


DeepMind の新しい AI が Nature に登場したのは 1 日だけですが、GPT-4 が競争するためにやって来ました。
GPT-4 は、わずか 2 段落のプロンプトで、AlphaDev と同じ並べ替えアルゴリズム最適化メソッドを提供します。
DeepMind は、AlphaDev を「AlphaGo の魔法を再現している」と呼んでいます。これは、ソート アルゴリズムを最大 70% 高速化できる方法を発見したためです。
ああ、AlphaDev は今さらに恥ずかしい思いをしています。
GPT-4 に同じ操作を直接実行した兄弟を「検出」させます:
強化学習はまったく必要ありません。この発見をNatureに掲載してもいいでしょうか?
マスク氏は「通りかかったときにそれを見た」と述べ、また「吹き飛ばされたため」という一文を残した。

では、GPT-4 はどのように行うのでしょうか?
この新しい発見をもたらしたのは、ウィスコンシン大学マディソン校のディミトリス・パパイリオプーロス准教授 (以下、教授 D と呼びます) です。
GPT-4 にこの操作を実行させるために彼が使用した手順は非常に単純で、合計で 2 つのプロンプトを入力するだけでした。
まず第一に、彼は GPT-4 に次のように言いました:
ソート アルゴリズムがあり、それはさらに最適化できると思います。どの文を書き直す必要がありますか? 。その理由を段階的に説明し、戻ってそれが正しいかどうかを確認します。

最初のステップでは、新しい発見があった場合は、最初に変更を加えるのではなく、ただ「観察」するだけであることも強調しました。改善のための提案をいくつか書き留めてください。
非常に詳細かつ慎重に行ってください。
GPT-4 では、指定されたコードの詳細な説明が提供されます。

