


国内自社開発大型モデルは新人歓迎、リリースと同時にオープンソース化!
最新のニュースは、マルチモーダル大規模言語モデル TigerBot が正式に発表されたことです。これには、70 億のパラメータと 1,800 億のパラメータの 2 つのバージョンが含まれており、両方ともオープンソースです。
本モデルがサポートする対話AIも同時に起動します。
スローガンの作成、フォームの作成、文法上の誤りの修正はすべて非常に効果的であり、マルチモダリティもサポートし、画像を生成することもできます。

評価結果は、TigerBot-7B が同じサイズの OpenAI モデルの総合パフォーマンスの 96% に達していることを示しています。 。
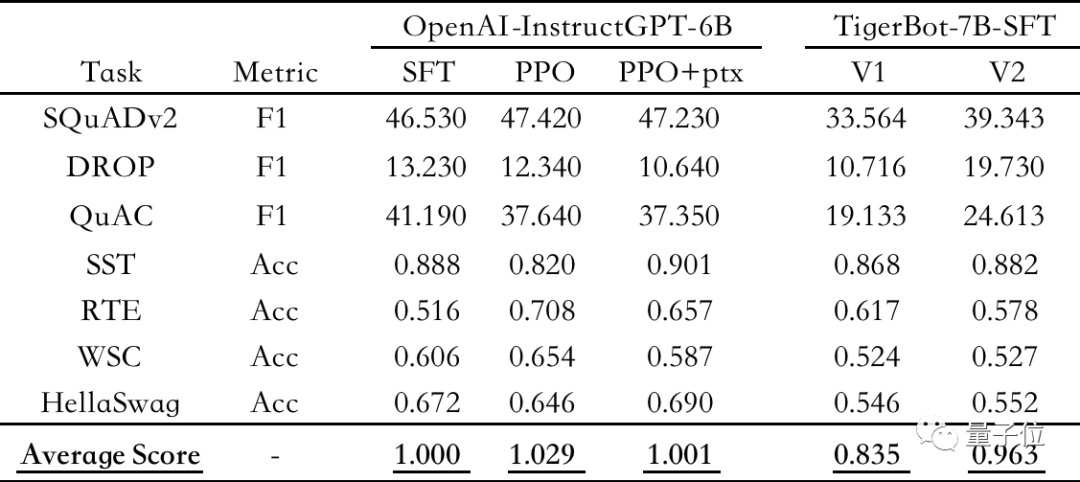
△公開 NLP データセットの自動評価。OpenAI-instruct GPT-6B-SFT をベンチマークとして使用し、各モデルの正規化と平均化を行います。
であり、より大規模な TigerBot-180B は、現在業界でオープンソースになっている 最大規模 大規模言語モデルである可能性があります。
さらに、チームは 100G の事前トレーニング データをオープンソース化し、1G または 100 万個のデータの微調整を監督しました 。
TigerBot に基づいて、開発者は 半日 で独自の大規模モデルを作成できます。
現在、TigerBot Dialogue AI は内部テストに招待されており、オープンソース コード データは GitHub にアップロードされています (詳細なリンクについては記事の最後を参照してください)。
これらの重要なタスクは、最初はわずか 5 人の小さなチームから行われます。チーフ プログラマー兼科学者は CEO 自身です。
しかし、このチームは決して無名ではありません。
2017 年から垂直分野検索に特化した NLP 分野での事業を開始しました。 はデータ量の多い金融分野を得意としており、Founder Securities、Guosen Securities などと緊密な協力関係を築いています。
創設者兼 CEO は、業界で 20 年以上の経験があり、カリフォルニア大学バークレー校の客員教授であり、最高の会議論文を 3 件、技術特許を 10 件保有しています。
今、彼らは専門分野から汎用の大型モデルへの移行を決意している。
そして、最初から最も低い基本モデルから開始し、3 か月以内に 3,000 回の実験反復を完了しました。そして、段階的な結果を外部にオープンソースする自信がまだあります。
人々は、自分が何者なのか疑問に思わずにはいられません。あなたは何をしたいですか?これまでにどのような段階的な成果が達成されましたか?
