


ラージ言語モデル (LLM) や拡散 (Diffusion) などのテクノロジーの発展に伴い、ChatGPT や Midjourney などの製品の誕生により AI ブームの新たな波が起こり、生成 AI も非常に懸念される話題です。
テキストや画像とは異なり、3D 生成はまだ技術探索の段階にあります。
2022 年末、Google、NVIDIA、Microsoft は相次いで独自の 3D 生成作業を開始しましたが、そのほとんどは高度な Neural Radiation Field (NeRF) の暗黙的表現に基づいており、産業用 3D ソフトウェアと互換性がない Unity、Unreal Engine、Maya などのレンダリング パイプラインには互換性がありません。
従来のソリューションでメッシュで表現される幾何学マップやカラーマップに変換したとしても、精度不足やビジュアル品質の低下を引き起こすため、映画やテレビの制作や制作に直接適用することはできません。ゲーム制作。

#プロジェクトのウェブサイト: https://sites.google.com/view/dreamface
#論文アドレス: https://arxiv.org/abs/2304.03117
Web デモ: https://arxiv.org/abs/2304.03117 ://hyperhuman.top
HuggingFace スペース: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
これらの問題を解決するために、Yingmo Technology と上海科技大学の研究開発チームは、テキストガイドによるプログレッシブ 3D 生成フレームワークを提案しました。このフレームワークは、CG 制作標準に準拠した外部データセット (ジオメトリや PBR マテリアルを含む) を導入し、テキストに基づいてこの標準に準拠した 3D アセットを直接生成できます。 3D アセット生成のための Production-Ready A フレームワークを初めてサポートしました。
テキスト生成主導の 3D ハイパーリアルなデジタル ヒューマンを実現するために、チームはこのフレームワークをプロダクション グレードの 3D デジタル ヒューマン データセットと組み合わせました。この作品は、コンピュータ グラフィックス分野のトップ国際ジャーナルである Transactions on Graphics に受理され、トップの国際コンピュータ グラフィックス会議である SIGGRAPH 2023 で発表される予定です。
