


ChatGPT は、リリース以来、その数学的能力について批判されてきました。
「数学の天才」テレンス・タオですら、GPT-4 は自分の専門分野である数学に大きな価値をもたらすものではないとかつて述べました。
ChatGPT を「数学的遅れ」にしておいて、どうすればよいでしょうか?
OpenAI は懸命に取り組んでいます - GPT-4 の数学的推論機能を向上させるために、OpenAI チームは「プロセス監視」(PRM) を使用してモデルをトレーニングしています。
ステップバイステップで確認してみましょう。

論文アドレス: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step .pdf
論文では、研究者らは、正しい最終結果 (結果の監視) だけを評価するのではなく、「プロセスの監視」として知られる正しい推論の各ステップに報酬を与えることで、数学的問題解決においてより良い結果が得られるようにモデルをトレーニングしました。 ).最新のSOTA。
具体的には、PRM は MATH テスト セットの代表的なサブセットの問題の 78.2% を解決しました。

# さらに、OpenAI は、調整において「プロセス監視」が非常に価値があることを発見しました。これは、認識される思考の連鎖を生成するようにモデルをトレーニングすることです。人間。
最新の研究は、Sam Altman 氏の「私たちの Mathgen チームはプロセス監視において非常に刺激的な結果を達成しました。これは調整の前向きな兆候です。」を推進するためには、もちろん不可欠です。
 実際には、「プロセス監視」には手動によるフィードバックが必要ですが、大規模なモデルやさまざまなタスクでは非常にコストがかかります。したがって、この研究は非常に重要であり、OpenAI の今後の研究の方向性を決定すると言えます。
実際には、「プロセス監視」には手動によるフィードバックが必要ですが、大規模なモデルやさまざまなタスクでは非常にコストがかかります。したがって、この研究は非常に重要であり、OpenAI の今後の研究の方向性を決定すると言えます。
#この図は、最終的に正しい回答となった選択された解決策の割合を、検討された解決策の数の関数として示しています。 
これは、「プロセス監視」報酬モデルがより信頼できることを示しています。
以下、OpenAI は、モデルに関する 10 の数学的問題と解決策、および報酬モデルの長所と短所についてのコメントを示します。 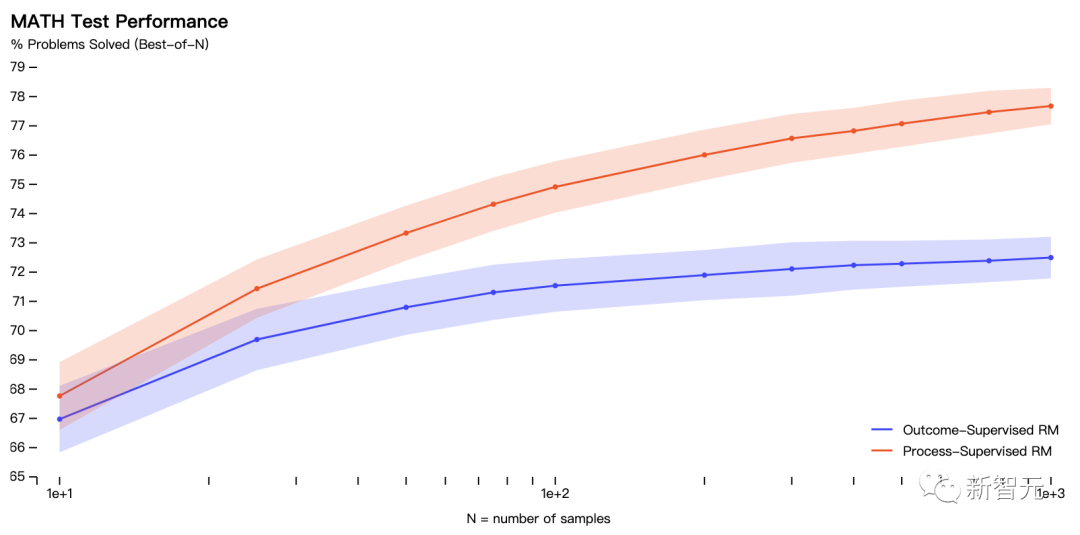
真 (TP) 
しかし、実際に役立つ ID を選択するのは難しいため、解決策のほとんどの試みは失敗します。
GPT-4 は一般にこの問題の解決に失敗し、正しい答えに到達しようとする解決策は 0.1% のみですが、報酬モデルはこの解決策が有効であると正しく識別します。

