルと SnapFusion モデルの概要比較です。UNet と VAE デコーダの 2 つの部分によって速度が向上していることがわかります。 UNet 部分が大きな部分です。 UNet 部分の改善には 2 つの側面があります。1 つは、提案された Efficient UNet 構造を通じて得られる単一遅延の削減 (1700 ミリ秒 -> 230 ミリ秒、7.4 倍の加速)、もう 1 つは推論ステップの削減です ( 50 -> 8、6.25 x 加速)、これは提案された CFG を意識した蒸留によって得られます。 VAE デコーダは、構造化されたプルーニングによって高速化されます。

(1) 効率的な UNet
UNet の Cross-Attend モジュールと ResNet モジュールを分析することで速度を特定します。以下の図に示すように、ボトルネックはクロス アテンション モジュール (特に最初のダウンサンプル ステージのクロス アテンション) にあります。この問題の根本的な原因は、アテンション モジュールの複雑さが特徴マップの空間サイズと二乗関係にあることです。最初のダウンサンプル ステージでは、特徴マップの空間サイズがまだ大きいため、計算の複雑さが高くなります。
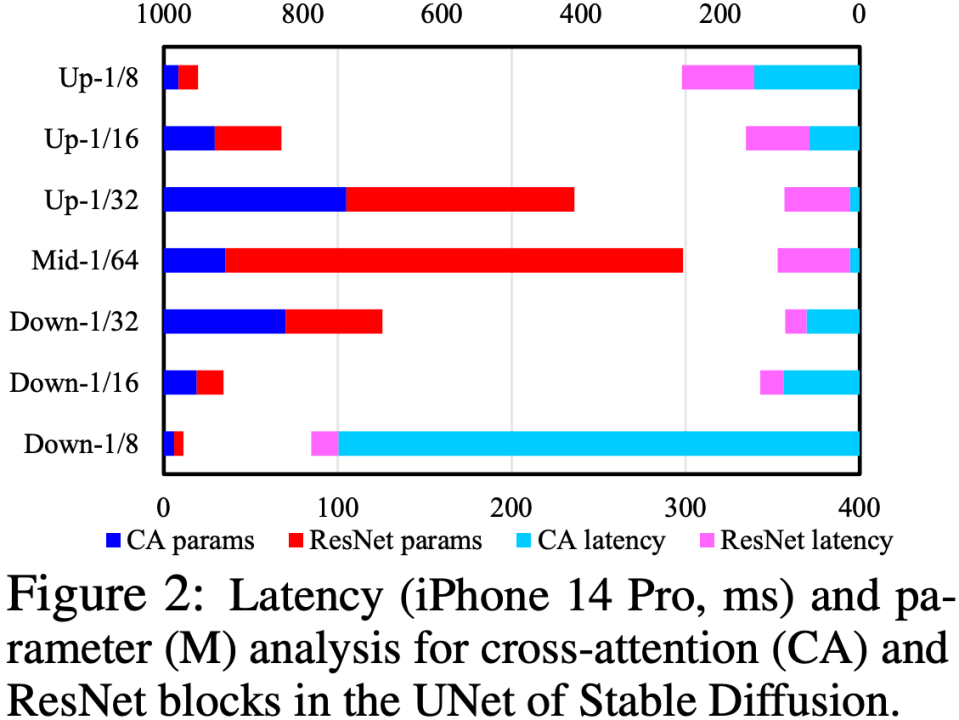
UNet 構造を最適化するために、UNet 構造の自動評価および進化プロセスのセットを提案します。最初に UNet 上で堅牢なトレーニング (ロバスト トレーニング) を実施し、トレーニング中にいくつかのモジュールをランダムにドロップしてそれぞれをテストします。パフォーマンスに対する各モジュールの実際の影響は、「CLIP スコアに対する影響とレイテンシへの影響」のルックアップ テーブルを構築するために構築されます。その後、ルックアップ テーブルに基づいて、CLIP スコアにほとんど影響を与えず、影響が非常に大きいモジュールを削除することが優先されます。