具体的には、TigerBot は国内で自社開発された大規模な多言語タスク モデルです。
生成、自由質疑応答、プログラミング、描画、翻訳、ブレインストーミングなどの 15 の主要カテゴリの機能をカバーし、60 を超えるサブタスクをサポートします。
また、モデルをネットワーク化してより新しいデータや情報を取得できるようにする プラグイン機能をサポートしています。
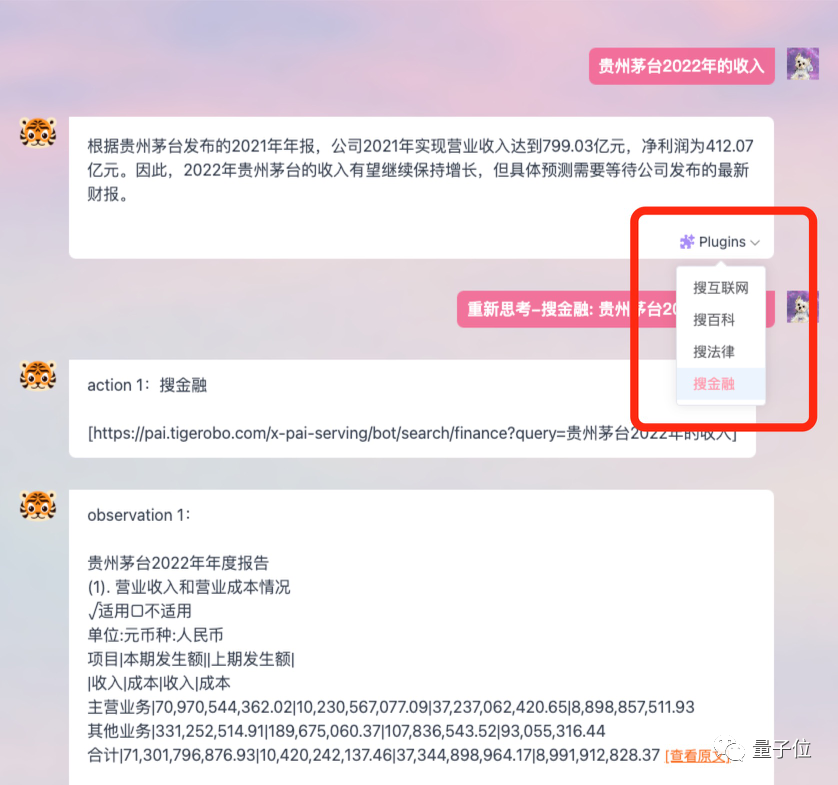
その位置付けはよりオフィスシーンに偏っており、人々のワークフローを改善し、効率を向上させるという目標を提案しています。
たとえば、Apple Vision Pro に関するニュース速報を書くのに役立ちます。結果は同様です:

または明確でよく構成された論文の概要を書く:
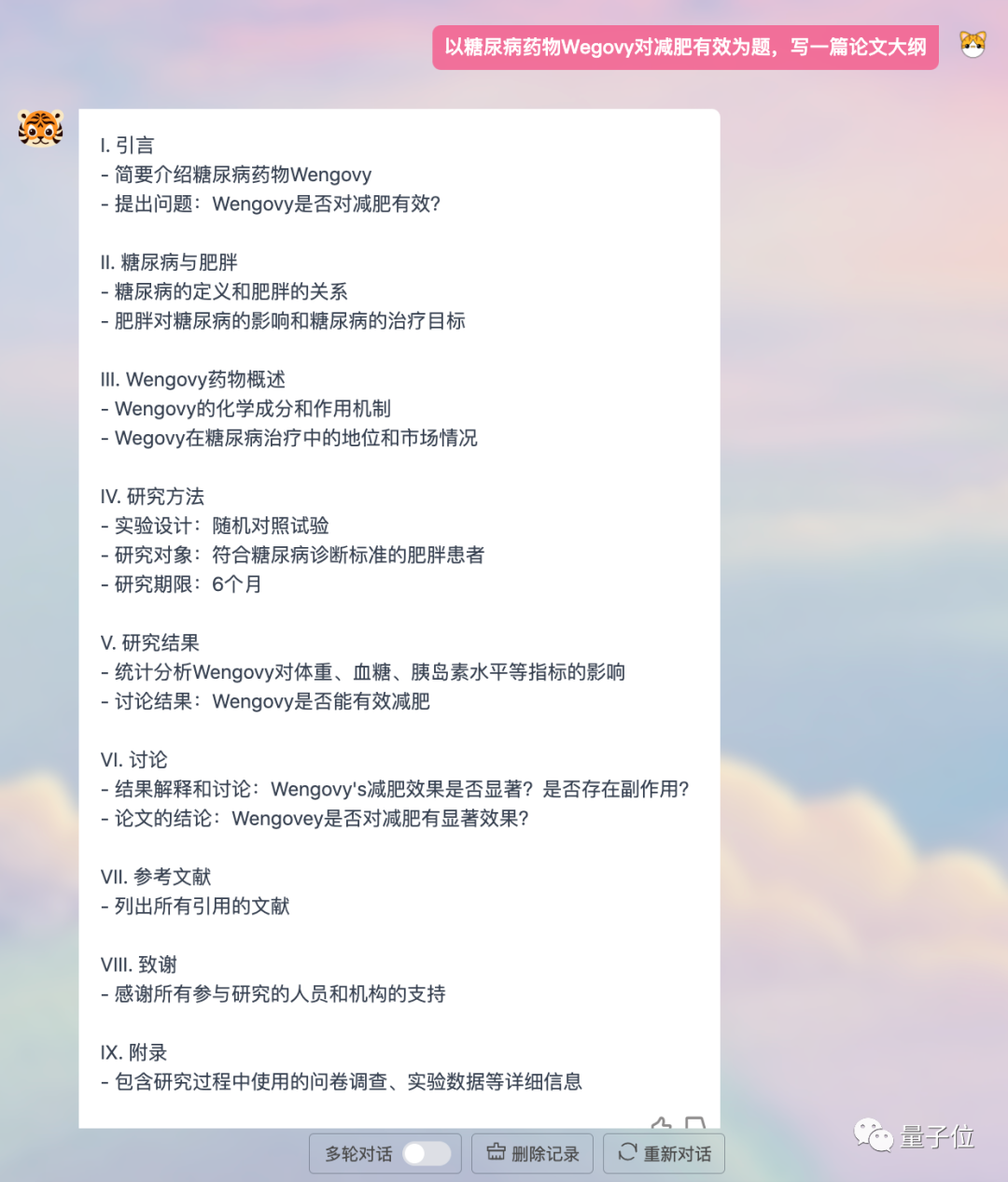
プログラミングは問題なく、英会話もサポートされます。

このリリースでは、TigerBot は 70 億パラメータ (TigerBot-7B) と 1,800 億パラメータ (TigerBot-180B) の 2 つのサイズをリリースしました。
チームは、これまでに達成されたすべての段階的な結果 (モデル、コード、データ) をオープンソース化します。
オープン ソース モデルには 3 つのバージョンが含まれています:
その中で、TigerBot-7B-base は、OpenAI の同等モデルや BLOOM よりも優れたパフォーマンスを発揮します。 TigerBot-180B-research は、現在業界で最大のオープンソース モデルである可能性があります (メタ オープンソース OPT のパラメーター サイズは 1,750 億、BLOOM のスケールは 1,760 億)。
