


#はじめに
##ベクトルに基づく方法データベース LLM (大規模言語モデル) を使用して、あなたをよりよく理解する企業固有のチャットボットを作成しますか?
1. チャットボットにはなぜ大規模な言語モデル ベクトル データベースが必要なのでしょうか?この春、最も衝撃的なテクノロジー製品は ChatGPT の登場です。大規模言語モデル (LLM) を通じて、人々は生成 AI が人間の言語と同じ目標を達成できることがわかりました。類似性の高い言語表現能力により、AI はもはや手の届かないものではなく、人間の仕事や生活に参入できるようになり、長らく休眠状態にあった AI 分野が活性化され、数え切れないほどの実践者が次の時代に向けて熱心に取り組んでいます。機会; 不完全な統計によると、米国はわずか 4 か月で 4,000 件を超える生成 AI 産業への融資を完了しました。次世代テクノロジーにおいて、生成 AI は資本や企業の一部として無視できないものとなり、その開発をサポートするためにより高いレベルのインフラストラクチャ機能がますます必要とされています。
# 大きなモデルは比較的答えられるこれは普遍的な問題ですが、垂直の専門分野にサービスを提供したい場合は、知識の深さと適時性が不十分であるという問題が発生します。現在、2 つのモデルがあり、1 つは大規模モデルをベースにした垂直ドメイン モデルである Fine Tune で、包括的な投資コストが大きく、更新頻度が低く、すべての企業に適しているわけではありません。企業独自の知識資産をベクトルデータベースに蓄積し、大規模モデルのベクトルデータベースを活用して垂直分野の深層サービスを構築し、迅速なエンジニアリングにデータベースを活用することが本質です。企業は、法規定と判例の垂直カテゴリーを使用して、法律業界などの特定の分野でリーガル テクノロジー サービスを構築できます。たとえば、リーガル テクノロジー企業である Harvey は、法律の起草と調査サービスを改善するために「弁護士のための副操縦士」を構築しています。ベクトル機能を通じてエンタープライズ ナレッジ ベースのドキュメントとリアルタイム情報を抽出し、それらをベクトル データベースに保存し、LLM ラージ言語モデルと組み合わせることで、チャットボット (質疑応答ロボット) の回答をより専門的かつタイムリーなものにし、エンタープライズ サービスを構築できます。特定のチャットボット。 ##########################################どうやって####### 大規模な言語モデルに基づく##Chatbot が時事問題の質問により適切に回答できるようにします
? 「Alibaba Cloud Yaochi Database」ビデオ アカウントへようこそ。デモ
Demo をご覧ください。 この記事では次に、大規模言語モデル (LLM) に焦点を当てます。 ) エンタープライズ固有のチャットボットを構築するための Vector Database の原則とプロセス、およびこのシナリオを構築する際の ADB-PG の中核機能。 #2. ベクトル データベースとは何ですか?