時間がかかる。この一連のプロセスはオンラインで自動的に実行され、完了すると、Efficient UNet と呼ばれるまったく新しい UNet 構造が得られます。オリジナルの UNet と比較して、パフォーマンスを低下させることなく 7.4 倍の高速化を実現します。
(2) CFG を意識したステップ蒸留
CFG (Classifier-Free Guide) は SD 推論段階です画質を大幅に向上させるための必須スキル、非常に重要です。加速のために段階的蒸留を使用する拡散モデルに関する研究はこれまでにも行われていますが[4]、それらは蒸留トレーニングの最適化目標として CFG を含めていませんでした。つまり、蒸留損失関数は後で CFG が使用されることを知りません。私たちの観察によると、ステップ数が少ない場合、これは CLIP スコアに重大な影響を及ぼします。
この問題を解決するために、蒸留損失関数を計算する前に教師モデルと学生モデルの両方に CFG を実行させ、損失関数が CFG 後のフィーチャで計算されるようにすることを提案します。したがって、さまざまな CFG スケールの影響が明示的に考慮されます。実験では、CFG を意識した蒸留を完全に使用することで CLIP スコアは改善できるものの、FID も大幅に悪化することがわかりました。次に、元のステップ蒸留損失関数と CFG を意識した蒸留損失関数を混合するランダム サンプリング スキームを提案し、2 つの利点の共存を実現しました。これにより、CLIP スコアが大幅に改善されただけでなく、FID も悪化しませんでした。 。このステップにより、さらなる推論段階で 6.25 倍の加速が達成され、合計で約 46 倍の加速が達成されます。
上記の 2 つの主要な貢献に加えて、この記事には、VAE デコーダのプルーニング アクセラレーションと蒸留プロセスの慎重な設計も含まれています。具体的な内容については、論文を参照してください。