オープン ソース コードには、基本的なトレーニング コードと推論コード、デュアル カード推論 180B モデルの量子化コードと推論コードが含まれています。
データには、100G の事前トレーニング データと、1G または 100 万個のデータの教師あり微調整が含まれます。
公開 NLP データセットに関する OpenAI InstructGPT 論文の自動評価によると、TigerBot-7B は、同じサイズの OpenAI モデルの全体的なパフォーマンスの 96% に達しています。
そして、このバージョンは、MVP (実行可能な最小限のモデル) にすぎません。
これらの結果は、主に、チームが GPT と BLOOM に基づいてモデル アーキテクチャとアルゴリズムをさらに最適化したことによるものです。これは、過去数か月における TigerBot チームの主要な革新作業でもあり、モデルをより効率的にしました. 学習能力、創造力、制御可能な生成力が大幅に向上しました。
具体的にはどうやって実装すればいいのでしょうか?下を向いてください。
TigerBot によってもたらされた革新には、主に次の側面が含まれます:
最初に を見てみましょう監視付き微調整 メソッドを完了するための指示。
これにより、モデルは人間がどのような種類の質問をしたのかを迅速に理解し、少数のパラメータのみを使用しながら回答の精度を向上させることができます。
原則として、制御にはより強力な教師あり学習が使用されます。
マークアップ言語を通じて、確率的手法を使用して、大規模なモデルが命令カテゴリをより正確に区別できるようにします。たとえば、指示の質問は事実に基づいたものですか、それとも乖離したものですか?コードですか?それはフォームですか?
