


ChatGPT が今でも愚かな間違いを犯すとは思いませんでしたか?
マスター Andrew Ng は最新のクラスでこのことを指摘しました:
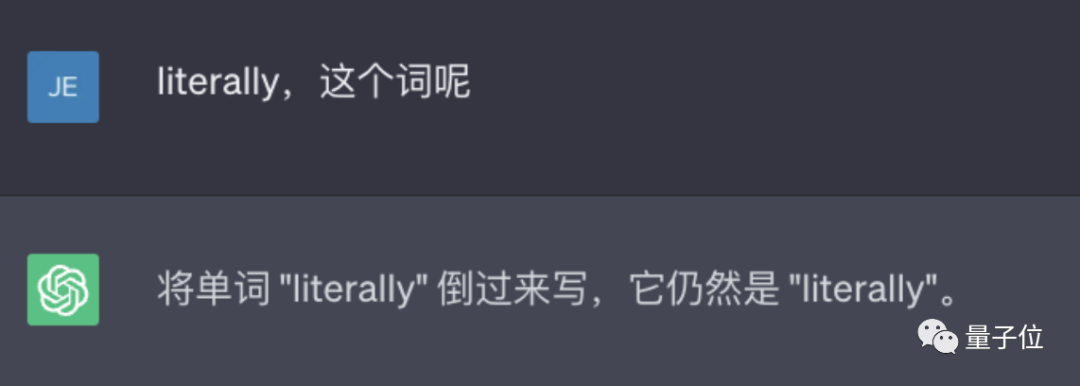
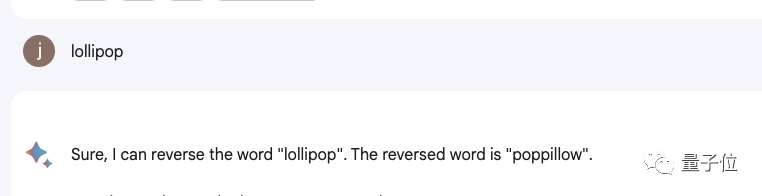
ChatGPT は単語を反転させません。
たとえば、lollipop という単語を逆にすると、出力は pilollol となり、完全に混乱を招きます。