SnapFusion ベンチマーク SD-v1.5 のテキストから画像への変換機能。目標は、推論時間を大幅に短縮し、画質を劣化させることなく維持することです。これが最もよく表されています。これを次の図に示します。
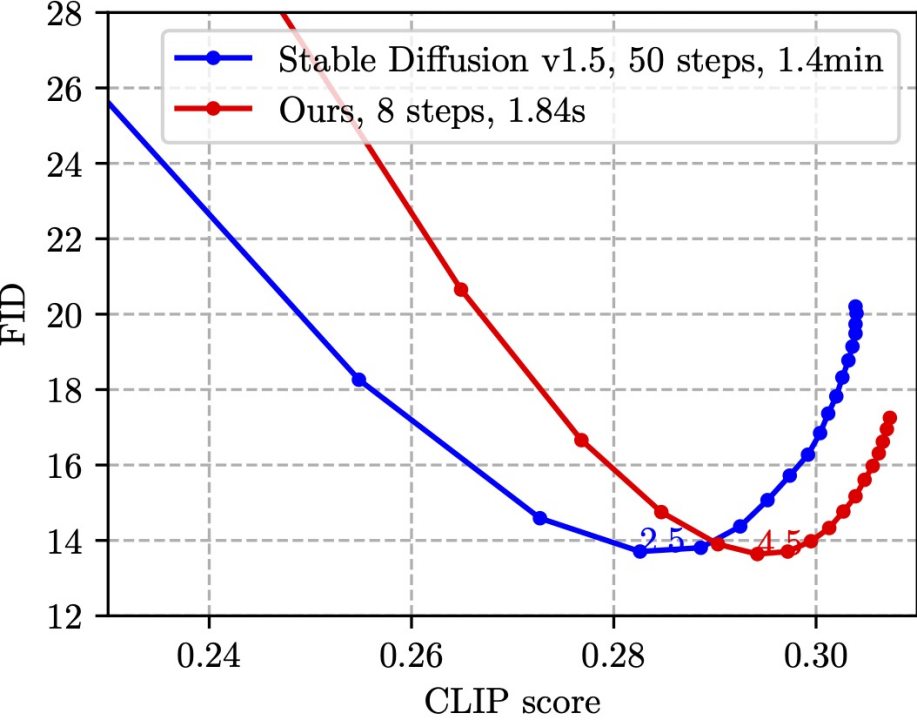
この図は、CLIP を計算するために MS COCO'14 検証セット上の 30,000 個のキャプションと画像のペアをランダムに選択します。スコアと FID。 CLIP スコアは、画像とテキスト間の意味上の一貫性を測定し、大きいほど優れています。FID は、生成された画像と実際の画像の間の分布距離 (一般に、生成された画像の多様性の尺度と考えられます) を測定し、小さいほど優れています。グラフ内の異なる点は異なる CFG スケールを使用して取得され、各 CFG スケールはデータ ポイントに対応します。図からわかるように、私たちの方法 (赤線) は SD-v1.5 (青線) と同じ最低の FID を達成でき、同時に私たちの方法の CLIP スコアも優れています。 SD-v1.5 ではイメージの生成に 1.4 分かかるのに対し、SnapFusion では 1.84 秒しかかからないことは注目に値します。これは、私たちが知る限り最速のモバイル安定拡散モデルでもあります。
SnapFusion によって生成されたサンプルをいくつか示します:

その他のサンプルをご覧ください記事の付録を参照してください。
これらの主な結果に加えて、この記事では効率的な SD モデルの開発に参考となる経験を提供することを目的として、多数のアブレーション解析 (アブレーションスタディ) 実験も示しています。
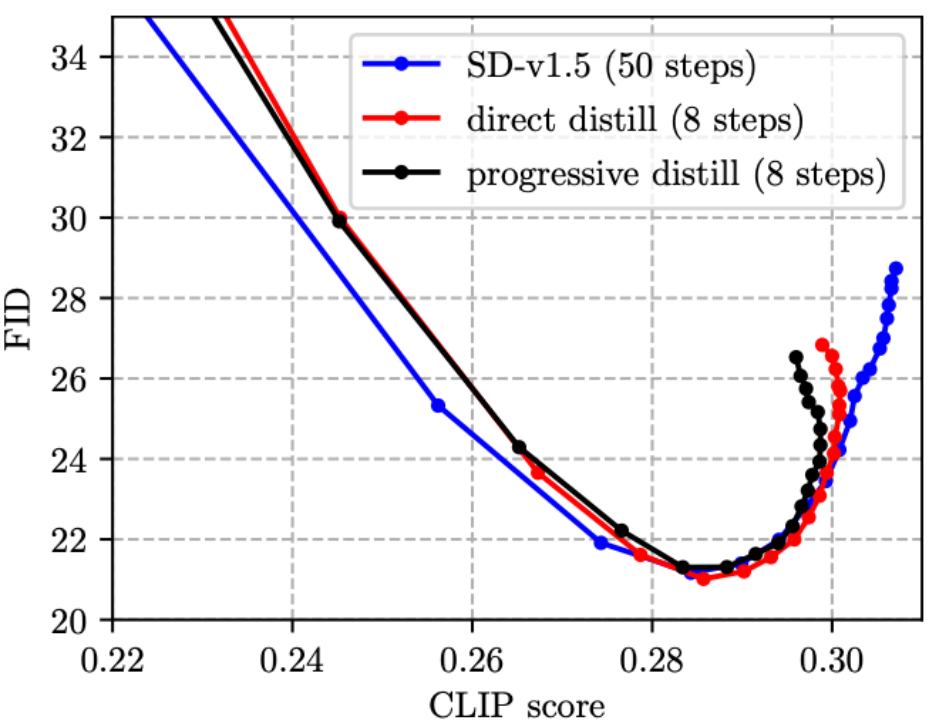