つまり、TigerBot は 10 の主要なカテゴリと 120 の小さなタスクのカテゴリをカバーしています。次に、判断に基づいてモデルを対応する方向に最適化します。
によってもたらされる直接的な利点は、呼び出されるパラメータの数が減り、モデルが新しいデータやタスクに適応しやすくなる、つまり学習性が向上することです。
同じトレーニング条件の 50 万件のデータでは、TigerBot の収束速度はスタンフォード大学が発表した Alpaca の 5 倍であり、公開データセットでの評価では 17% 向上していることがわかりました。
第二に、モデルが生成されたコンテンツの 創造性 と 事実の制御性 のバランスをどのように改善できるかということも非常に重要です。
TigerBot は、一方では ensemble 手法を採用し、創造性と事実の制御可能性を考慮して複数のモデルを組み合わせます。
ユーザーのニーズに応じて、2 つのモデルのバランスを調整することもできます。
その一方で、AI分野における古典的な確率モデリング(Probabilistic Modeling)手法も採用されています。
これにより、モデルは、コンテンツ生成プロセス中に最後に生成されたトークンに基づいて 2 つの確率を与えることができます。確率は、コンテンツが乖離し続けるかどうかを決定し、確率は、生成されたコンテンツが事実のコンテンツから乖離する度合いを示します。
2 つの確率値を組み合わせると、モデルは創造性と制御性の間でトレードオフを行います。 TigerBot の 2 つの確率は、特別なデータを使用してトレーニングされます。
モデルが次のトークンを生成するとき、全文を見ることができない場合が多いことを考慮して、TigerBot は、回答が書かれた後に再度判断を行います。モデルを書き直す必要があります。
私たちの経験の中で、TigerBot によって生成された回答は、ChatGPT のような逐語的な出力モードではなく、「考えた」後に完全な回答が得られることもわかりました。

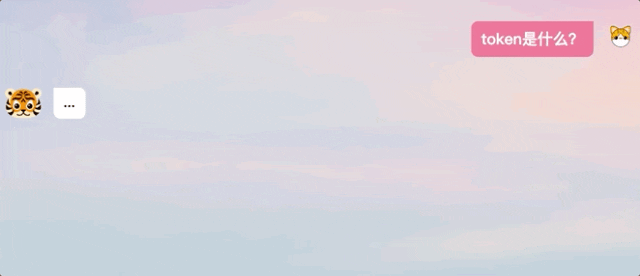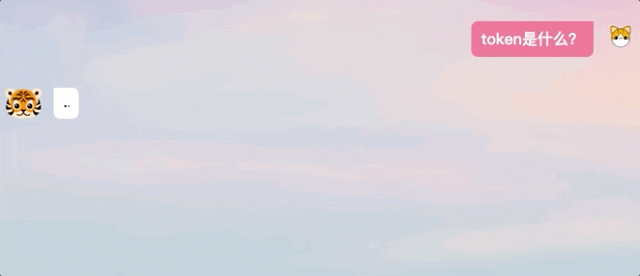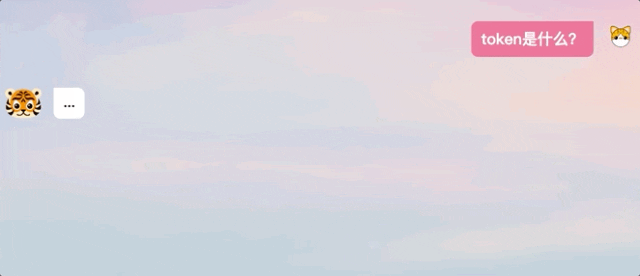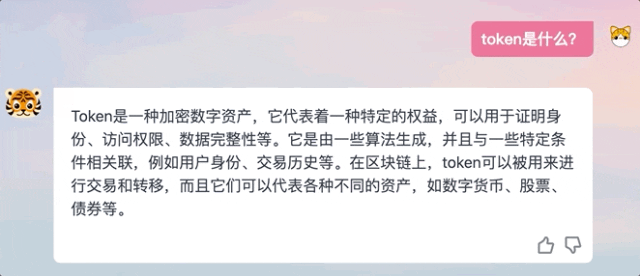
TigerBot の推論速度は非常に速いため、迅速なモデルの書き換えをサポートできます。
ここでは、TigerBot のトレーニングと推論における革新について説明します。
TigerBot チームは、モデルの基礎となるアーキテクチャの最適化を検討することに加えて、現在の大規模モデルの時代ではエンジニアリングのレベルも非常に重要であると考えています。
