


しかし、ユーザー レベルが上がり、書き込みリクエストがますます増えた場合、データベースの負荷を十分に確保するにはどうすればよいでしょうか?マスターを追加しても問題は解決できません。データの一貫性が必要であり、書き込み操作には 2 つのマスター間の同期が必要であり、これは複製に相当し、アーキテクチャ設計がより複雑になります。
現時点では、サブデータベースのパーティショニング テーブル (シャーディング) を使用し、ライブラリとテーブルを異なる MySQL サーバーに保存する必要があり、各サーバーは書き込みリクエストの数のバランスを取ることができます
2. 大きすぎるライブラリ テーブルによって引き起こされる問題
単一テーブルが大きすぎます: CURD 効率が非常に低いです。
データ量が多すぎるため、インデックス ファイルが大きくなりすぎ、ディスク IO のロードに時間がかかります。インデックスが削除され、クエリ タイムアウトが発生します。したがって、インデックスを使用するだけでは十分ではなく、単一のテーブルをより小さなデータ セットを含む複数のテーブルに分割する必要があります。 MyCat が提供するテーブル分割アルゴリズムはすべて Rule.xml に含まれており、時間に基づく分割、コンシステント ハッシュ、主キーを直接使用して分割テーブルの数を剰余するなど、さまざまなテーブル分割アルゴリズムに従って分割できます。分割戦略
If テーブルが多すぎるためにデータが多すぎる場合は、垂直分割を使用します。つまり、ビジネスに応じてデータを異なるライブラリに分割します。 1 つのテーブル内のデータ量が大きすぎる場合は、水平分割を使用します。 分割、つまり、特定のルールに従ってテーブル データを複数のテーブルに分割します (テーブル分割アルゴリズムはルールで定義されています。最初に垂直分割を検討し、次に水平分割を検討します
#サブデータベース、サブテーブル、読み書き分離は一緒に実行できます
##1 . 垂直サブライブラリ<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
mytest1 と mytest2 は、異なるマシン上の異なるライブラリに分割されており、それぞれにパーツが含まれています 元々は 1 つのマシンに統合されていたテーブルが、現在は垂直に分割されています。
クライアントは異なる論理ライブラリに接続する必要があります。業務運用に応じて異なる論理ライブラリが使用されます。次に、2 つの書き込みライブラリが構成され、2 台のマシンが使用されます。ライブラリを保存します。均等に分割され、元の単一マシンの圧力を共有します。データベース シャーディングにはテーブル シャーディングが伴い、テーブルはビジネスの観点から分割されます
2.垂直テーブル シャーディング
垂直テーブル シャーディングは列フィールドに基づいています。通常、クエリ中に大量のデータが原因で発生する「クロスページ」問題を回避するために、数百の列を持つ大きなテーブルに使用されます。
一般に、テーブルには多くのフィールドがあり、一般的に使用されない、データが大きい、長いフィールド (テキスト タイプ フィールドなど) は拡張テーブルに分割されます。アクセス頻度の高いフィールドは別のテーブルに配置されます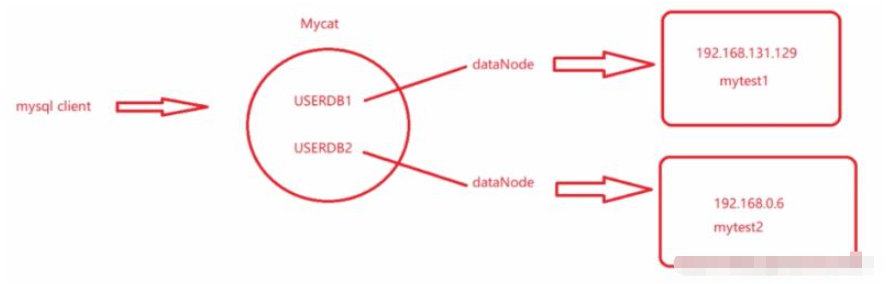