DreamFace には主に、ジオメトリ生成、物理ベースのマテリアル拡散、アニメーション機能生成の 3 つのモジュールが含まれています。
以前の 3D 生成作品と比較して、この作品の主な貢献は次のとおりです:
· DreamFace の提案 この小説生成的アプローチでは、幾何学、外観、およびアニメーション機能を分離するための漸進的学習を使用して、最近の視覚言語モデルとアニメーション化可能かつ物理的に実体化可能な顔アセットを組み合わせます。
· 新しいマテリアル拡散モデルと事前トレーニング済みモデルを潜在空間と画像空間で同時に組み合わせた、デュアルチャネル外観生成の設計を紹介します。 2 段階の最適化を実行します。
· BlendShape または生成されたパーソナライズされた BlendShape を使用した顔アセットにはアニメーション機能があり、自然なキャラクター デザインのための DreamFace の使用をさらに実証します。 ジオメトリ生成
ジオメトリ生成モジュールは、テキスト プロンプトに基づいて一貫したジオメトリ モデルを生成できます。ただし、顔の生成に関しては、監視して収束することが困難な場合があります。したがって、DreamFace は、最初に顔の幾何学的パラメータ空間でランダムにサンプリングされた候補から最適な候補を選択する、CLIP (Contrastive Language-Image Pre-Training) に基づく選択フレームワークを提案します。適切な大まかなジオメトリ モデルを作成し、その後、ジオメトリの詳細を彫刻して、頭部モデルとテキスト プロンプトの一貫性を高めます。
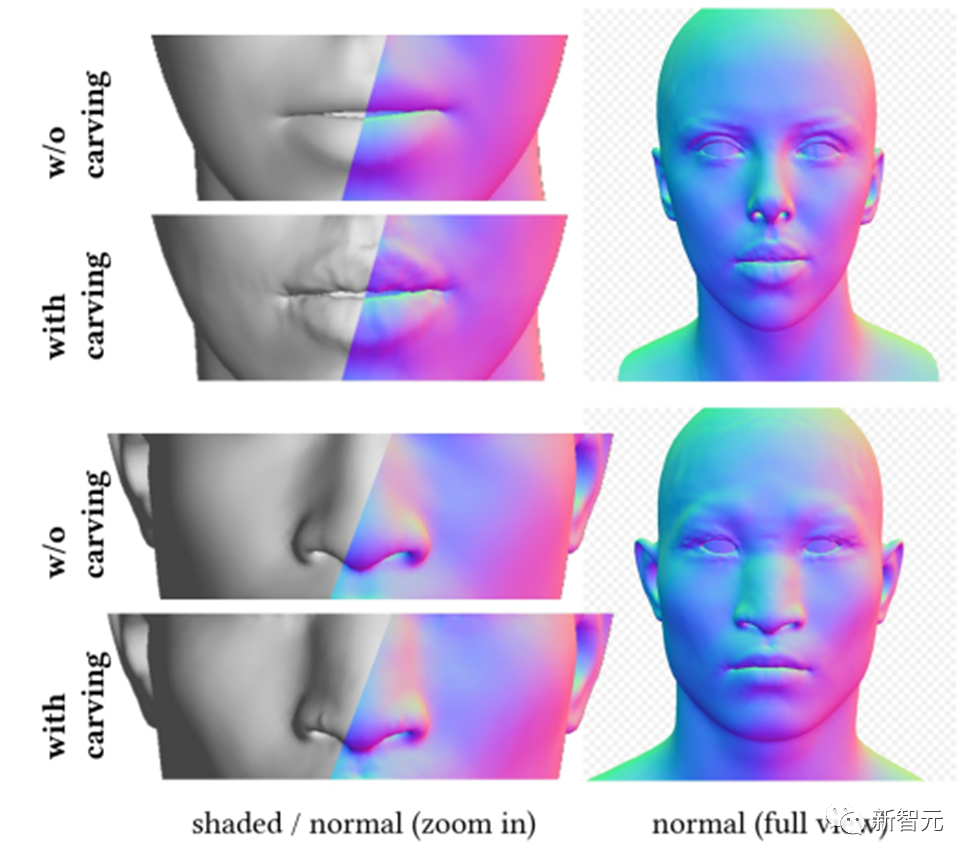
これにより、DreamFace は頂点ディスプレイスメントと詳細な法線マップを通じて大まかなジオメトリ モデルに顔の詳細を追加できるようになり、結果として非常に詳細なジオメトリが得られます。