一方で、これは運用効率を考慮する必要があるためです。大規模なモデルの傾向が続いているため、誰がモデルをより速く反復できるかが非常に重要です。一方で、もちろん、計算能力の経済性も考慮する必要があります。
したがって、並行トレーニングの観点から、彼らはディープスピードなどの主流のフレームワークにおけるいくつかの記憶とコミュニケーションの問題を克服し、キロカロリー環境で数か月間中断のないトレーニングを達成しました。
これにより、毎月のトレーニング費用を数十万ドル節約できます。
最後に、TigerBot は中国語の強い連続性と複数のあいまいさの問題に対処するために、トークナイザーからトレーニング アルゴリズムまで対応する最適化を行いました。
要約すると、TigerBot によって達成された技術革新はすべて、現在の大型モデル分野で最も注目されている領域で発生しています。
これは、基盤となるアーキテクチャの最適化だけでなく、ユーザーのニーズ、間接コスト、実装レベルでのその他の問題も考慮します。また、イノベーションのプロセス全体は非常に速く、10 人程度の小規模なチームによって数か月で実現できます。
これにより、チーム自身の開発能力、技術的な洞察、実装経験に非常に高い要求が課されます。
それでは、TigerBot を突然世間の注目を集めるようにしたのは誰でしょうか?
TigerBot の背後にある開発チームは、実際にはその名前 - HuBo Technology に隠されています。
2017 年に設立され、AI 爆発期の最終段階とよく言われます。
Hubo Technology は、次世代のインテリジェントでシンプルな検索エクスペリエンスを作成するというビジョンを掲げ、NLP テクノロジーの応用に重点を置き、自社を「人工知能テクノロジーによって推進される企業」と位置付けています。
特定の実装パスでは、データ情報に対して最も機密性の高いフィールドの 1 つである 財務を選択しました。垂直分野におけるインテリジェント検索、インテリジェント推奨、機械読解、要約、翻訳などの技術を自社開発し、インテリジェント金融検索および質疑応答システム「Hubo Search」を立ち上げた。
同社の創設者兼 CEO は、世界クラスの AI 科学者である Chen Ye です。

彼はウィスコンシン大学マディソン校で博士号を取得し卒業し、カリフォルニア大学バークレー校の客員教授を務めました。 20年以上も練習を続けています。
彼は、Microsoft、eBay、Yahoo でチーフ サイエンティストや研究開発ディレクターなどの重要な役職を歴任し、Yahoo の行動ターゲティング システム、eBay のレコメンデーション システム、Microsoft の検索広告入札市場メカニズムの開発を主導しました。
