


対顔弾幕、つまりビデオ画面内のキャラクターを遮らずに大量の弾幕が飛び交い、キャラクターの背後から浮遊しているように見えます。
機械学習は数年前から普及していますが、多くの人はこれらの機能がブラウザでも実行できることを知りません;
この記事では、ビデオの集中砲火における実践的な最適化プロセスを紹介します。記事の最後に、このソリューションが適用できるいくつかのシナリオについて説明し、いくつかのアイデアが生まれることを期待しています。
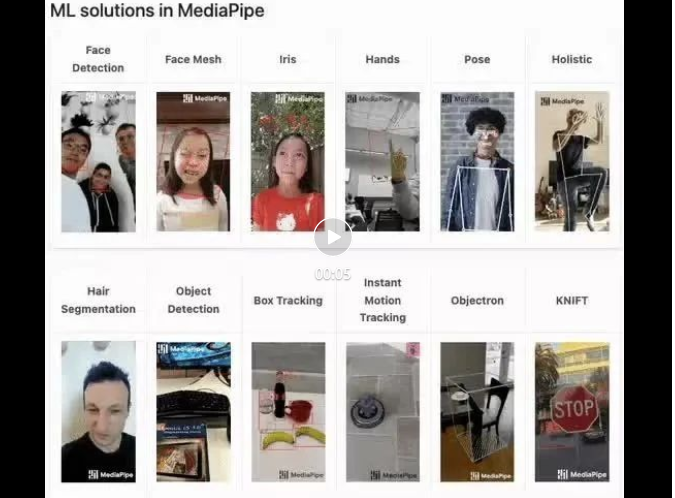
mediapipe デモ(https://google.github.io/mediapipe/)は、
up ビデオのアップロード
サーバーのバックグラウンド計算により、ビデオ画面のポートレート領域が抽出され、SVG ストレージに変換されます
クライアントがビデオを再生している間、サーバーからsvgをダウンロードします 弾幕と組み合わせると、ポートレートエリアには弾幕が表示されません
理論上のパフォーマンス限界は従来のソリューションよりも劣っており、ネットワーク リソースのパフォーマンス リソースを交換するのと同等です
BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)
戻りデータ構造の例
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)window.setTimeout(detect, 66) // 33 => 66
フレーム グラフを分析すると、パフォーマンスのボトルネックが次の場所にあることがわかります。 toBinaryMask と toDataURL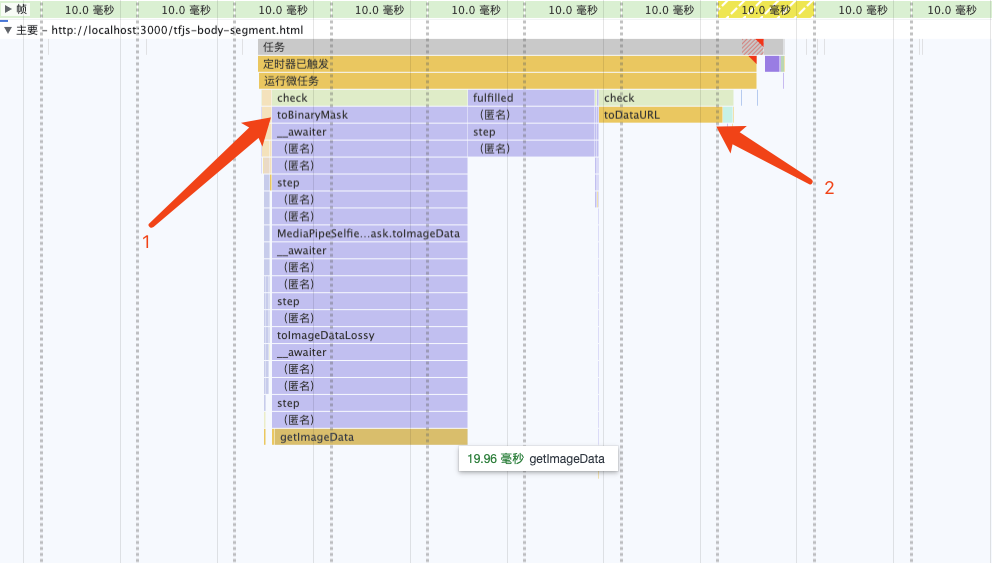
async function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl) context.clearRect(0, 0, canvas.width, canvas.height)// 1. 将`ImageBitmap`绘制到 Canvas 上context.drawImage(// 经验证 即使出现多人,也只有一个 segmentationawait segmentation[0].mask.toCanvasImageSource(),0, 0,canvas.width, canvas.height)// 2. 设置混合模式context.globalCompositeOperation = 'source-out'// 3. 反向填充黑色context.fillRect(0, 0, canvas.width, canvas.height)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 66)}globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)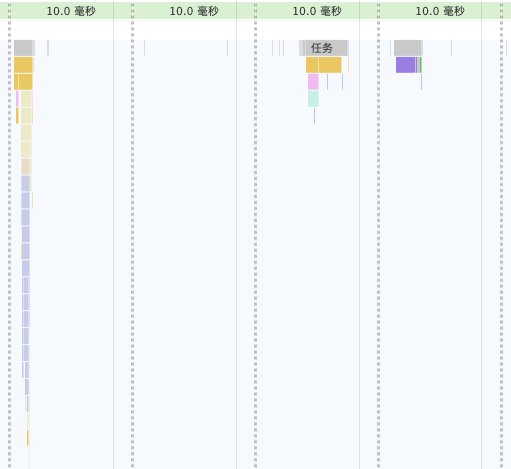
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
这个两步前端工程已经非常成熟了,略过细节。

注意事项
本期作者

刘俊
Bilibili シニア開発エンジニア
以上がウェブ上の顔面ブロック攻撃に対するリアルタイム保護 (機械学習に基づく)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



