


文字を入力してAIに動画を生成させる、これまでは想像の範囲でしか考えられなかった機能が、テクノロジーの発展により実現されました。
近年、生成人工知能はコンピューター ビジョンの分野で大きな注目を集めています。拡散モデルの出現により、テキスト プロンプトから高品質の画像を生成すること、つまりテキストと画像の合成が非常に一般的になり、成功しました。
最近の研究では、テキストから画像への拡散モデルをビデオ領域で再利用することで、テキストからビデオへの生成と編集のタスクまで拡張することに成功しました。このような方法では有望な結果が得られていますが、そのほとんどは大量のラベル付きデータを使用する広範なトレーニングを必要とし、多くのユーザーにとって費用が高すぎる可能性があります。
ビデオ生成を安価にするために、Jay Zhangjie Wu らが昨年提案した Tune-A-Video は、ビデオに安定拡散 (SD) モデルを適用するメカニズムを導入しました。分野 。調整する必要があるビデオは 1 つだけなので、トレーニングの負荷が大幅に軽減されます。これは以前の方法よりもはるかに効率的ですが、それでも最適化が必要です。さらに、Tune-A-Video の生成機能はテキストガイド付きビデオ編集アプリケーションに限定されており、ゼロからビデオを合成することは依然としてその能力を超えています。
この記事では、Picsart AI Research (PAIR)、テキサス大学オースティン校、およびその他の機関の研究者が、ゼロショットとトレーニングなしで新しいテキスト手法を実現しました。ビデオへの合成: 最適化や微調整を行わずに、テキスト プロンプトに基づいてビデオを生成するという問題の方向に一歩前進しました。




時間的一貫性を高めるために、この論文では 2 つの革新的な修正を提案します: (1) まず、生成されたフレームの潜在エンコーディングを動き情報で強化し、グローバル シーンと背景の時間的一貫性を維持します。 ; (2) ) 次に、クロスフレーム アテンション メカニズムを使用して、シーケンス全体にわたって前景オブジェクトのコンテキスト、外観、およびアイデンティティを保存します。実験によれば、これらの簡単な変更により、高品質で時間的に一貫したビデオが生成されることがわかりました (図 1 を参照)。
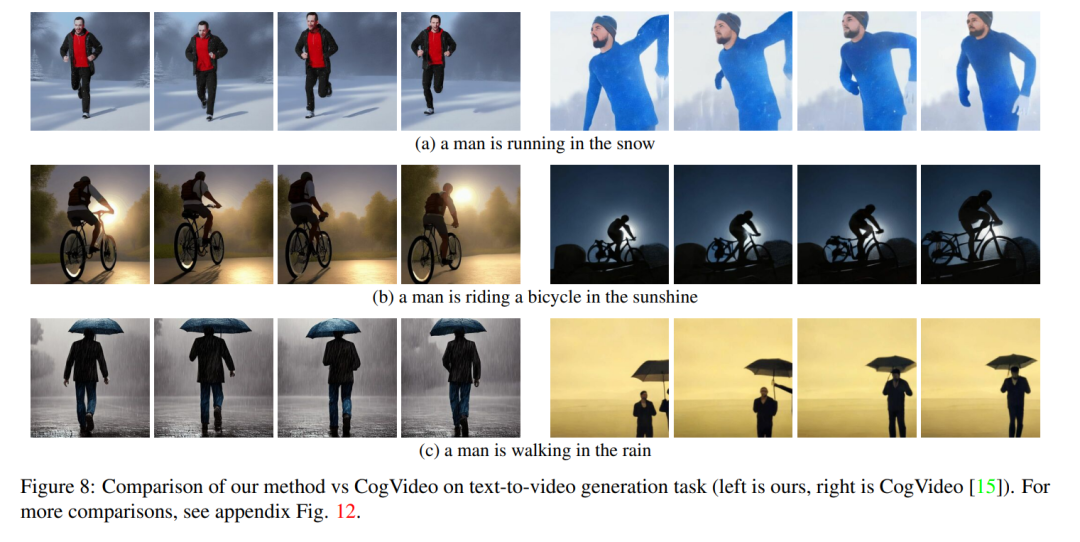
他の人の作業は大規模なビデオ データでトレーニングされましたが、私たちの方法は同様の、または場合によってはより優れたパフォーマンスを達成します (図 8 および 9 を参照)。
 #
#

 N (0, I) から m 個の潜在的なコードを個別にサンプリングし、適用することです。対応するテンソル
N (0, I) から m 個の潜在的なコードを個別にサンプリングし、適用することです。対応するテンソル 
(k = 1,…,m) を取得し、次のようにデコードする DDIM サンプル生成されたビデオ シーケンス
# を取得します。ただし、図 10 の最初の行に示すように、これにより完全にランダムな画像が生成され、オブジェクトの外観や動作の一貫性がなく、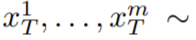
で記述されたセマンティクスのみが共有されます。
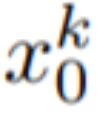
この問題を解決するために、この記事では次の 2 つの方法を推奨します。 (i) 潜在的なエンコーディング 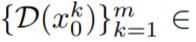 間にモーション ダイナミクスを導入して、グローバル シーンの時間的一貫性を維持します。(ii) クロスフレーム アテンション メカニズムを使用して、前景オブジェクトの外観とアイデンティティを保存します。この論文で使用されるメソッドの各コンポーネントについては以下で詳しく説明します。メソッドの概要は図 2 に示されています。
間にモーション ダイナミクスを導入して、グローバル シーンの時間的一貫性を維持します。(ii) クロスフレーム アテンション メカニズムを使用して、前景オブジェクトの外観とアイデンティティを保存します。この論文で使用されるメソッドの各コンポーネントについては以下で詳しく説明します。メソッドの概要は図 2 に示されています。 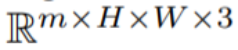
実験