# (1) 段階蒸留に関する以前の研究では、通常、漸進スキーム [4、5] が使用されていましたが、SD モデルでは漸進蒸留には直接蒸留に比べて利点がなく、プロセスが煩雑であることがわかりました。この記事では直接蒸留スキームを使用します。
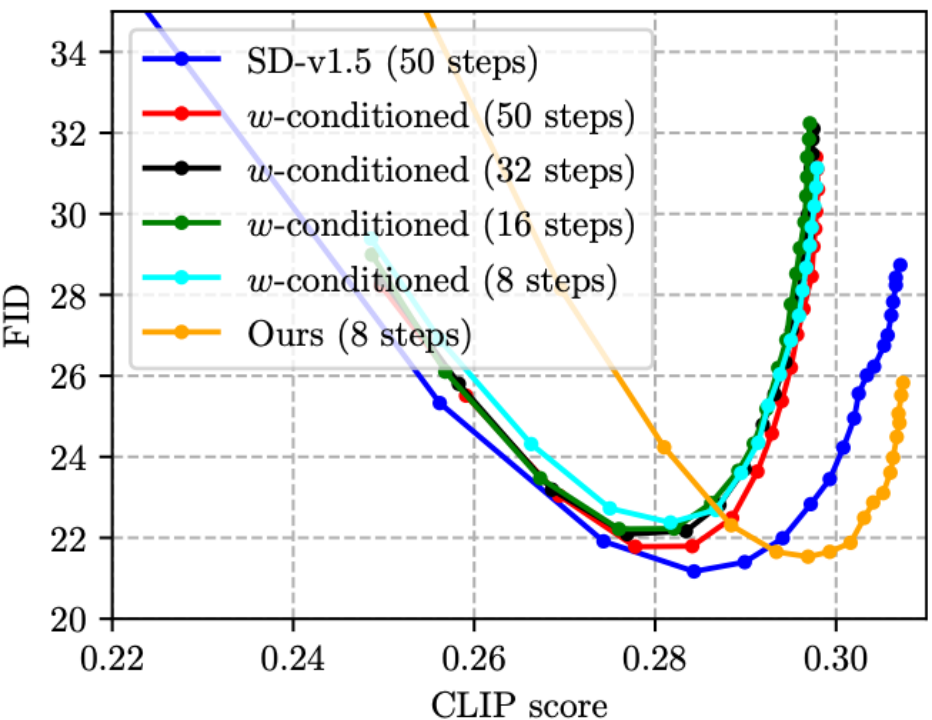
(2) CFG は画質を大幅に向上させることができますが、コストは推論コストの 2 倍になります。今年の CVPR'23 賞候補者の蒸留に関する論文 [5] では、蒸留のための UNet への入力として CFG パラメータを使用する w-conditioning (結果として得られるモデルは w-conditioned UNet と呼ばれます) を提案し、それによって推論中の CFG ステップを排除し、推論を実現します。コストが半分になります。しかし、そうすることで実際には画質が低下し、CLIP スコアが低下することがわかりました (下の図に示すように、4 本の w 条件付きラインの CLIP スコアは 0.30 を超えず、これは SD よりも悪いです)。 v1.5)。私たちの方法では、提案された CFG を認識した蒸留損失関数のおかげで、ステップ数を削減し、同時に CLIP スコアを向上させることができます。特に注目すべき点は、以下の図の緑の線 (w 条件付き、16 ステップ) とオレンジ色の線 (私たちのもの、8 ステップ) の推論コストは同じですが、オレンジ色の線の方が明らかに優れていることです。テクニカル ルートは、W 条件付きコンディショニング [5] よりも優れており、蒸留された CFG ガイド付き SD モデルではより効果的です。
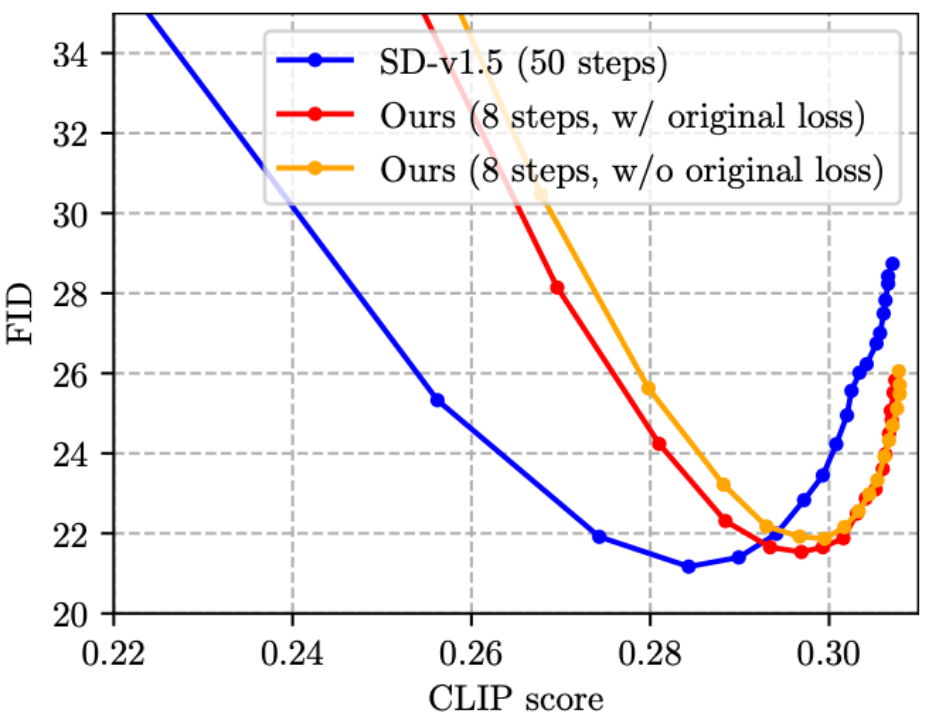
(3) ステップ蒸留に関する既存の研究 [4、5] は、元の損失関数と蒸留を組み合わせていませんでした。画像分類の知識の抽出に精通している友人なら、この設計が直観的に最適ではないことが分かるはずです。そこで、以下の図に示すように、トレーニングに元の損失関数を追加することを提案しました。これは実際に効果的です (FID がわずかに減少します)。
