


インデックスは、データ テーブル内のすべてのレコードへの参照ポインターを含む特別なファイルです。テーブル内の 1 つ以上の列にインデックスを作成し、インデックスのタイプを指定できます。各タイプのインデックスには独自のデータ構造実装があります。
データベース内のテーブル、データ、インデックス間の関係は、本、本の内容、本棚の書籍カタログ間の関係に似ています。インデックスは書籍カタログに似ており、データをすばやく検索して取得するために使用できます。インデックスによりデータベースのパフォーマンスが大幅に向上します。
データベース テーブルの特定の列にインデックスを作成することを検討するには、次の点を考慮する必要があります。
#Data ボリュームが大きいため、これらの列に対して条件付きクエリが実行されることがよくあります。
このデータベース テーブルのこれらの列に対する挿入操作と変更操作の頻度は低いです。
インデックスは追加のディスク領域を占有します。
インデックスの保存構造から分割: BTree インデックス、ハッシュ インデックス、FULLTEXT フルテキスト インデックス、RTree インデックス
アプリケーションレベルから分割:通常のインデックス、ユニークインデックス、主キーインデックス、複合インデックス
インデックスのキー値の型、主キーから分割インデックス、補助インデックス (セカンダリ インデックス インデックス)
データ ストレージとインデックス キー値の論理関係から分割: クラスター化インデックス (クラスター化インデックス) 非クラスター化インデックス (非クラスター化インデックス)
インデックスの列数による分割: 単一列インデックス、複合インデックス

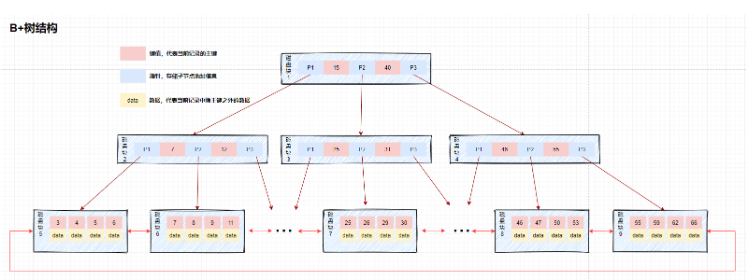
相違点:
データは別の場所に保存されます: B ツリーはリーフ ノードに保存され、B -tree はすべてのノードに保存されます。
B ツリーの利点を反映しています。ノードはデータを保存しないため、1 つのノードにより多くのキーを保存できます。これによりツリーが短くなり、IO 操作の数が減ります。クエリのパフォーマンスは安定しています。各クエリはルート ノードからリーフ ノードまで移動し、クエリ パスの長さは同じです。つまり、各クエリの効率は同等で、時間計算量は O(log(n))## に固定されています。
#リーフ ノード ポインティング: B ツリーの隣接するリーフ ノードは、ポインタを介して接続されます。B ツリーは、B ツリーの利点を反映しません。#すべてのリーフ ノードは、順序付けされたリンクを形成します。範囲検索を容易にするリスト
#3 インデックス操作主キー インデックスの作成-- 在创建表的时候,直接在字段名后指定 primary key create table user1(id int primary key, name varchar(30)); -- 在创建表的最后,指定某列或某几列为主键索引 create table user2(id int, name varchar(30), primary key(id)); -- 创建表以后再添加主键 create table user3(id int, name varchar(30)); alter table user3 add primary key(id);
-- 在表定义时,在某列后直接指定unique唯一属性。 create table user4(id int primary key, name varchar(30) unique); -- 创建表时,在表的后面指定某列或某几列为unique create table user5(id int primary key, name varchar(30), unique(name)); -- 创建表以后再添加unique create table user6(id int primary key, name varchar(30)); alter table user6 add unique(name);
--在表的定义最后,指定某列为索引 create table user8(id int primary key, name varchar(20), email varchar(30), index(name) ); --创建完表以后指定某列为普通索引 create table user9(id int primary key, name varchar(20), email varchar(30)); alter table user9 add index(name); -- 创建一个索引名为 idx_name 的索引 create table user10(id int primary key, name varchar(20), email varchar(30)); create index idx_name on user10(name);
#クエリ インデックス
##mysql> Goods\G
************ のキーを表示 1. row * **********Key_name: PRIMARY <= 主キーのインデックスSeq_in_index: 1
Column_name: Goods_id < ;= インデックスはどの列にありますか?
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE < = フォーム内のインデックスバイナリ ツリーの
コメント:
セット内の 1 行 (0.00 秒)
テーブル名のインデックスを表示;
mysql> alter table user10 drop index idx_name;
インデックス インデックス名をテーブル名にドロップします
mysql> drop index name on user8
以上がMySQL データベースのインデックス作成の原理と最適化戦略は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