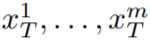 ## Text2Video-Zero のすべてのアプリケーションは、グローバル シーンと背景、前景、コンテキストの時間的一貫性を備えたビデオを正常に生成することを示しています。オブジェクトの外観とアイデンティティはシーケンス全体を通じて維持されます。
## Text2Video-Zero のすべてのアプリケーションは、グローバル シーンと背景、前景、コンテキストの時間的一貫性を備えたビデオを正常に生成することを示しています。オブジェクトの外観とアイデンティティはシーケンス全体を通じて維持されます。
テキストからビデオへの変換の場合、テキスト プロンプトとよく一致する高品質のビデオが生成されることがわかります (図 3 を参照)。例えば、パンダが自然に道を歩く姿が描かれています。同様に、追加のエッジまたはポーズ ガイダンス (図 5、図 6、および図 7 を参照) を使用すると、プロンプトとガイダンスに一致する高品質のビデオが生成され、良好な時間的一貫性とアイデンティティの保存が示されました。

#Video Instruct-Pix2Pix (図 1 を参照) の場合、生成されたビデオ指示に厳密に従いながら、入力ビデオに対して高い忠実度を実現します。
ベースラインとの比較
この文書では、その手法を 2 つの公的に利用可能なベースライン (CogVideo および Tune -A-) と比較します。ビデオ。 CogVideo はテキストからビデオへの変換方法であるため、この記事では、Tune-A-Video との比較に Video Instruct-Pix2Pix を使用して、プレーン テキスト ガイド付きビデオ合成シナリオで CogVideo と比較します。
定量的な比較のために、この記事ではビデオ テキストの整列度を表す CLIP スコアを使用してモデルを評価します。 CogVideo で生成された 25 個のビデオをランダムに取得し、この記事の方法に従って同じヒントを使用して対応するビデオを合成します。私たちの方法と CogVideo の CLIP スコアはそれぞれ 31.19 と 29.63 です。したがって、私たちの方法は CogVideo よりわずかに優れていますが、後者には 94 億のパラメーターがあり、ビデオでの大規模なトレーニングが必要です。
図 8 は、この論文で提案した方法のいくつかの結果を示し、CogVideo との定性的な比較を示しています。どちらの方法も、シーケンス全体を通じて良好な時間的一貫性を示し、オブジェクトのアイデンティティとそのコンテキストを維持します。私たちの方法は、より優れたテキストとビデオの位置合わせ機能を示しています。たとえば、図 8 (b) では、私たちのメソッドは太陽の下で自転車に乗っている人のビデオを正しく生成しますが、CogVideo は背景を月明かりに設定します。また、図 8 (a) では、私たちの方法では雪の中を走っている人が正しく表示されていますが、CogVideo によって生成されたビデオでは雪と走っている人がはっきりと見えません。
ビデオ Instruct-Pix2Pix の定性的結果と、フレームごとの Instruct-Pix2Pix および Tune-AVideo との視覚的比較を図 9 に示します。 Instruct-Pix2Pix はフレームごとに優れた編集パフォーマンスを示しますが、時間的な一貫性に欠けています。これは、スキーヤーを描いたビデオで特に顕著で、雪と空がさまざまなスタイルと色を使用して描かれています。これらの問題は、Video Instruct-Pix2Pix メソッドを使用して解決され、シーケンス全体で時間的に一貫したビデオ編集が可能になりました。
Tune-A-Video は時間一貫性のあるビデオ生成を作成しますが、この記事の方法と比較すると、指示ガイダンスとの一貫性が低く、ローカル編集の作成が難しく、入力の詳細が異なります。順序が失われます。これは、図 9 左に示されているダンサーのビデオの編集を見ると明らかです。 Tune-A-Video と比較して、私たちの方法では、ダンサーの後ろの壁はほとんど変化せずに残るなど、背景をよりよく保存しながら、衣装全体をより明るくペイントします。 Tune-A-Video は大きく変形した壁をペイントします。さらに、私たちの方法は入力の詳細により忠実です。たとえば、Tune-A-Video と比較して、Video struction-Pix2Pix は提供されたポーズを使用してダンサーを描画し (図 9 左)、入力ビデオに登場するすべてのスキーヤーを表示します。図 9 の右側の最後のフレームに示すように)。 Tune-A-Video の上記の弱点はすべて、図 23、24 でも確認できます。

 #
#
以上がビデオの生成は非常に簡単です。ヒントを与えるだけで、オンラインで試すこともできます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