2014 年、Chen Ye は Dianping に入社しました。美団点評の合併後は、美団点評の上級副社長としてグループの広告プラットフォームを担当し、グループの年間広告収入が1,000万から40億以上に増加することに貢献した。
学術面では、Chen Ye は 3 つのトップカンファレンス最優秀論文賞 (KDD および SIGIR) を受賞し、SIGKKD、SIGIR、IEEE などの人工知能学会で 20 件の論文を発表し、10 件の特許を取得しています。
2017 年 7 月、Chen Ye は Hubo Technology を正式に設立しました。設立から 1 年後、Hubo はすぐに 1 億元を超える資金調達を獲得し、現在、同社は資金調達総額が 4 億元に達していることを明らかにしました。

ガレージ起業家精神 」モデルに敬意を表しています。
チームには当初 5 人しかいなかったが、Chen Ye は主任プログラマー兼科学者であり、コア コード作業を担当していました。その後、会員数は拡大しましたが、基本的に1ポストにつき1名、10名までとさせていただきました。 ######どうしてこれをやったの? Chen Ye の答えは次のとおりです: 0 から 1 を創造することは非常にマニアックなことだと思います。10 人を超えるオタク チームはありません。 純粋に技術的および科学的な問題だけでなく、小規模なチームの方が鋭敏です。 実際、TigerBot の開発プロセスでは、あらゆる面での決断力と繊細さが明らかになりました。 Chen Ye はこのサイクルを 3 つの段階に分けました。 第 1 段階では、ChatGPT が普及してから間もなく、チームは過去 5 年間に OpenAI やその他の機関から発行されたすべての関連文献を迅速に調べて、ChatGPT の手法とメカニズムを一般的に理解しました。ChatGPT コード自体はオープンソースではなく、関連するオープンソース作品も当時は比較的少なかったため、Chen Ye は戦場に出て TigerBot のコードを書き、その後すぐに実験を開始しました。 。
彼らのロジックは非常に単純です。最初に小規模なデータでモデルが正常に検証され、その後体系的な科学的レビューが行われます。つまり、安定したコードのセットが形成されます。 チームは 1 か月以内に、このモデルが 70 億規模の同規模の OpenAI モデルの効果の 80% を達成できることを検証しました。 第 2 段階では、オープンソース モデルとコードの利点を継続的に吸収し、特に中国のデータを最適化することで、チームは実際の使用可能なモデルのバージョンを迅速に作成しました。最も初期の内部ベータ バージョンがリリースされました。 in 2 今月はオンラインです。 同時に、パラメータの数が数百億レベルに達すると、モデルが創発現象を示すことも発見しました。