ここで、GPT-4 は一連の複雑な多項式因数分解を正常に実行します。
ステップ 5 で Sophie-Germain ID を使用することは重要なステップです。このステップは非常に洞察力に富んだものであることがわかります。

ステップ 7 と 8 で、GPT-4 は推測とチェックの実行を開始します。
これは、モデルが「幻覚」を起こし、特定の推測が成功したと主張できる一般的な場所です。この場合、報酬モデルは各ステップを検証し、思考の連鎖が正しいかどうかを判断します。

モデルは、式を簡素化するためにいくつかの三角恒等式を適用することに成功しました。

ステップ 7 で、GPT-4 は式を単純化しようとしますが、失敗します。報酬モデルがこのバグを捕捉しました。

ステップ 11 で、GPT-4 は単純な計算エラーを犯しました。報酬モデルでも発見されました。


報酬モデルはこのエラーを修正します。



 #GPT-4 は、ステップ 9 で微妙なカウント エラーを犯しました。
#GPT-4 は、ステップ 9 で微妙なカウント エラーを犯しました。
表面上、同じ色のボールを交換する方法は 5 つある (色が 5 つあるため) という主張は合理的であるように思えます。
ただし、ボブには 2 つの選択肢 (つまり、どのボールをアリスに渡すかを決定する) があるため、このカウントは 2 の係数で過小評価されます。報酬モデルはこのエラーによって騙されます。

大規模な言語モデルは、複雑な推論機能の点で大幅に向上しましたが、最も先進的なモデルであっても、依然として論理的なエラーやナンセンスが発生し、これは「幻想」と呼ばれることがよくあります。
生成型人工知能の流行の中で、大規模な言語モデルの幻想が常に人々を悩ませてきました。
マスク氏は、「我々に必要なのはTruthGPTだ」と述べました
たとえば、最近、アメリカ人弁護士がニューヨーク連邦裁判所に訴訟を起こしました。 ChatGPTの捏造事件を引用しており、制裁を受ける可能性がある。
OpenAI 研究者はレポートの中で次のように述べています:「単純な論理エラーがソリューション全体に大きな損害を与える可能性があるため、これらの錯覚は複数ステップの推論を必要とする分野で特に問題となります。」
さらに、幻覚を軽減することも、一貫した AGI を構築するための鍵となります。
大きなモデルの錯覚を軽減するにはどうすればよいですか?一般に、プロセス監視と結果監視の 2 つの方法があります。
「結果監視」はその名のとおり、最終結果に基づいて大規模モデルにフィードバックを与えるのに対し、「プロセス監視」は思考連鎖の各ステップに対してフィードバックを与えることができます。

