


OpenRL は、Fourth Paradigm 強化学習チームによって開発された PyTorch ベースの強化学習研究フレームワークで、シングル エージェント、マルチ エージェント、自然言語などのタスクのトレーニングをサポートします。 OpenRL は PyTorch に基づいて開発されており、強化学習研究コミュニティに使いやすく、柔軟で効率的で持続的に拡張可能なプラットフォームを提供することを目的としています。現在、OpenRL でサポートされている機能は次のとおりです。
##OpenRL の初めての体験
OpenRL は現在、 pip:<code>pip install openrl</code>
を通じてインストールできます。 conda を通じてインストールすることもできます:
<code>conda install -c openrl openrl</code>
OpenRL は、入力用のシンプルで使いやすいインターフェイスを提供します強化学習の - レベルのユーザー。以下は、PPO アルゴリズムを使用してトレーニングされた CartPole 環境です。例:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>OpenRL を使用してエージェントをトレーニングするには、4 つの簡単な手順のみが必要です: Create環境=> モデルの初期化=> エージェントの初期化=> トレーニングの開始
!# 通常のラップトップで上記のコードを実行すると、エージェントのトレーニングが完了するまでに数秒しかかかりません:
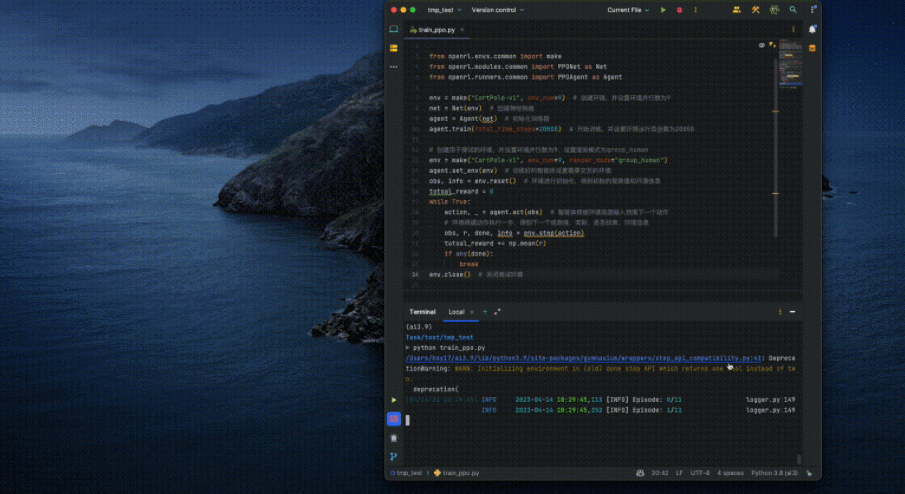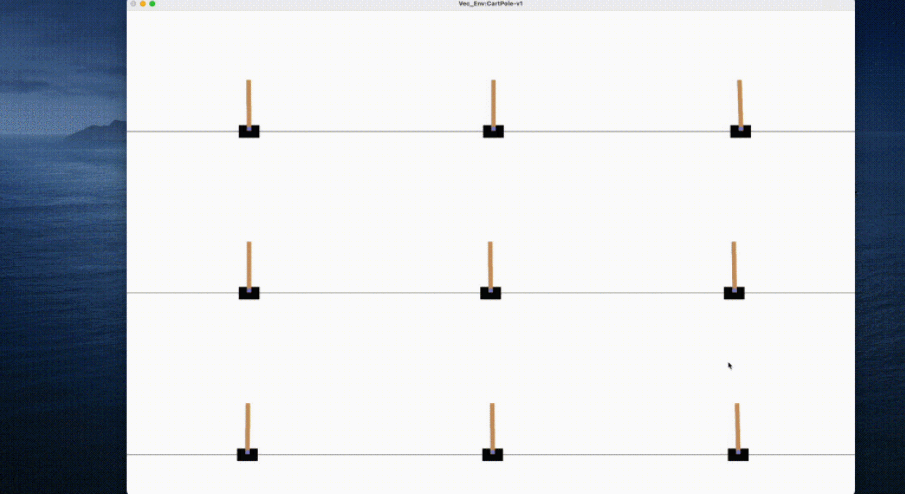