 #△実測値バード
#△実測値バード
 △実測値ウェンXinyi Yan
△実測値ウェンXinyi Yan
#え?どうしてこれなの? 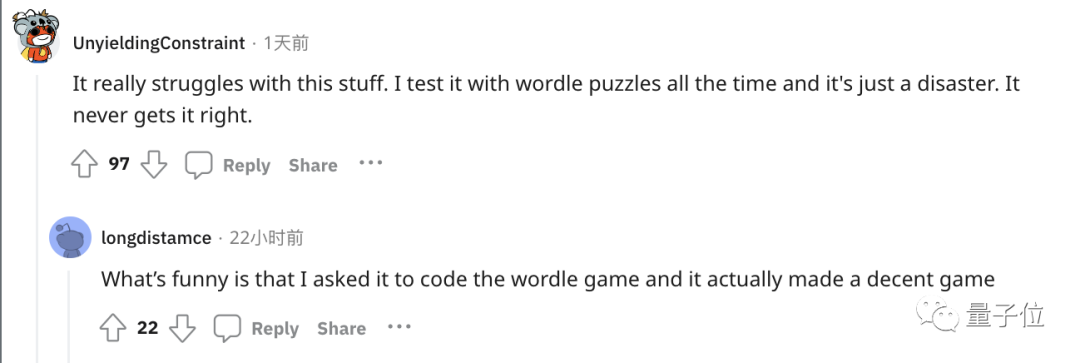
この現象の鍵はトークンにあります。トークンはテキスト内で最も一般的な文字シーケンスであるため、大規模なモデルではテキストの処理にトークンが使用されることがよくあります。
したがって、単語を反転するという小さなタスクを扱うときは、文字の代わりに各トークンをひっくり返すだけかもしれません。
これは中国語の文脈ではさらに明らかです。単語はトークンであるか、単語はトークンです。 
冒頭の例に関しては、誰かが ChatGPT の推論プロセスを理解しようとしました。 
より直感的に理解できるように、OpenAI は GPT-3 Tokenizer もリリースしました。 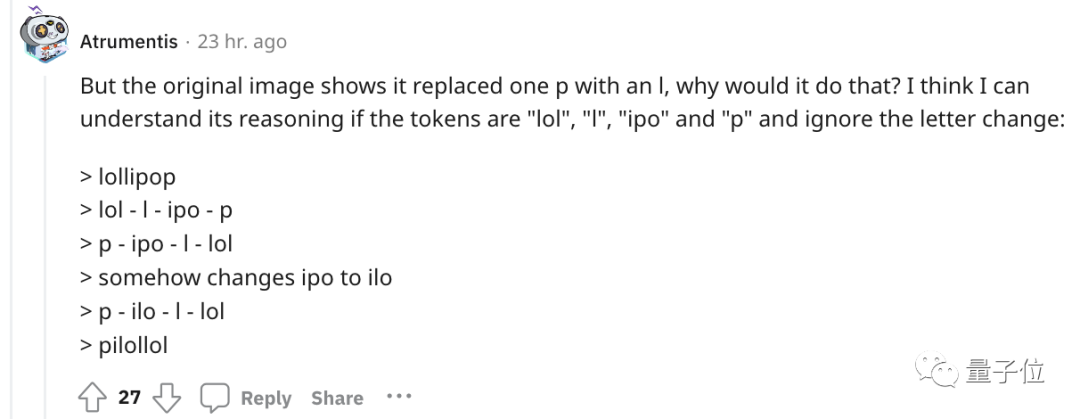
たとえば、lollipop という単語は、GPT-3 では I、oll、ipop の 3 つの部分として理解されます。 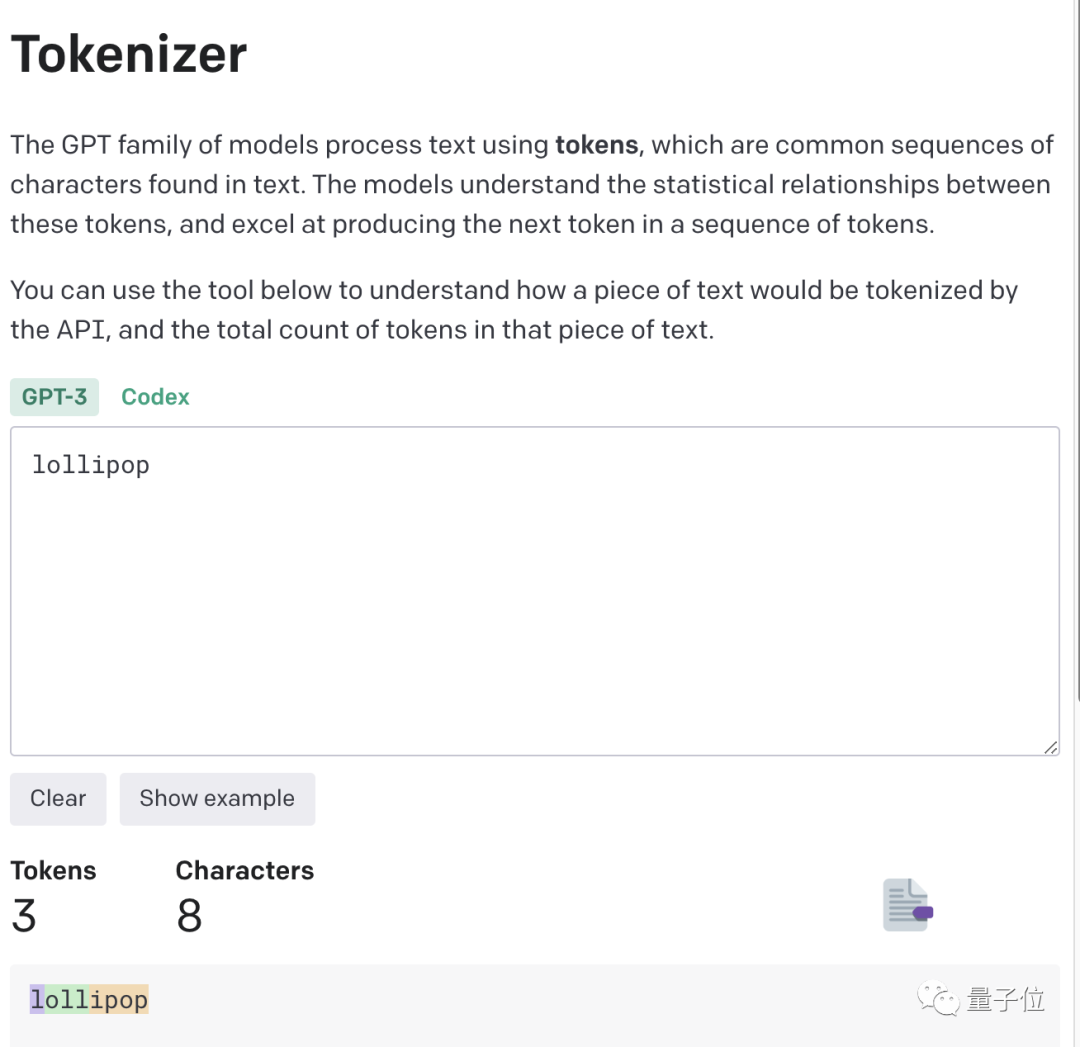