現実の世界では、ほとんどのデータは画像、音声、ビデオ、テキストなどの非構造化形式です。スマート シティ、ショート ビデオ、パーソナライズされた製品レコメンデーション、ビジュアル製品検索、その他のアプリケーションの出現により、これらの非構造化データは爆発的に増加しました。これらの非構造化データを処理できるようにするために、私たちは通常、人工知能技術を使用してこれらの非構造化データの特徴を抽出し、特徴ベクトルに変換し、これらの特徴ベクトルを分析して取得して、非構造化データを分析する目的を達成します。処理。したがって、特徴ベクトルを保存、分析、取得できるデータベースをベクトル データベースと呼びます。# 特徴ベクトルを高速に取得するために、ベクトル データベースは通常、ベクトル インデックスを構築する技術的手段を使用します。私たちが通常話しているベクトル インデックスは、ANNS (近似最近傍検索、近似最近傍検索) に属します。その中心となるアイデアは、最も正確な結果項目のみを返すことに限定されなくなり、隣接する可能性のあるデータ項目のみを検索する、つまり、検索効率の向上と引き換えに許容範囲内の精度を少し犠牲にすることです。 。これは、ベクトル データベースと従来のデータベースの最大の違いでもあります。 #現在、実際の本番環境では、Main は 2 種類あります。 ANNS ベクトルインデックスをより便利に適用する実用的な方法。 1 つは、ANNS ベクトル インデックスを個別に提供して、ベクトル インデックスの作成および検索機能を提供し、それによって独自のベクトル データベースを形成する方法であり、もう 1 つは、ANNS ベクトル インデックスを従来の構造化データベースに統合して、ベクトル検索機能を備えた DBMS を形成する方法です。実際のビジネス シナリオでは、独自のベクトル データベースを他の従来のデータベースと組み合わせて使用する必要があることが多く、これにより、データの冗長性、過度のデータ移行、データの一貫性の問題などの一般的な問題が発生します。真の DBMS と比較すると、独自のデータベースは、ベクトル データベースには、追加の専門的なメンテナンス、追加コストが必要であり、クエリ言語機能、プログラマビリティ、スケーラビリティ、およびツールの統合が非常に限られています。 #ベクトル検索機能を組み込んだDBMSは異なります。まず第一に、アプリケーション開発者のデータベース機能のニーズを満たすことができる非常に完全な最新のデータベース プラットフォーム、次にその統合されたベクトル検索機能により、独自のベクトル データベースの機能も実装でき、ベクトルの保存と検索が DBMS の優れた機能を継承できるようになります。使いやすさ(SQL を直接使用してベクトルを処理する)、トランザクション、高可用性、高スケーラビリティなど。 3. LLM 大規模言語モデル ADB-PG: エンタープライズ固有のチャットボットの作成
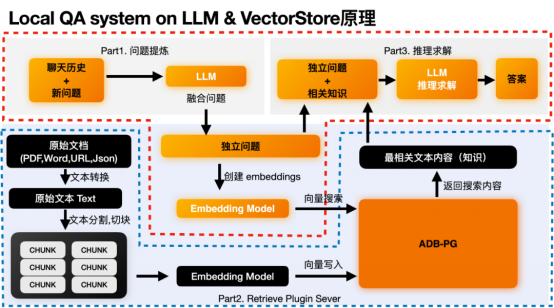
##「トン・イー・チアン」への回答何を尋ねますか? ドキュメント、PDF、電子メール、ネットワーク情報、その他のコンテンツ。例えば:############### 実装原則 #a. バックエンドのデータ処理およびストレージ プロセス b. フロントエンド Q&A プロセス 同時に、その基礎となるメインモジュールは 2 つのモジュールに依存します: 1. 大規模言語モデルに基づく推論モジュール 2. ベクトルデータベースに基づくベクトルデータ管理モジュール バックエンド データ処理とストレージ プロセス上の図の黒い部分はバックエンド データ処理プロセスであり、主に次のような問題を解決します。当社のオリジナルデータを埋め込み、オリジナルと結合します。 データはベクトルデータベースADB-PGにまとめて保存されます。ここでは、上の図の青い点線のボックスの部分にのみ注意する必要があります。ブラックプロセッシングモジュールとADB-PGベクトルデータベース。 # LLLM のローカル QA システム& VectorStoreパート 1 問題の改善 # #一部の質問はコンテキストに依存するため、この部分はオプションであり、存在します。ユーザーが尋ねた新しい質問では、LLM がユーザーの意図を理解できない可能性があるためです。