膨大な量のデータを含む単一のテーブル (注文テーブルなど) の場合、特定のルール (RANGE、HASH 係数など) に従って複数のテーブルに分割されます。テーブルがまだ同じデータベース内にあるため、データベース全体に対する操作を実行する際に IO ボトルネックが発生する可能性があるため、推奨されません。
単一テーブルのデータを複数のサーバーに分散し、各サーバーがテーブルの一部を所有します。とライブラリですが、テーブル内のデータ収集が異なります。サブデータベースとサブテーブルのテクノロジーを適用すると、単一マシンと単一データベースのパフォーマンスのボトルネックとプレッシャーを効果的に軽減でき、IO、接続数、ハードウェア リソースなどに関連する制限も突破できます。
サブデータベーステーブルのシャーディングはマスター/スレーブレプリケーションと同時に実行できますが、マスター/スレーブレプリケーションに基づいていません。読み取り/書き込みの分離はマスター/スレーブレプリケーションに基づいています
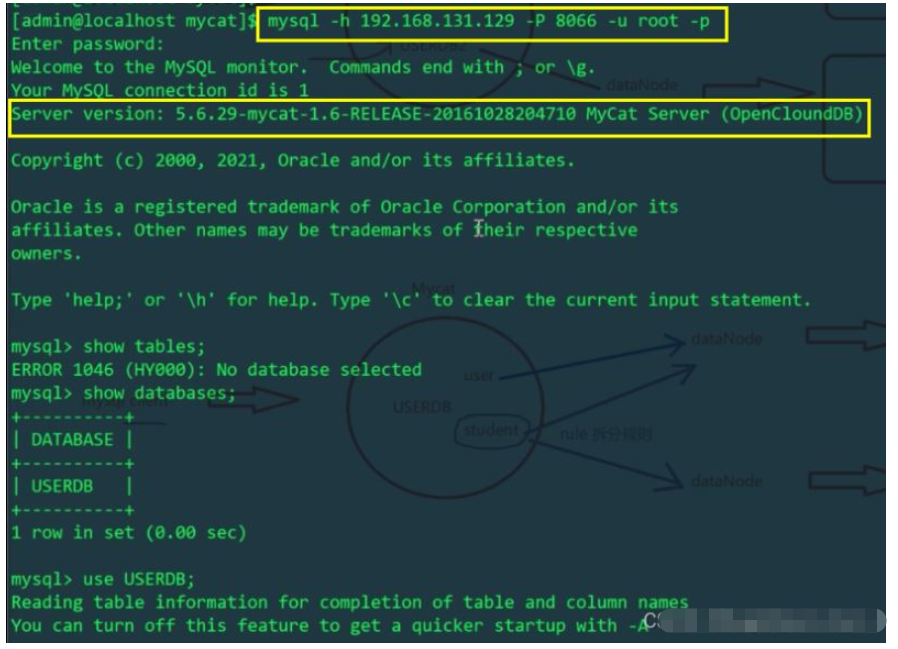
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB</property> </user>
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="user" dataNode="dn1" /> <!-- 这里的user和student都是实际存在的物理表名 --> <table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/> </schema> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
user は通常のテーブルを表し、データ ノード dn1 に直接配置され、マシンです。このテーブルは分割する必要はありません。
student テーブル PrimaryKey は ID です。ID に従って分割され、dn1 と dn2 に配置されます。最終的に、このテーブルは 2 つに分割されますこれらのマシンは物理的には分離されていますが、論理的には依然として 1 つです。どのテーブルに追加する必要がありますか? 2 で、各マシンでこれらの操作をクエリおよびマージする方法は、mycat によって完了します。
分割ルールは、モジュロ (mod - long) であり、各挿入では ID モジュロ (2) に存在するマシンの数が使用されますさらに、rule.xml
で次の分割アルゴリズムを構成する必要があります。アルゴリズム mod-long を見つけます。論理テーブル Student を 2 つのホストに個別にマッピングするため、変更されたデータ ノードの数は 2

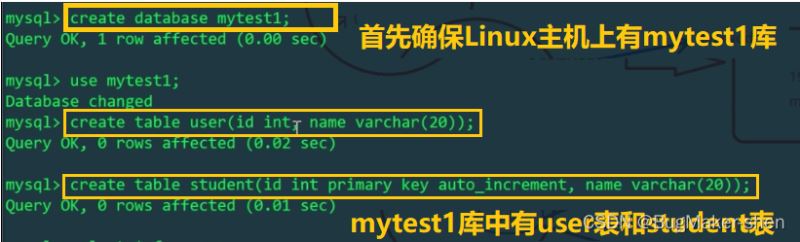
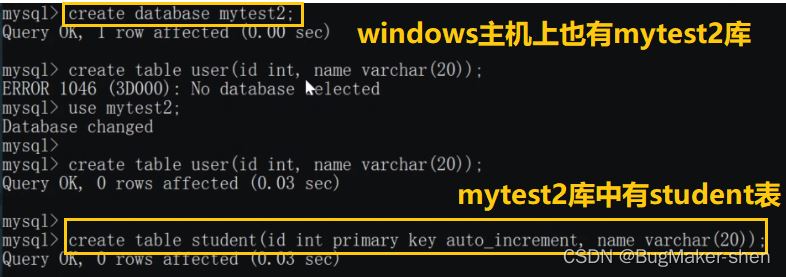
2 です。テスト レベル Sub -table
Linux ホスト
 ##mycat の 8066 ポートにログインします
##mycat の 8066 ポートにログインします
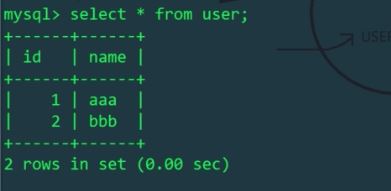