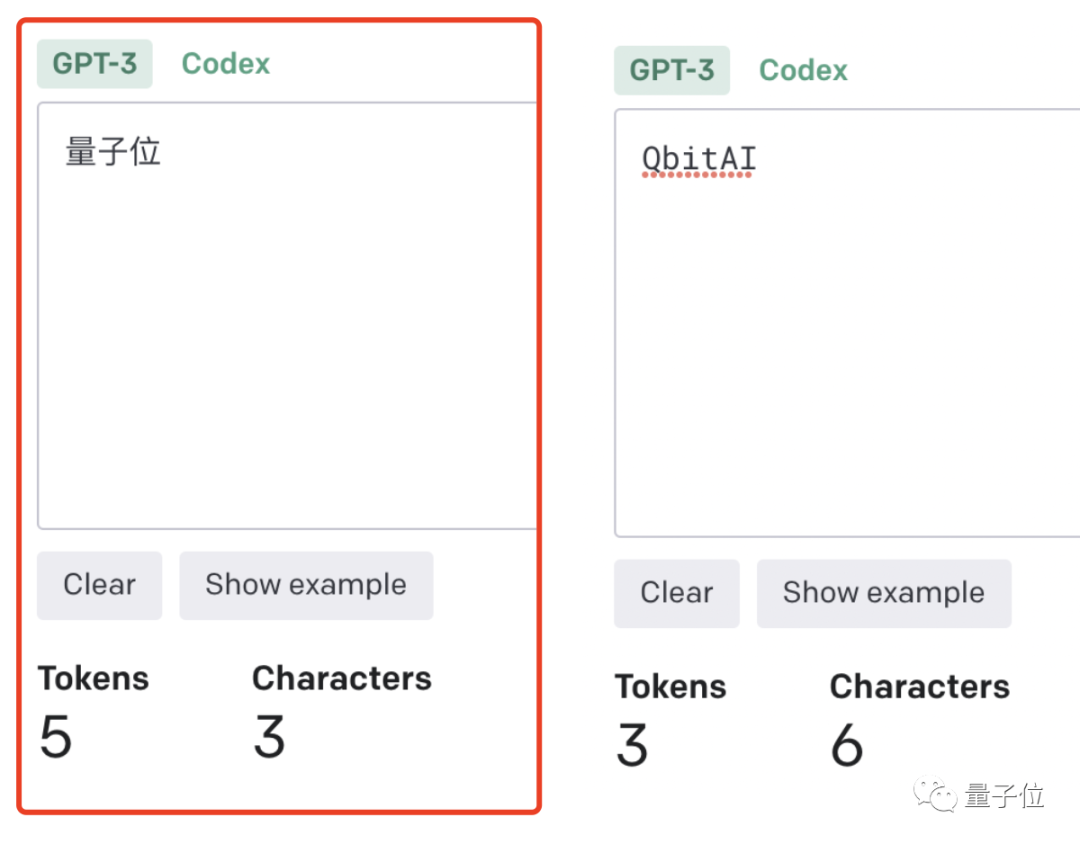
トークン対文字 (トークン対単語) の比率が高くなるほど、処理コストも高くなります。したがって、中国語のトークン化の処理は英語よりもコストが高くなります。
トークンは、大規模なモデルが人間の現実世界を理解するための手段であることが理解できます。これは非常にシンプルで、メモリと時間の複雑さが大幅に軽減されます。
しかし、単語のトークン化には問題があり、モデルが意味のある入力表現を学習することが困難になります。最も直感的な表現は、単語の意味を理解できないことです。
当時、Transformers は対応する最適化を行っていました。たとえば、複雑で一般的ではない単語は、意味のあるトークンと独立したトークンに分割されました。
「迷惑」が「迷惑」と「嘘」の 2 つの部分に分かれているのと同じように、前者は独自の意味を保持し、後者はより一般的です。
これは、人間の言語を非常によく理解できる、今日の ChatGPT やその他の大型モデル製品の驚くべき効果にもつながりました。
単語の反転などの小さなタスクを処理できないことについては、当然解決策があります。
最も簡単で直接的な方法は、自分で単語を分割することです~