この論文では、高性能安定拡散モデルである SnapFusion を提案します。携帯端末。 SnapFusion には 2 つの主要な貢献があります。(1) 既存の UNet のレイヤーごとの分析を通じて、速度のボトルネックを特定し、元の Stable Diffusion の UNet を効果的に置き換えることができる新しい効率的な UNet 構造 (Efficient UNet) を提案します。 7.4 倍の加速を達成; (2) 推論フェーズの反復ステップ数を最適化し、ステップ数を削減しながら CLIP スコアを大幅に改善できる新しいステップ蒸留スキーム (CFG 認識ステップ蒸留) を提案し、6.25 倍を達成します。加速度。全体として、SnapFusion は iPhone 14 Pro 上で 2 秒以内に画像出力を達成します。これは現在知られている最速のモバイル安定拡散モデルです。
今後の取り組み:
1. SD モデルは、さまざまな画像生成シナリオで使用できます。時間の制約のため、現在はテキストから画像へのコアタスクのみに焦点を当てており、他のタスク (修復、ControlNet など) については後で説明します。
2. この記事では主に速度の向上に焦点を当てており、モデル ストレージの最適化については説明しません。提案されている Efficient UNet にはまだ圧縮の余地があると考えており、他の高性能最適化手法 (枝刈り、量子化など) と組み合わせることで、ストレージを縮小し、時間を 1 秒未満に短縮し、リアルタイム SD を実現できることが期待されます。オフエンドではさらに一歩進んでいます。
以上がiPhone は画像を生成するのに 2 秒かかります。既知の最速のモバイル安定拡散モデルがここにあります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