 MyCat を使用してユーザー テーブルに 2 つのデータを挿入します
MyCat を使用してユーザー テーブルに 2 つのデータを挿入します
 schema.xml 構成ファイルでは、論理テーブル ユーザーは Linux ホストの mytest1 ライブラリにのみ存在します mycat によって操作される論理テーブル ユーザーは、Linux ホスト上の物理テーブルに影響しますが、Windows ホスト上のテーブルには影響しません。 Linux ホストと Windows ホストのユーザー テーブルをそれぞれ表示します。
schema.xml 構成ファイルでは、論理テーブル ユーザーは Linux ホストの mytest1 ライブラリにのみ存在します mycat によって操作される論理テーブル ユーザーは、Linux ホスト上の物理テーブルに影響しますが、Windows ホスト上のテーブルには影響しません。 Linux ホストと Windows ホストのユーザー テーブルをそれぞれ表示します。
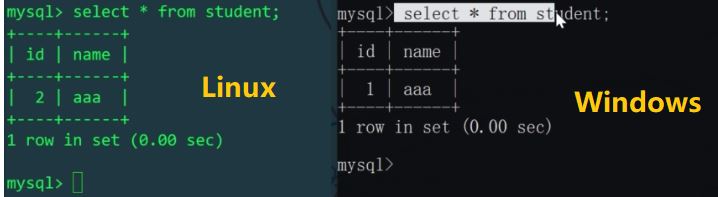
 次に、MyCat を通じて Student テーブルに 2 つのデータを挿入します。
次に、MyCat を通じて Student テーブルに 2 つのデータを挿入します。
 schema.xml 構成ファイルでは、論理テーブル Student が 2 つのホスト上の 2 つのライブラリ mytest1 および mytest2 内の 2 つのテーブルに対応していることがわかっています。論理テーブルに挿入されたデータは、実際には 2 つの物理テーブルに影響します (どの物理テーブルに挿入するかを決定するには、
schema.xml 構成ファイルでは、論理テーブル Student が 2 つのホスト上の 2 つのライブラリ mytest1 および mytest2 内の 2 つのテーブルに対応していることがわかっています。論理テーブルに挿入されたデータは、実際には 2 つの物理テーブルに影響します (どの物理テーブルに挿入するかを決定するには、
を使用します)。 Linux ホストと Windows ホストの Student テーブルをそれぞれ確認してみましょう:
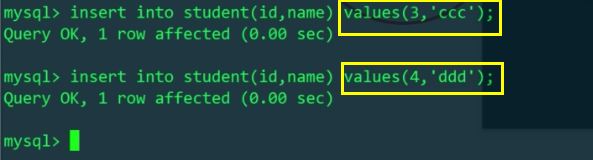
 次に、MyCat を介して id=3 と id=4 のデータを挿入します。これらは別の物理テーブルに挿入される必要があります。
次に、MyCat を介して id=3 と id=4 のデータを挿入します。これらは別の物理テーブルに挿入される必要があります。
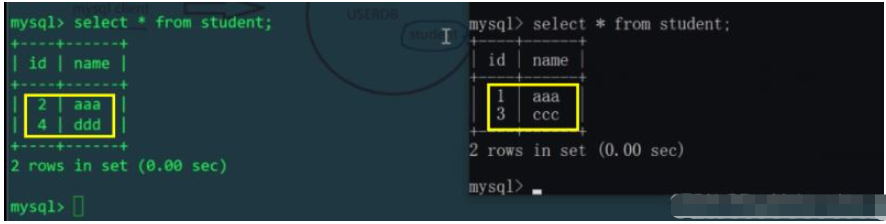 これは、student テーブルを水平方向に分割するのと同じです。
これは、student テーブルを水平方向に分割するのと同じです。
MyCat を通じてクエリを実行する場合、通常 入力するだけです。テーブルを分割してこれら 2 つのデータ ノードに配置するように設定しました。MyCat は、設定に従って 2 つのデータベース上のデータをクエリおよびマージします。
以上がMySQLサブデータベースとサブテーブルの分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