プロセス監視では、大規模なモデルは、正しい最終結論だけでなく、正しい推論ステップに対しても報酬を与えられます。このプロセスにより、モデルはより人間に近い思考方法の連鎖に従うようになり、より説明可能な AI を作成する可能性が高くなります。
OpenAIの研究者らは、プロセス監視はOpenAIが発明したものではないが、OpenAIはそれを推進するために懸命に取り組んでいると述べた。
最新の研究では、OpenAI は「結果監視」または「プロセス監視」の両方の方法を試しました。そして、MATH データセットをテストプラットフォームとして使用して、2 つの方法の詳細な比較が行われます。
その結果、「プロセス監視」によってモデルのパフォーマンスが大幅に向上することがわかりました。
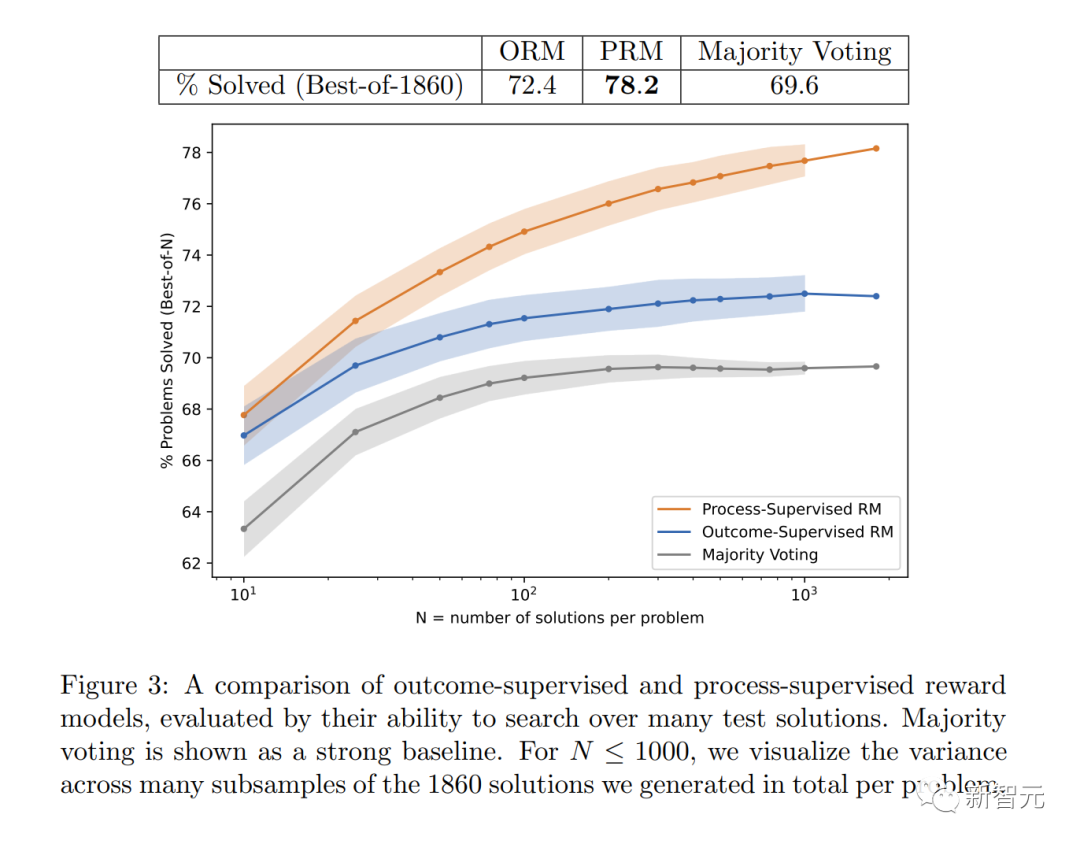
数学的タスクの場合、プロセス監視は大規模なモデルと小規模なモデルの両方で大幅に優れた結果を生成しました。これは、モデルが一般的に正しいことを意味し、また、より人間らしい思考プロセス。
このようにして、最も強力なモデルであっても回避するのが難しい錯覚や論理エラーを減らすことができます。
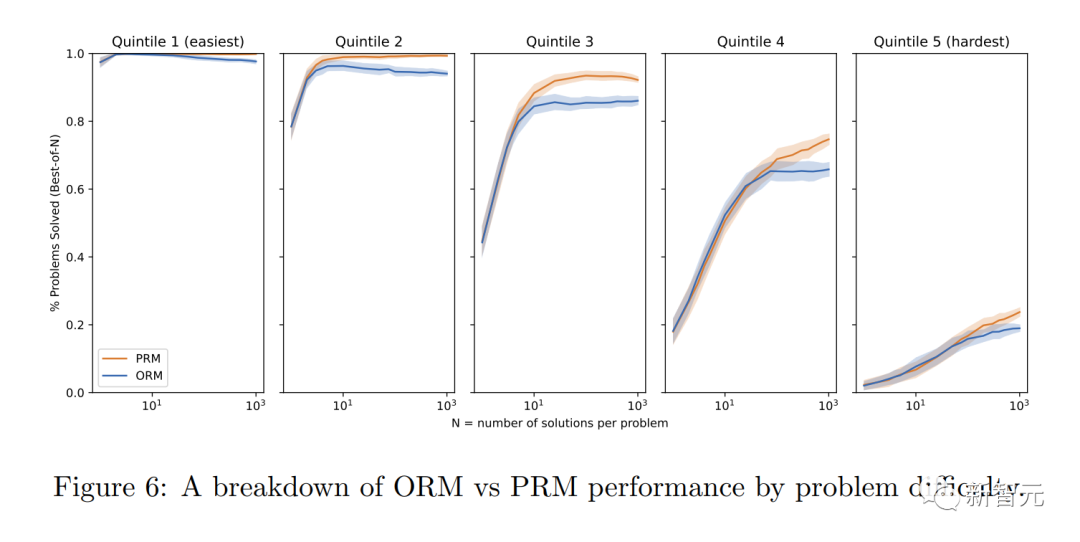
研究者らは、「プロセスの監視」には「結果の監視」に比べて調整の利点がいくつかあることを発見しました。
· プロセスの各ステップが正確に監視されるため、直接的な報酬は一貫した思考連鎖モデルに従います。