頭部モデルと同様に、DreamFace もこのフレームワークに基づいて髪型と色の選択を行います。 物理ベースのマテリアル拡散モジュールは、予測されたジオメトリおよびテキスト キューと一致する顔のテクスチャを予測するように設計されています。 まず、DreamFace は、収集された大規模な UV マテリアル データ セットに基づいて事前トレーニングされた LDM を微調整し、2 つの LDM 拡散モデルを取得しました。 物理ベースのマテリアル拡散生成

DreamFace は、2 つの拡散プロセスを調整する共同トレーニング スキームを使用します。1 つは UV テクスチャ マップを直接ノイズ除去するためのもので、もう 1 つは拡散プロセスです。は、レンダリングされたイメージを監視して、顔の UV マップとレンダリングされたイメージがテキスト キューと一貫して正しく形成されていることを確認するために使用されます。
生成時間を短縮するために、DreamFace は粗いテクスチャ ポテンシャル拡散ステージを採用し、詳細なテクスチャ生成に先験的なポテンシャルを提供します。
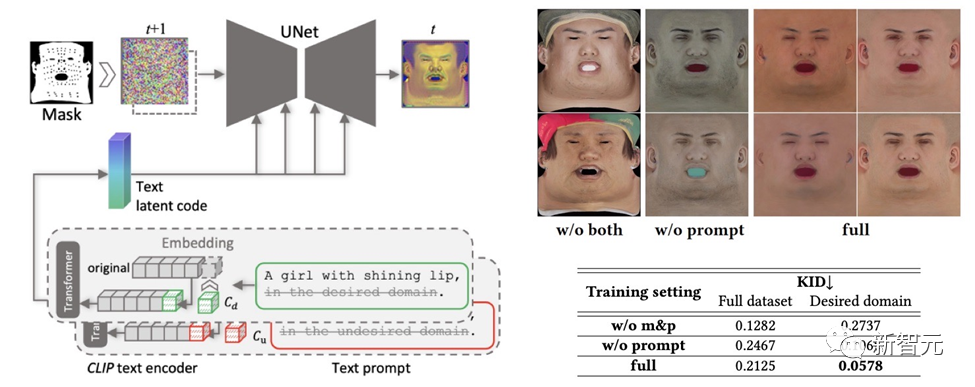
#作成されたテクスチャ マップに多様性を維持しながら、望ましくない特徴や照明状況が含まれないようにするため、デザインは手がかりとなる学習戦略。
チームは、次の 2 つの方法を使用して高品質の拡散反射マップを生成します。
(1) プロンプト チューニング。手作りのドメイン固有のテキスト キューとは異なり、DreamFace は 2 つのドメイン固有の連続テキスト キュー Cd および Cu を対応するテキスト キューと組み合わせます。これらは U-Net デノイザー トレーニング中に最適化され、不安定性や時間のかかるプロンプトの手動作成を回避します。
(2) 顔以外の領域のマスキング。 LDM ノイズ除去プロセスは、結果として得られる拡散マップに不要な要素が含まれないようにするために、非顔領域マスクによってさらに制約されます。
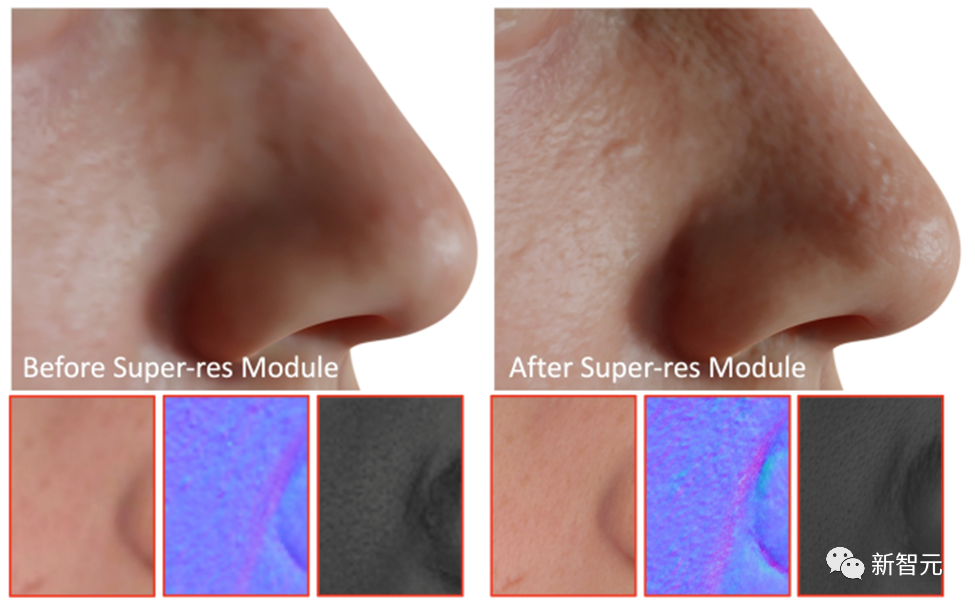
最終ステップとして、DreamFace は超解像度モジュールを適用して、高品質の 4K 物理ベースのテクスチャを生成します。レンダリング。

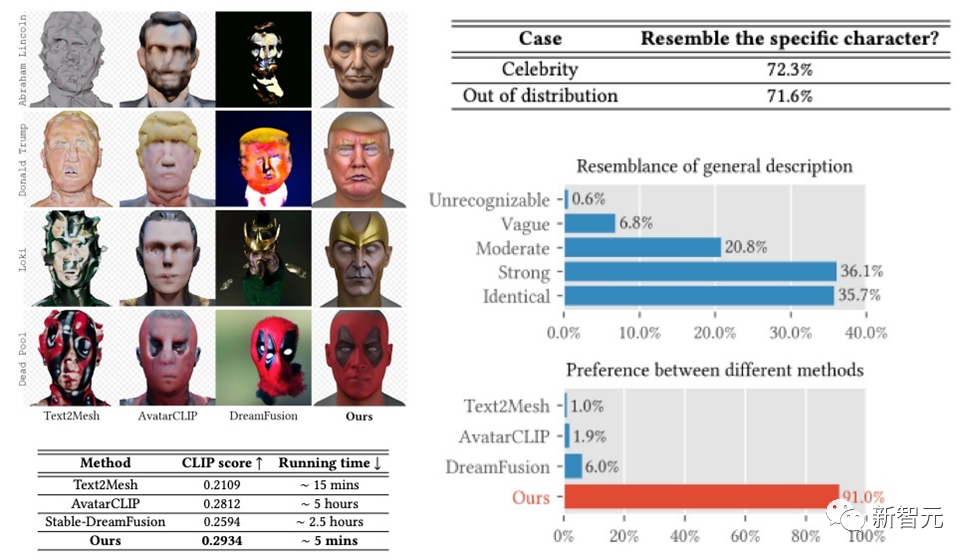
DreamFace フレームワークは、有名人の生成と説明に基づいたキャラクターの生成において非常に良い結果を達成しました。前作を遥かに超える成果が得られました。以前の作品と比較すると、実行時間においても明らかな利点があります。