または、ChatGPT に段階的に実行させることもできます, まず各文字をトークン化します。

あるいは、文字を反転するプログラムを作成させれば、プログラムの結果は正しくなります。 (犬頭)


トークンを増やすことでモデルの思考を改善できるようになります。

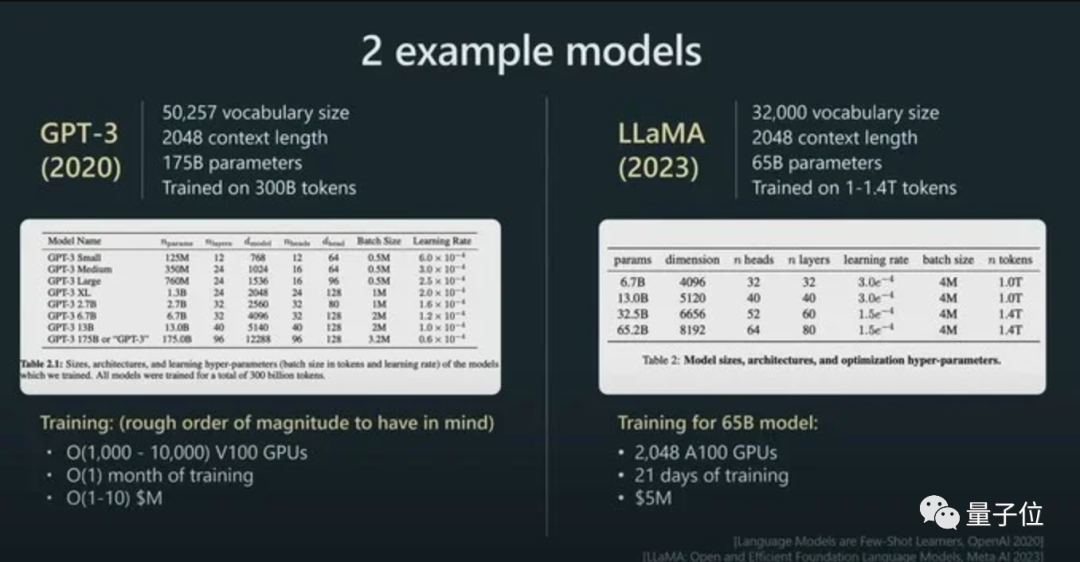
つまり、AI の大規模モデルの分野に足を踏み入れると、トークンが避けられない知識ポイントであることがわかります。
まあ、トークン文献さえ派生しています...
しかし、トークンがどのような役割を果たしているかについては言及する価値があります。中国語圏では何と訳すべきかはまだ完全に決まっていません。
「トークン」の直訳はいつも少し奇妙です。
GPT-4 では、「単語要素」または「タグ」と呼ぶ方がよいと考えていますが、どう思いますか?

参考リンク:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
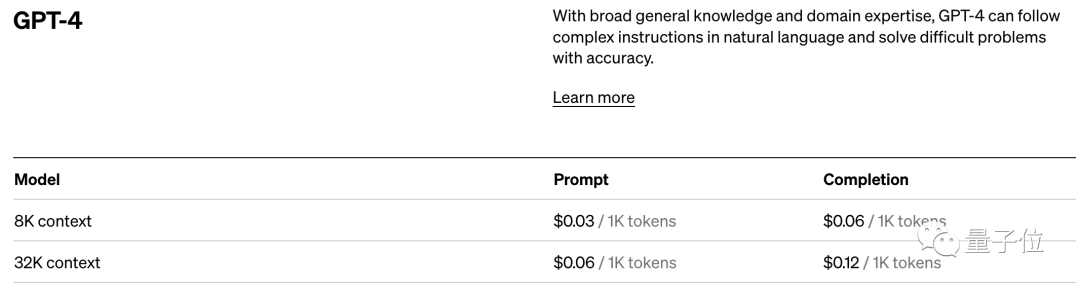
[3]https://openai.com /価格
以上がAndrew Ng の ChatGPT クラスが話題になりました: AI は単語を逆から書くことをやめましたが、世界全体を理解しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