· 「プロセス監視」により、モデルが人間の承認したプロセスに従うことが奨励されるため、説明可能な推論が生成される可能性が高くなります。対照的に、結果のモニタリングでは一貫性のないプロセスが評価される可能性があり、レビューがより困難になることがよくあります。
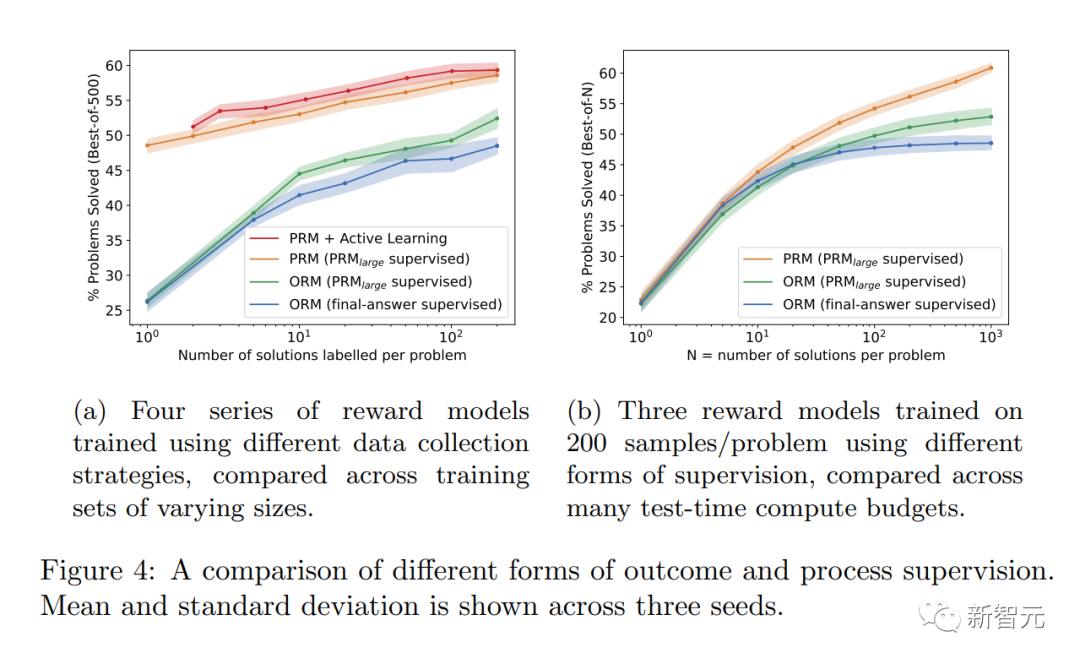
AI システムをより安全にする方法によっては、場合によってはパフォーマンスの低下が生じる可能性があることにも言及する価値があります。この費用は「調整税」と呼ばれます。
一般的に、「調整税」のコストは、最も機能的なモデルを導入するための調整方法の採用を妨げる可能性があります。
しかし、以下の研究者らの結果は、「プロセス監視」が数学領域のテスト中に実際に「負の調整税」を生み出すことを示しています。
調整による大きなパフォーマンスの低下はないと言えます。
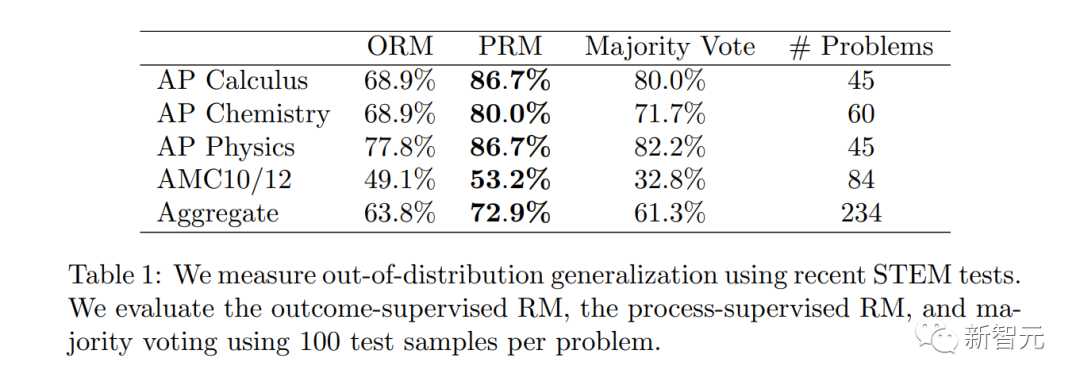
PRM にはさらに多くの人による注釈が必要であることは注目に値します。そうしないと、深くできないのです。 RLHFなしで生きてください。
プロセス監視は数学以外の分野にどの程度適用できますか?このプロセスにはさらなる調査が必要です。
OpenAI 研究者は、このヒューマン フィードバック データ セット PRM を公開しました。これには、800,000 のステップレベルの正しい注釈が含まれています: 12,000 の数学問題から生成された 75,000 のソリューション