# これに加えて、DreamFace はヒントとスケッチを使用したテクスチャ編集もサポートしています。エイジングやメイクアップなどのグローバルな編集効果は、微調整されたテクスチャ LDM とキューを直接使用して実現できます。さらにマスクやスケッチを組み合わせることで、タトゥーやヒゲ、あざなどさまざまな効果を生み出すことができます。

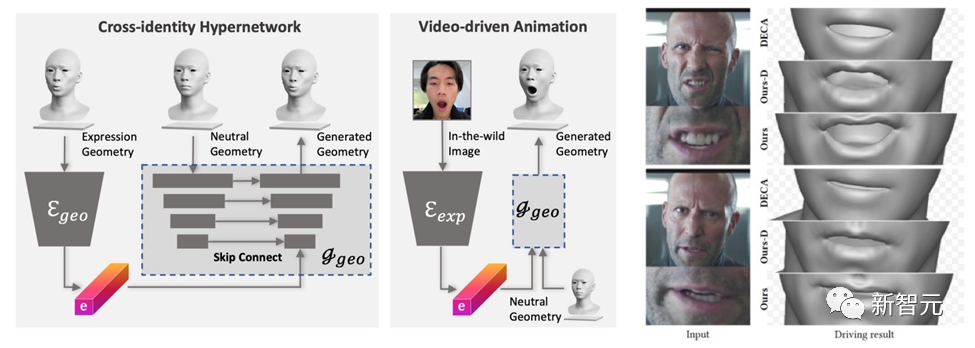
まず、幾何学的ジェネレーターは式の潜在空間を学習するようにトレーニングされ、デコーダーは中立的な幾何学的形状に条件付けされるように拡張されます。次に、表情エンコーダは、RGB 画像から表情特徴を抽出するようにさらにトレーニングされます。したがって、DreamFace は、単眼の RGB 画像を使用して、ニュートラルな幾何学的形状を条件としたパーソナライズされたアニメーションを生成できます。
表現制御に汎用の BlendShape を使用する DECA と比較して、DreamFace のフレームワークは表現の詳細を提供し、パフォーマンスを詳細にキャプチャすることができます。
この文書では、最新の視覚言語モデル、暗黙的拡散モデル、物理的モデルを組み合わせたテキストガイドによるプログレッシブ 3D 生成フレームワークである DreamFace について紹介します。ベースの材料拡散技術。
DreamFace の主な革新には、ジオメトリ生成、物理ベースのマテリアル拡散生成、およびアニメーション機能の生成が含まれます。従来の 3D 生成方法と比較して、DreamFace は精度が高く、実行速度が速く、CG パイプラインの互換性が優れています。
DreamFace のプログレッシブ生成フレームワークは、複雑な 3D 生成タスクを解決するための効果的なソリューションを提供し、同様の研究と技術開発をさらに促進することが期待されています。
さらに、物理ベースのマテリアル拡散生成とアニメーション機能生成により、映画やテレビの制作、ゲーム開発、その他の関連産業における 3D 生成テクノロジーの応用が促進されます。
以上が上海科技大学などがDreamFaceをリリース:テキストだけで「超リアルな3Dデジタルヒューマン」を生成できるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