第 3 段階、つまりここ 1 ~ 2 か月で、チームは基礎研究である程度の成果と画期的な成果を達成しました。 上で紹介したイノベーションの多くはこの期間中に完了しました。 同時に、より高速な反復速度を達成するために、この段階でより大量の計算能力が統合され、1 ~ 2 週間以内に、TigerBot-7B の能力は InstructGPT の 80% から 96 まで急速に増加しました。 %。 Chen Ye 氏は、この開発サイクル中、チームは常に超効率的な運用を維持していると述べました。 TigerBot-7B は、数か月で 3,000 回の反復を行いました。 少人数チームのメリットは、午前中に確認して午後にはコードを書き終えるなど、対応が早いことです。データ チームは、高品質の清掃作業を数時間で完了できます。 しかし、高速な開発と反復は、TigerBot のオタク スタイルの現れの 1 つにすぎません。なぜなら、彼らは 10 人が数か月で生み出した結果のみに依存しており、それらを完全な API セットの形で業界にオープンソース化するからです。 現在の傾向、特に商用化の分野において、オープンソースをこれほどまでに採用することは比較的まれです。
結局のところ、激しい競争の中で、技術的な障壁を構築することは、営利企業が直面しなければならない問題です。
では、なぜ Hubo Technology はあえてオープンソースを採用するのでしょうか?Chen Ye 氏は 2 つの理由を挙げました。
第一に、AI 分野の技術者として、テクノロジーに対する最も本能的な欲求からです。少し情熱的で、少しセンセーショナル。世界トップクラスの大型モデルで中国のイノベーションに貢献したいと考えています。強固な基盤を備えた使用可能な一般モデルを業界に提供することで、より多くの人々が大規模な専門モデルを迅速にトレーニングし、環境に優しい産業クラスターの構築を実現できるようになります。
第 2 に、TigerBot は高速反復を維持します
.Chen Ye 氏は、このレース状況でもアドバンテージのポジションを維持できると信じています。たとえ誰かが TigerBot をベースにしてよりパフォーマンスの高い製品を開発しているのを見たとしても、これは業界にとって良いことではないでしょうか? Chen Ye 氏は、Hubo Technology が今後も TigerBot の作業を急速に推進し、データをさらに拡張してモデルのパフォーマンスを向上させることを明らかにしました。 「大型モデルのトレンドはまるでゴールドラッシュ」