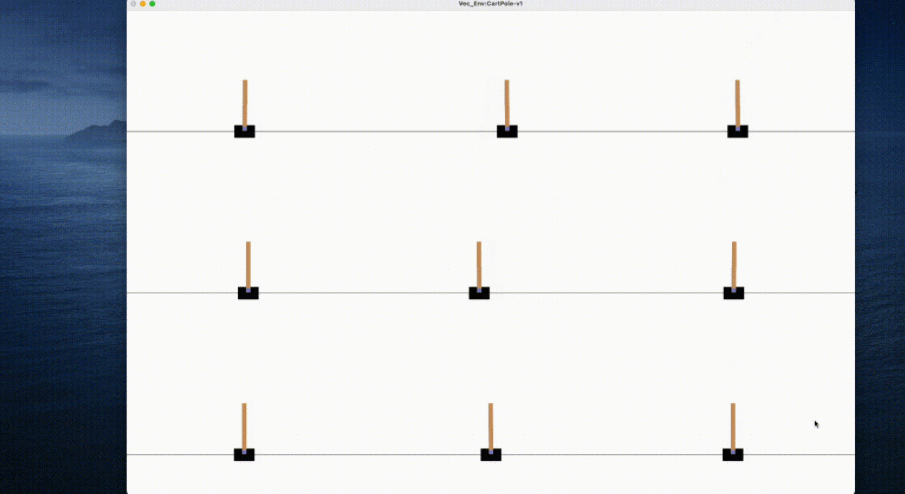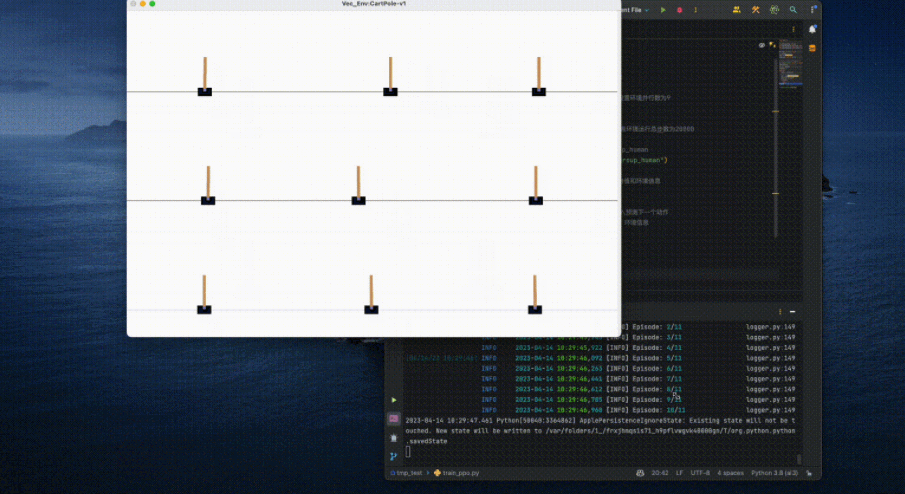
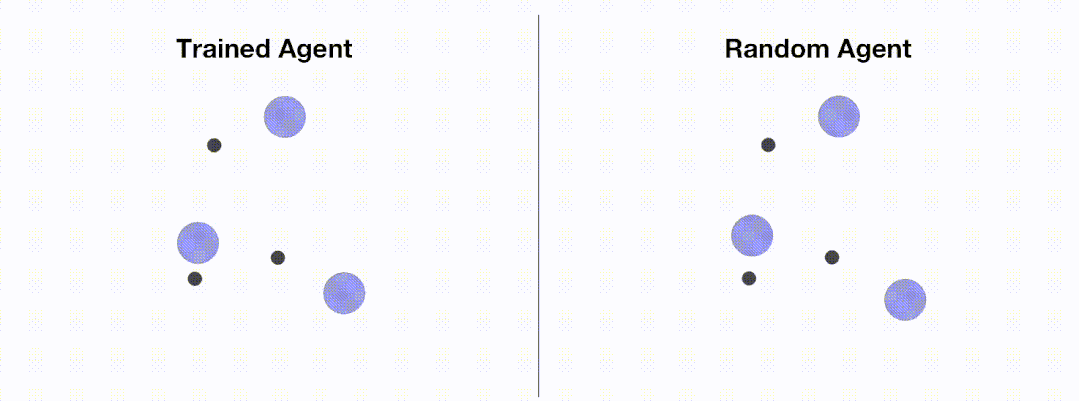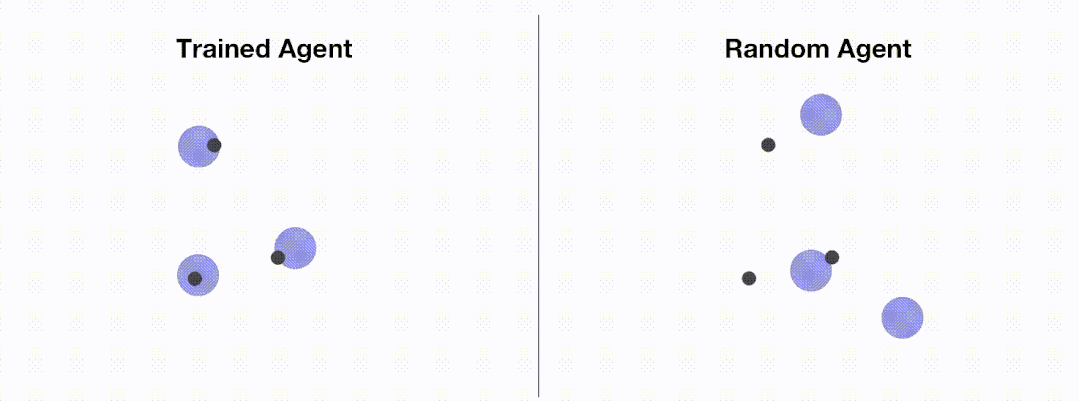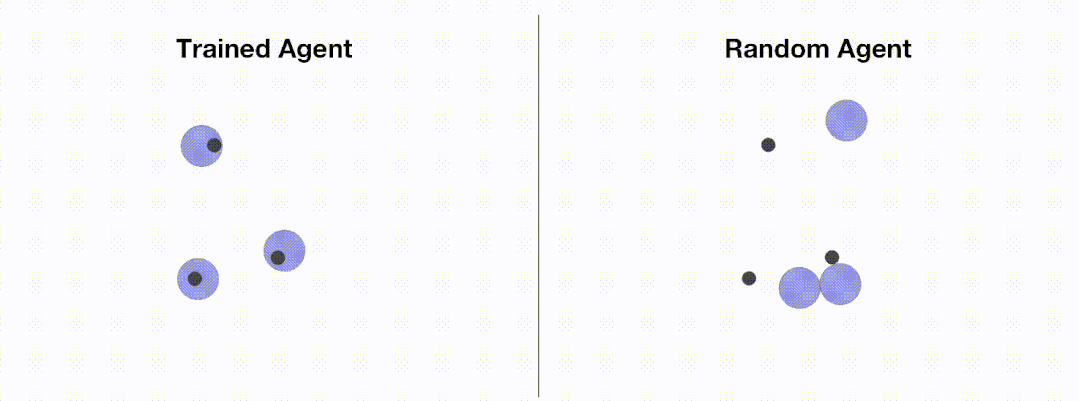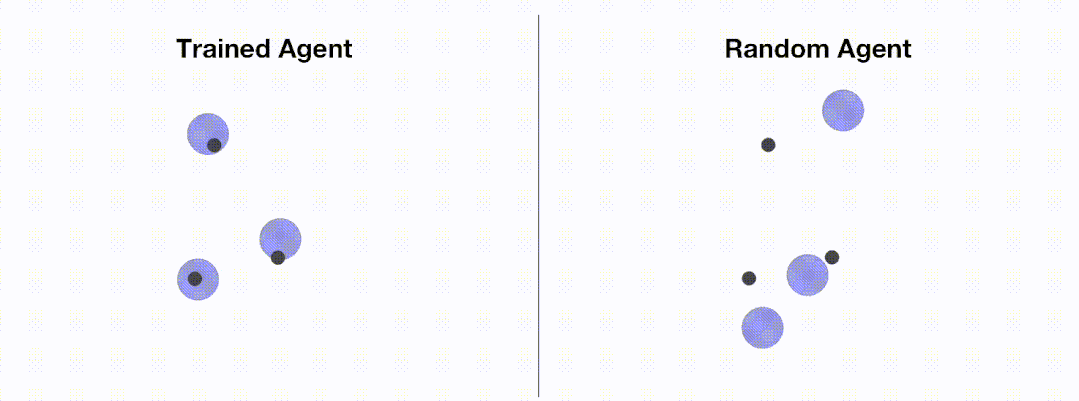
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>次の図は、エージェントのパフォーマンスを示しています。 OpenRL によるトレーニングの前後:
設定ファイルのロード
