


(1) クエリ効率の向上 (IO 使用量の削減)
(2) CPU 使用量の削減rate
たとえば、age desc による順序のクエリを実行すると、B インデックス ツリー自体がソートされているため、クエリによってインデックスがトリガーされた場合、再度クエリを実行する必要はありません。
(1) インデックス自体は大きく、メモリまたはハードディスク (通常はハードディスク) に保存できます。
(2) インデックスは、①データ量が少ない、②頻繁に変更されるフィールド、③ほとんど使用されないフィールドなど、すべての状況で使用されるわけではありません。
(3) インデックスは追加の効率を低下させます。削除と変更
(1) 単一値インデックス
(2) 一意のインデックス
(3) ) ユニオン インデックス
(4) 主キー インデックス
注: 一意インデックスと主キー インデックスの唯一の違い: 主キー インデックスを null にすることはできません
alter table user add INDEX `user_index_username_password` (`username`,`password`)
MySQL インデックスの基礎となるデータ構造は B ツリーです
B Tree is in B- Tree に基づいた最適化により、外部ストレージ インデックス構造の実装により適しています。InnoDB ストレージ エンジンは、B Tree を使用してインデックス構造を実装します。
B ツリー構造図の各ノードには、データのキー値だけでなくデータ値も含まれています。各ページの記憶容量は限られており、データデータが大きい場合、各ノード (つまり 1 ページ) に保存できるキーの数は非常に少なくなります。 to B- ツリーの深さが大きくなり、クエリ中のディスク I/O の数が増加し、クエリの効率に影響します。 B Treeでは、すべてのデータレコードノードがキー値順に同じ階層のリーフノードに格納され、非リーフノードにはキー値情報のみが格納されるため、各ノードに格納されるキー値の数を大幅に増やすことができます。 . B ツリーの高さを下げます。
B ツリーには、B ツリーと比較していくつかの違いがあります。
非リーフ ノードはキー値情報のみを保存します。
すべてのリーフ ノード間にリンク ポインタがあります。
データ レコードはリーフ ノードに保存されます。
前節でB-Treeを最適化します。B Treeの非リーフノードはキー値情報のみを格納するため、各ディスクブロックに4つのキー値とポインタ情報を格納できると仮定すると、 の構造になります。 B ツリー: 以下の図に示すように:
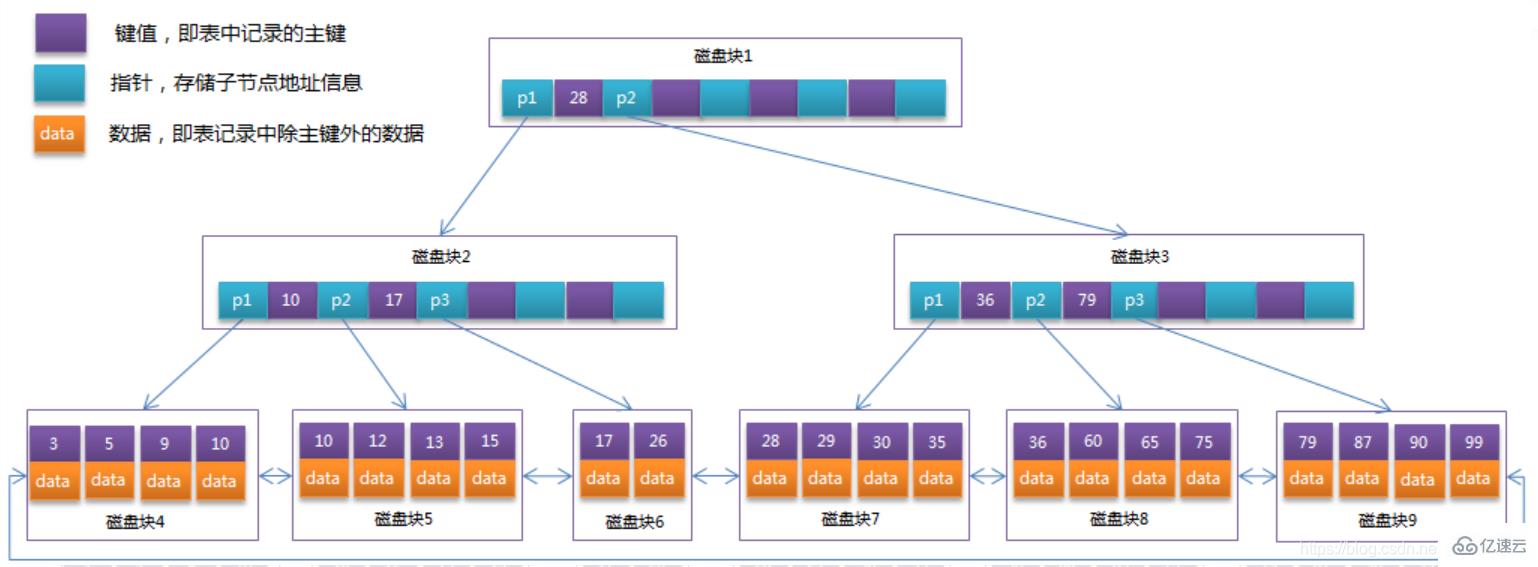
通常、B ツリーには 2 つのヘッド ポインタがあり、1 つはルート ノードを指し、もう 1 つはリーフ ノードを指します。最小のキーワードとすべてのリーフ ノードを使用します (つまり、データ ノード間にチェーン リング構造があります)。したがって、B Tree では、主キーの範囲検索とページング検索、およびルート ノードから開始するランダム検索の 2 つの検索操作を実行できます。
おそらく、上記の例ではデータ レコードが 22 しかなく、B Tree の利点がわかりません。計算は次のとおりです:
InnoDB ストレージ エンジンのページ サイズは 16KB、一般テーブルの主キーのタイプは INT (4 バイトを占有) または BIGINT (8 バイトを占有) で、ポインタのタイプは通常 4 または 8 バイトです。つまり、1 ページ (B ツリーのノード) には約16KB/( 8B 8B) = 1K のキー値 (推定なので、計算を容易にするため、ここでの K の値は 〖10〗^3 です)。つまり、深さ 3 の B ツリー インデックスは、10^3 * 10^3 * 10^3 = 10 億レコードを維持できます。
実際の状況では、各ノードが完全に埋まっていない可能性があるため、データベースでは、B ツリーの高さは通常 2 ~ 4 レベルになります。 MySQL の InnoDB ストレージ エンジンは、ルート ノードがメモリ内に常駐するように設計されています。つまり、特定のキー値の行レコードを見つけるのに必要なディスク I/O 操作は 1 ~ 3 回だけです。
データベースの B ツリー インデックスは、クラスター化インデックス (クラスター化インデックス) と補助インデックス (セカンダリ インデックス) に分類できます。上記の B ツリーの例の図は、クラスター化インデックスとしてデータベースに実装されており、クラスター化インデックスの B ツリー内のリーフ ノードには、テーブル全体の行レコード データが格納されます。補助インデックスとクラスター化インデックスの違いは、補助インデックスのリーフ ノードには行レコードのすべてのデータが含まれるのではなく、対応する行データを格納するクラスター化インデックス キー、つまり主キーが含まれることです。セカンダリ インデックスを通じてデータをクエリする場合、InnoDB ストレージ エンジンはセカンダリ インデックスを走査して主キーを見つけ、その後主キーを通じてクラスター化インデックス内の完全な行レコード データを見つけます。
以上がMySQL でのインデックスの用途は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