ChatGPTのリリースから半年、次々と大型モデルが登場し、巨人の急速な追撃が続くなか、 AI 業界の状況は変化しており、急速に再発明されています。
モデル層は基礎となる機能を決定します。これは非常に重要です。
その革新性、安定性、オープン性の度合いが、アプリケーション層の充実度に直接影響します。
アプリケーション層の発展は、大規模モデルのトレンドの進化の外面的な現れであり、AIGC ビジョンにおける人間の社会生活の次の段階に影響を与える重要な要素でもあります。
したがって、大きなモデルのトレンドの出発点において、基礎となるモデルの基盤をどのように強化するかは、業界が考えなければならないことです。
Chen Ye 氏の見解では、人間は大型モデルの可能性の 10 ~ 20% しか開発できておらず、基本的なレベルでは革新と改善の余地がまだたくさんあります。
西洋のゴールドラッシュと同じように、当初の目的は金鉱山がどこにあるのかを見つけることでした。したがって、このような傾向と業界の発展要件の下で、Hubo Technologyは国内分野のイノベーションの代表として、オープンソースの旗を高く掲げ、迅速にスタートし、世界で最も最先端の技術に追いつきます。最先端の技術を駆使し、業界に利益をもたらしている独特の雰囲気があります。 国内のAIイノベーションは急速に進んでおり、将来的には、大規模モデルの分野に新たな洞察を注入し、新たな変化をもたらすアイデアと能力を持ったチームがさらに登場すると思います。
そして、これがこのトレンドの精力的な進化の最も魅力的な部分かもしれません。
福利厚生:
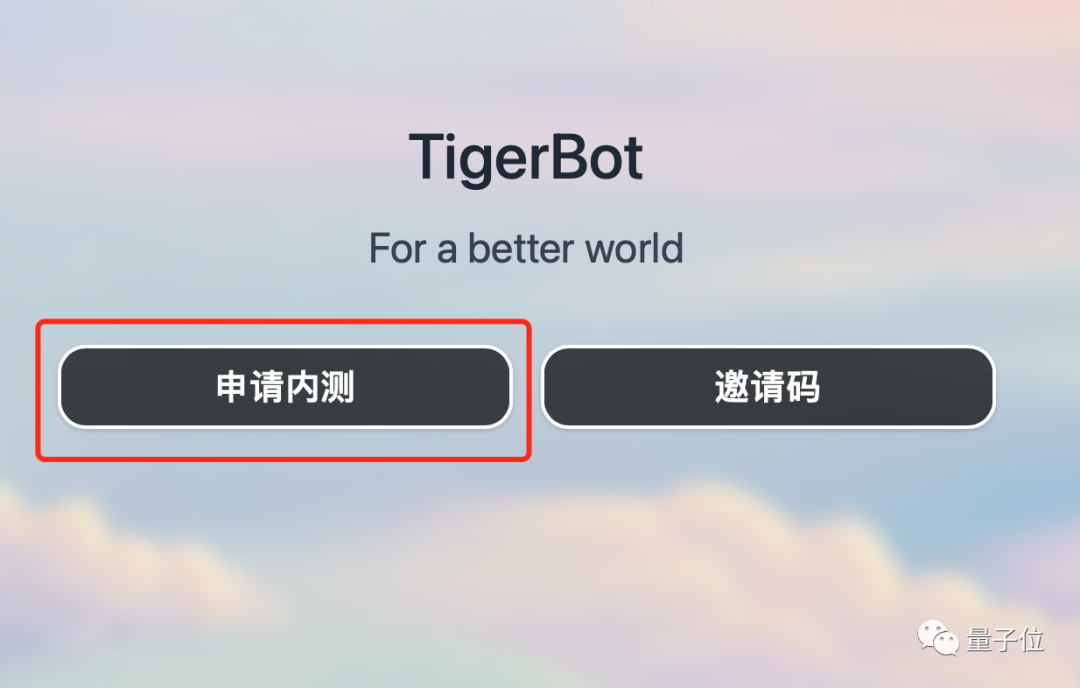
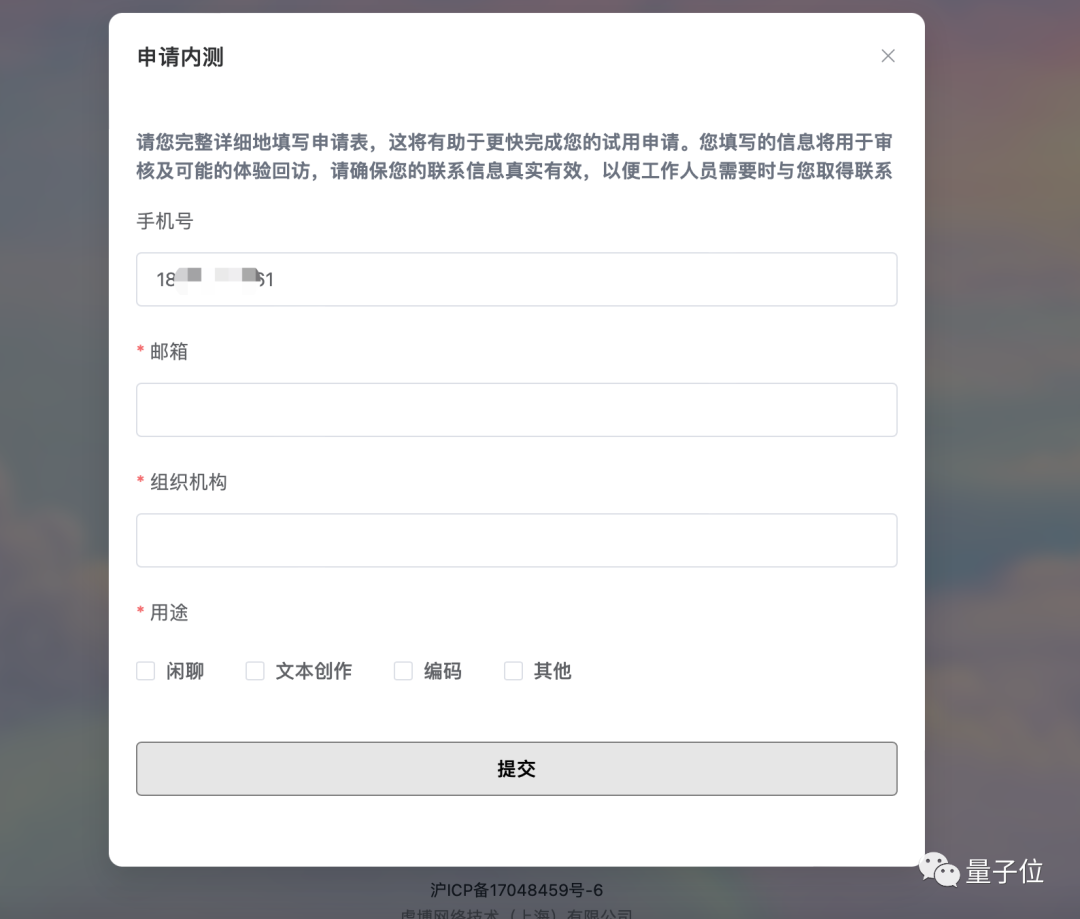
TigerBot の子供用シューズを体験したい場合は、下のリンクから Web サイトにアクセスするか、[原文を読む] をクリックして、[内部ベータ版に申し込む] をクリックしてください。組織コードに「Qubit」と記述すると、内部テストに合格できます~
#GitHub オープンソース アドレス: https://github.com/TigerResearch/TigerBot
以上がその効果は同スケールの OpenAI モデルの 96% に達し、リリース時にはオープンソース化されています。国内チームが新型大型モデルをリリース、CEOがコード書きに参戦の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