D 教授は 2 つ目のヒントを与えました:
「続行」。自信がある場合は、上記のヒントに従ってください。生成される結果が決定的で一貫性があることを保証し、混乱を避けるために、温度を 0 に設定します。
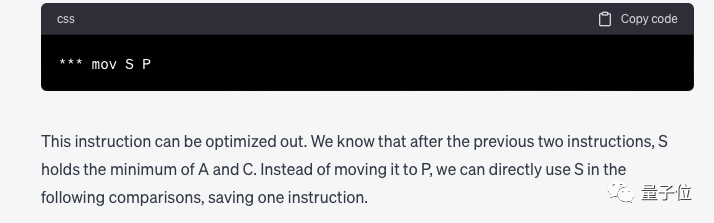
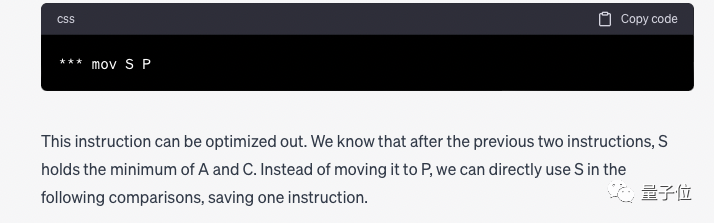
GPT-4 は詳細な手順を示し、最終的に次のように結論付けました。 mov S P" が冗長であり、他の命令が必要な場合は削除できます。ただし、削除後は P を S に置き換える必要があります。
 DeepMind の新しい研究である AlphaDev が同じ問題を扱っていると考えていることを比較すると、それがそれと無関係であるとは言えません。全く同じであるとしか言えません:
DeepMind の新しい研究である AlphaDev が同じ問題を扱っていると考えていることを比較すると、それがそれと無関係であるとは言えません。全く同じであるとしか言えません:
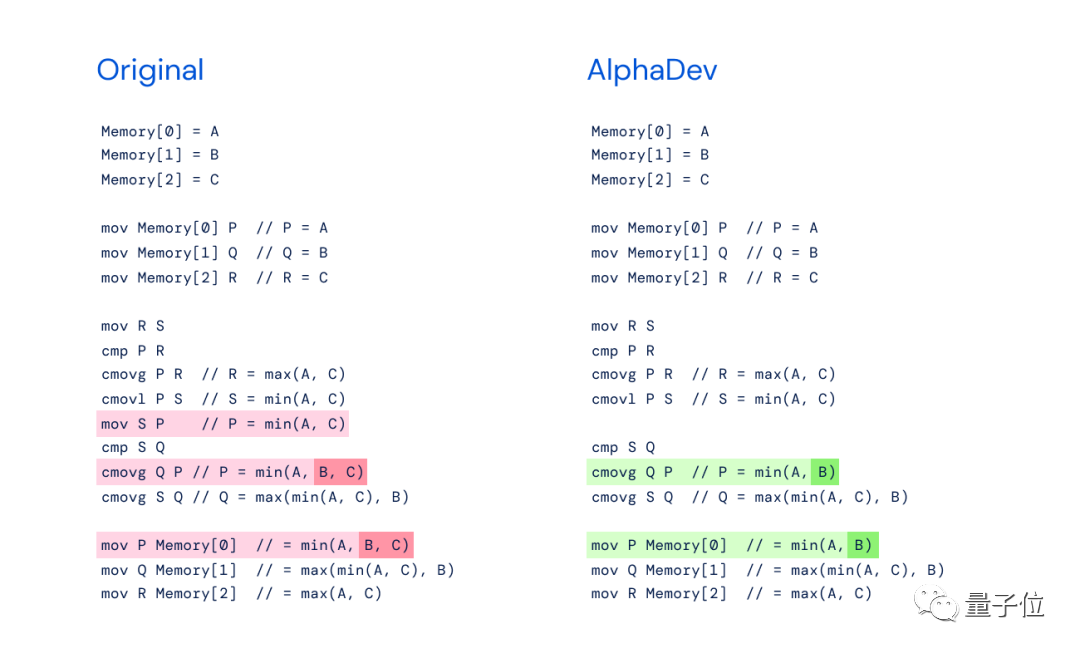 AlphaDev に対する DeepMind の操作は、AlphaGo の「ステップ 37」を彷彿とさせます。これは、直接敗北した直観に反する動きです。伝説の囲碁棋士イ・セドルが視聴者に衝撃を与えた。
AlphaDev に対する DeepMind の操作は、AlphaGo の「ステップ 37」を彷彿とさせます。これは、直接敗北した直観に反する動きです。伝説の囲碁棋士イ・セドルが視聴者に衝撃を与えた。
報道によると、AlphaDev は AlphaZero をベースにした強化学習アルゴリズムであり、その発見は既存のアルゴリズムに基づくものではなく、最下位レベルのアセンブリ命令から始まります。
その革新性は主に 2 つの命令シーケンスにあります。
(1) AlphaDev Swap Move (交換移動)
(2) AlphaDev Copy Move (コピー移動)
原則として、DeepMind の研究者は、そのためにシングルプレイヤーの「アセンブリ」ゲームを設計しました。
適切な命令 (下図のプロセス A) を検索して選択できる限り、それは可能です。は正解で、素早くデータを整理すると(下図の処理B)、報酬がもらえます。
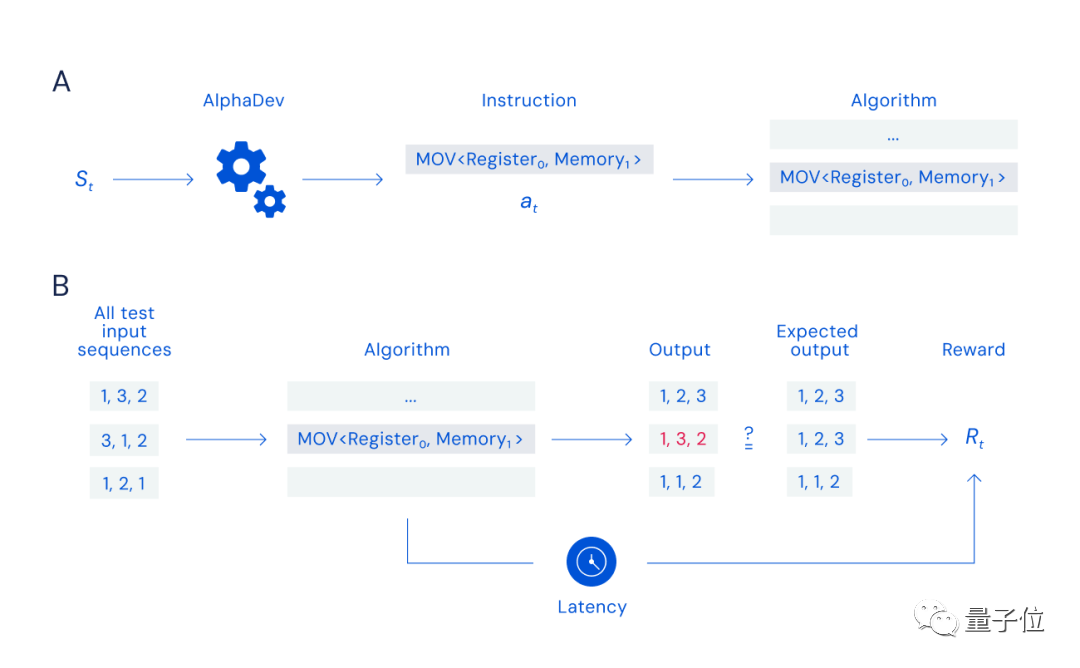
しかし、このゲームの課題は、探索空間のサイズだけではありません (組み合わせ可能な命令の数は、その数に相当します)宇宙の粒子の数)だけでなく、1 つの間違った命令がアルゴリズム全体の失敗を引き起こす可能性があるため、報酬関数の性質にも依存します。
GPT-4 の「セクシーな操作」について、次のように言う人もいます。上級開発者でさえ GPT-4 を過小評価しています。

# D教授の手術によって、忍耐強くプロンプトエンジニアリングを理解している限り、GPTで解決できることはまだあることがさらに証明されたと嘆く人もいます。 -4 では多くのことができます。

GPT-4 のトレーニング データには並べ替えアルゴリズムの最適化が含まれているため、GPT-4 でこれができるかどうか疑問に思う人もいます。

しかしそうは言っても、この問題がこれほど多くの注目と議論を集めている理由の大部分は、AlphaDev の登場をめぐる論争によるものです。自然について。
これは画期的な研究ではなく、DeepMind は誇張していると多くの人が感じています。

D 陰陽教授が「Nature にもログインできますか?」と言っただけでなく、クイックを最適化したと言うネチズンもいました。彼らがティーンエイジャーだったときにキューに入った場合、これも公開されるべきです。
もちろん、AlphaDev 自体の革新性は、強化学習を使用して新しいアルゴリズムを発見することであると信じている人もいます。 #####################どう思いますか?
参考リンク: [1]https://chat.openai.com/share/95693df4-36cd-4241-9cae-2173e8fb760c[2]https://twitter.com/DimitrisPapail/status/1666843952824168465
以上がGPT-4 は DeepMind を当惑させました: あなたは Nature の並べ替え最適化アルゴリズムに乗りました、そして私はそれを 2 つの段落で見つけましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