たとえば、ユーザーの新しい質問は次のとおりです。する?" "。 LLM は、それが誰を指しているのかを知りません。また、「Tongyi Qianwen とは何ですか」などの以前のチャット履歴を組み合わせて、ユーザーが「Tongyi Qianwen は何ができますか?」に答える必要がある独立した質問を推測する必要があります。 LLM は、「その用途は何ですか」という漠然とした質問には正しく答えることができませんが、「Tongyi Qianwen の用途は何ですか」という独立した質問には正しく答えることができます。問題が自己完結型である場合、このセクションは必要ありません。 #独立した質問を取得した後、この独立した質問に基づいて次のことができます。 、この独立した問題の埋め込みを見つけます。次に、ベクトル データベースで最も類似したベクトルを検索し、最も関連性の高いコンテンツを見つけます。この動作は Part2 取得プラグインの機能によるものです。 #Part2 ベクトルの検索 #独立問題埋め込み関数は text2vec モデルで実行されます。エンベディングを取得した後、このエンベディングを使用して、ベクトル データベースに事前に格納されているデータを検索できます。たとえば、次のコンテンツを ADB-PG に保存しました。 1番目と3番目のように、得られたベクトルを通じて最も類似した内容や知識を得ることができます。 Tongyi Qianwen は...、Tongyi Qianwen が私たちの xxx を手伝ってくれます。 パート 3 推論ソリューション 最も関連性の高い知識を取得した後、LLM に最も関連性の高い知識と独立した質問に基づいて解決策の推論を実行させ、最終的な答えを得ることができます。ここでは、「Tongyi Qianwen は...」、「Tongyi Qianwen は xxx を助けてくれます」などの最も効果的な情報を組み合わせて、「Tongyi Qianwen の用途は何ですか」という質問に対する答えを示します。最終的に、GPT の推論ソリューションは大まかに次のようになります: ADB-PG が適している理由チャットボットのナレッジデータベースとして? ADB-PG は、大規模な並列処理機能を備えたクラウドネイティブのデータ ウェアハウスです。行ストレージ モードと列ストレージ モードをサポートしており、高パフォーマンスのオフライン データ処理を提供するだけでなく、大量のデータの同時実行性の高いオンライン分析やクエリもサポートします。したがって、ADB-PG は、分散トランザクションと混合負荷をサポートし、さまざまな非構造化および半構造化データ ソースの処理もサポートするデータ ウェアハウス プラットフォームであると言えます。たとえば、ベクトル検索プラグインを使用すると、画像、言語、ビデオ、テキストなどの非構造化データの高性能ベクトル検索と分析、および JSON などの半構造化データの全文検索と分析が可能になります。 したがって、AIGC シナリオでは、ADB-PG は次のように実行できます。ベクトル データベースとして、ベクトルの保存と検索のニーズを満たし、他の構造化データの保存とクエリにも対応でき、全文検索機能も提供できるため、AIGC シナリオのビジネス アプリケーションにワンストップ ソリューションを提供します。 。以下では、ADB-PG の 3 つの機能、ベクトル検索、融合検索、および全文検索について詳しく紹介します。
##ベクトル 高速化するには、ベクトル インデックスを作成する必要もあります。 ##同時に、ベクトル構造化融合クエリを高速化するために、一般的に使用される構造化列のインデックスを作成する必要もあります: データを挿入するときは、SQL の挿入構文を直接使用できます: # #この例では、ソース記事をテキストで検索したい場合は、ベクトル検索で直接検索できます。具体的な SQL は次のとおりです:
