


この一番左のプレフィックスインデックスがある理由
結局のところ、mysqlのデータベース構造Bツリーです
実際の問題としては、
インデックス インデックス (a、b、c) には 3 つのフィールドがあります。
クエリ ステートメントを使用します。 select * from table where c = '1' 、SQL ステートメントはインデックス Index
select * from table where b =‘1’ and c ='2' このステートメントはインデックスを経由しませんインデックス
左端のプレフィックス マッチング原則: MySQL が結合インデックスを構築するとき、左端のプレフィックス マッチング原則、つまり左端の優先順位に従います。結合インデックスの左端。
より良い方法 この状況を特定するには、テーブルとインデックスを作成して分析します。
テーブルを作成し、ジョイント インデックス。順序が逆であっても識別できます。ただし、そのすべての部分が存在する必要があります。
Create table
CREATE TABLE staffs( id INT PRIMARY KEY AUTO_INCREMENT, `name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'姓名', `age` INT NOT NULL DEFAULT 0 COMMENT'年龄', `pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位', `add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间' )CHARSET utf8 COMMENT'员工记录表'; INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW()); INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW()); INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
CreateindexALTER TABLE Staffs ADD INDEX Index_staffs_nameAgePos (name,age,pos);
インデックスの順序name-age-pos
インデックスに 1 つがあるかどうかを表示しますインデックスを表示from Staffs;

explain select *from Staffs where name='z3' and age=22 and pos='manager';
 上記 3 つの順序が逆になり、ジョイントがインデックスが使用されます。
上記 3 つの順序が逆になり、ジョイントがインデックスが使用されます。
主な理由は、MySQL にクエリ オプティマイザーの Explain があるためです。したがって、SQL ステートメント内のフィールドの順序は、SQL ステートメントで定義されたフィールドの順序と同じである必要はありません。クエリ オプティマイザーは、SQL ステートメントが効率的に実行される順序を判断して修正し、最終的に実際の実行プランを生成します。
ジョイント インデックスは任意の順序で使用できます
3. 部分的なインデックスの順序
 3.2 順序が乱れています
3.2 順序が乱れています
一部のインデックスの順序が異なる場合順序が狂っています
最初のインデックスのみを確認してください
explain select *from Staffs where name= 'z3'; #中間のインデックスをスキップします
最後のインデックスのみを確認します
欠落している場合腕や脚の場合は、引き続き通常のインデックスを使用します。
type は all 型で、テーブル全体が直接クエリされます (名前の先頭から一致するものがないため、pos と直接一致すると順序が狂って表示されます) 場合によっては、インデックスを通じてクエリを実行できるため、type がインデックス タイプになることがあります。index はすべてのインデックス ツリーをスキャンし、all はテーブル全体のディスク データ全体をスキャンします4. ファジー インデックス同様のあいまいインデックスでは like ステートメントを使用しますしたがって、次の 3 つのステートメント左端のプレフィックスと結合すると、インデックス付けに範囲またはインデックス タイプが使用されます
explain select *from Staffs where name like '3%';
左端の接頭辞インデックス、タイプはインデックスまたは範囲です
#explain select *from Staffs where name like '%3%'; Type is all, full table query
explain select *from Staffs where name like '%'; 3%';、タイプはすべて、完全なテーブル クエリ
# #5. 範囲インデックス
具体的なアイデアは次のとおりです
建立一张单表
CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARCHAR(255) NOT NULL, content TEXT NOT NULL ); INSERT INTO article(author_id,category_id,views,comments,title,content) VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (1,1,3,3,'3','3');
经过如下查询:
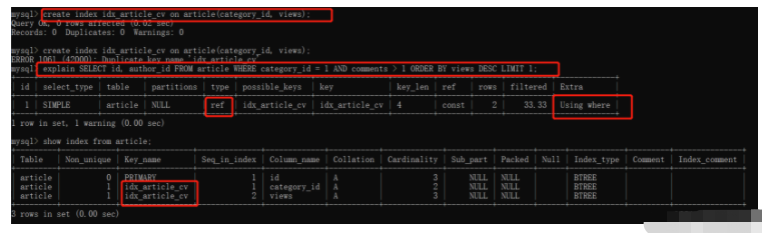
explain SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;

发现其上面的单表查询,不是索引的话,他是进行了全表查询,而且在extra还出现了Using filesort等问题
所以思路可以有建立其复合索引
具体建立复合索引有两种方式:
create index idx_article_ccv on article(category_id,comments,views);
ALTER TABLE 'article' ADD INDEX idx_article_ccv ( 'category_id , 'comments', 'views' );

但这只是去除了它的范围,如果要去除Using filesort问题的话,还要将其中间的条件范围改为等于号才可满足
发现其思路不行,所以删除其索引 DROP INDEX idx_article_ccv ON article;

主要的原因是:
这是因为按照BTree索引的工作原理,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments 则再排序views。
当comments字段在联合索引里处于中间位置时,因comments > 1条件是一个范围值(所谓range),MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
所以建立复合索引是对的
但是其思路要避开中间那个范围的索引进去
只加入另外两个索引即可create index idx_article_cv on article(category_id, views);
以上がMySQLインデックスの一番左の接頭辞の原則は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