アノテーションの例を以下に示します。 OpenAI は、プロジェクトのフェーズ 1 と 2 で、アノテーターへの指示とともに生のアノテーションをリリースします。
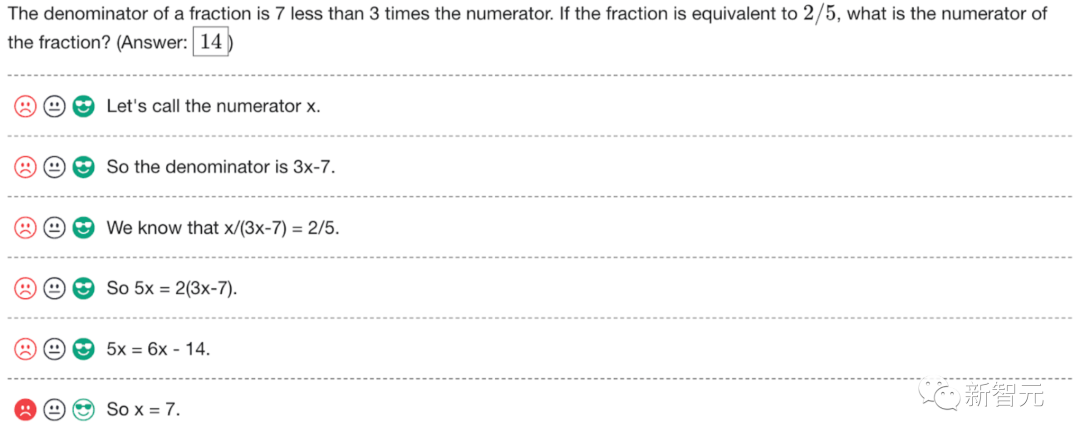
これは学校でよく言われる古いことわざのようなものです、考え方を学びましょう。

ChatGPT は数学が非常に苦手です。今日は4年生の算数の本の算数の問題を解いてみました。 ChatGPT は間違った答えを返しました。 ChatGPT からの回答、perplexity AI、Google、および 4 年生の教師からの回答を使用して自分の答えを確認しました。 chatgpt の答えが間違っていることはどこでも確認できます。
## 参考文献:  //m.sbmmt.com/link/daf642455364613e2120c636b5a1f9c7
//m.sbmmt.com/link/daf642455364613e2120c636b5a1f9c7
以上がGPT-4 は優れた数学的能力を持っています。 OpenAI の「プロセス監視」に関する爆発的な研究により、問題の 78.2% が突破され、幻覚が解消されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