##上記の例を読んだ後、ADB-PG でのベクトル検索と融合検索の使用は、同様に便利であることが明確にわかります。学習しきい値なしで従来のデータベースを使用するのと同じです。同時に、ベクトルデータ圧縮、ベクトルインデックスの並列構築、ベクトルマルチパーティション並列検索など、ベクトル検索に対して多くの的を絞った最適化も行いましたが、ここでは詳しく説明しません。 ADB-PG には、豊富な全文検索機能もあります。複雑な組み合わせ条件や結果のランキングなどの検索機能をサポートし、さらに中国語データセットの場合、ADB-PG は中国語テキストを効率的かつカスタマイズして処理および分割できる中国語単語分割機能もサポートします。全文検索を高速化するためのインデックスの使用をサポートし、パフォーマンスを分析します。これらの機能は AIGC ビジネス シナリオでも十分に活用でき、たとえば、前述のベクトル検索機能や全文検索機能と組み合わせて、ナレッジ ベース ドキュメントの双方向の呼び出しを実行できます。 ナレッジ データベースの検索部分には、従来のキーワード全文検索が含まれていますベクトル特徴検索、キーワード全文検索により、クエリの精度が保証されます。ベクトル特徴検索は、一般化と意味的マッチングを提供します。リテラル マッチングに加えて、意味的マッチングの知識を思い出し、結果が出ない率を減らし、より豊富な情報を提供します。コンテキストは、大規模な言語モデルの要約と誘導に役立ちます。 5. 概要この記事の前半で説明したコンテンツと組み合わせると、知識豊富なチャットボット#を比較できます。 # 人 # クラス ## です#, すると、大きな言語モデルは、チャットボットが大学卒業までにさまざまな分野のあらゆる書籍や公開資料から得た知識と学習推論能力とみなすことができます。したがって、大規模な言語モデルに基づいて、チャットボットは卒業前にそれに関連する質問に回答することができますが、質問が特定の専門分野に関するもの(関連する情報は企業組織の専有物であり公開されていません)や、新しく出現した種の概念(大学卒業時にはまだリリースされていない(誕生)ため、学校で得た知識(事前に訓練された大規模な言語モデルに相当)だけでは冷静に対処することができず、継続的にチャンネルを持っている必要があります。卒業後に新たな知識(仕事関連の専門学習データベースなど)を獲得し、自身の学習能力や推論能力と組み合わせて、専門的な対応を行う。 # 同じチャットボットは、大規模な言語モデルの学習機能と推論機能を、ベクトル検索機能と全文検索機能 (独自の情報を保存する) を含む ADB-PG のようなワンストップ データベースと組み合わせる必要があります。企業組織の最新情報、ナレッジドキュメント、ベクトル特徴など)を活用し、質問に回答する際に、データベース内のナレッジコンテンツに基づいて、より専門的かつタイムリーな回答を提供できます。 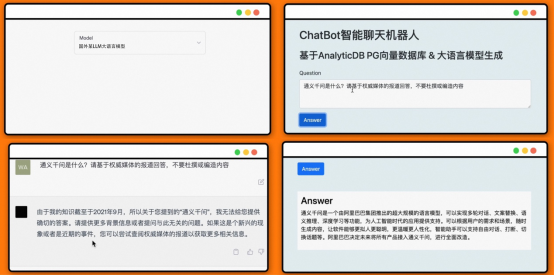
 ##LLM および VectorStore 原則に関するローカル QA システム
##LLM および VectorStore 原則に関するローカル QA システム
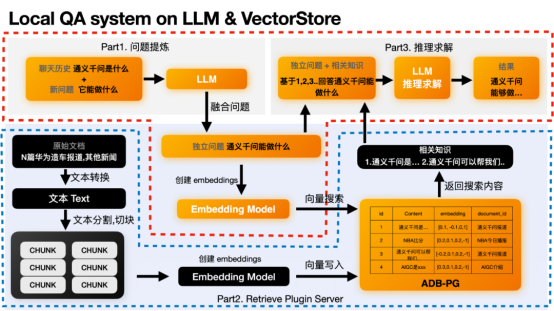

# 特定の例を使用して ADB を説明しましょう - PG の使用方法ベクトル検索と融合検索。データベースに入力する前に記事のバッチをチャンクに分割し、それらを埋め込みベクトルに変換するテキスト ナレッジ ベースがあるとします。チャンク テーブルには次のフィールドが含まれます: 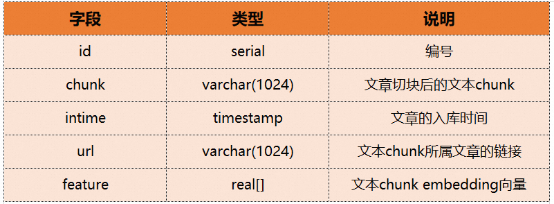





##同様に、最新の月を見つける必要がある場合は、特定の記事のソース記事を見つけます。内のテキスト。次に、フュージョン検索を使用して直接検索することができます。具体的な SQL は次のとおりです: 
## は
以上がAlibaba Cloud AnalyticDB (ADB) + LLM: AIGC 時代のエンタープライズ固有のチャットボットの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