構成パラメータが多数ある場合、OpenRL は、ユーザーが独自の構成ファイルを作成してトレーニング パラメータを変更することもサポートします。たとえば、ユーザーは次の構成ファイル (mpe_ppo.yaml) を自分で作成し、その中のパラメーターを変更できます。
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
最後に、ユーザーは、実行時に構成ファイルを指定するだけで済みます。プログラム。:
<code>python train_ppo.py --config mpe_ppo.yaml</code>
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:
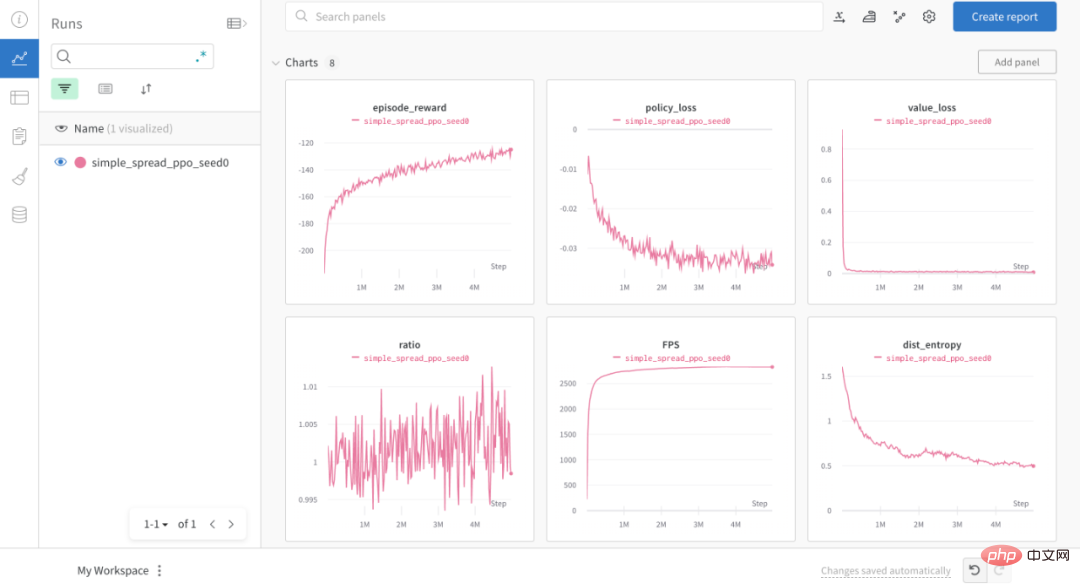
OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
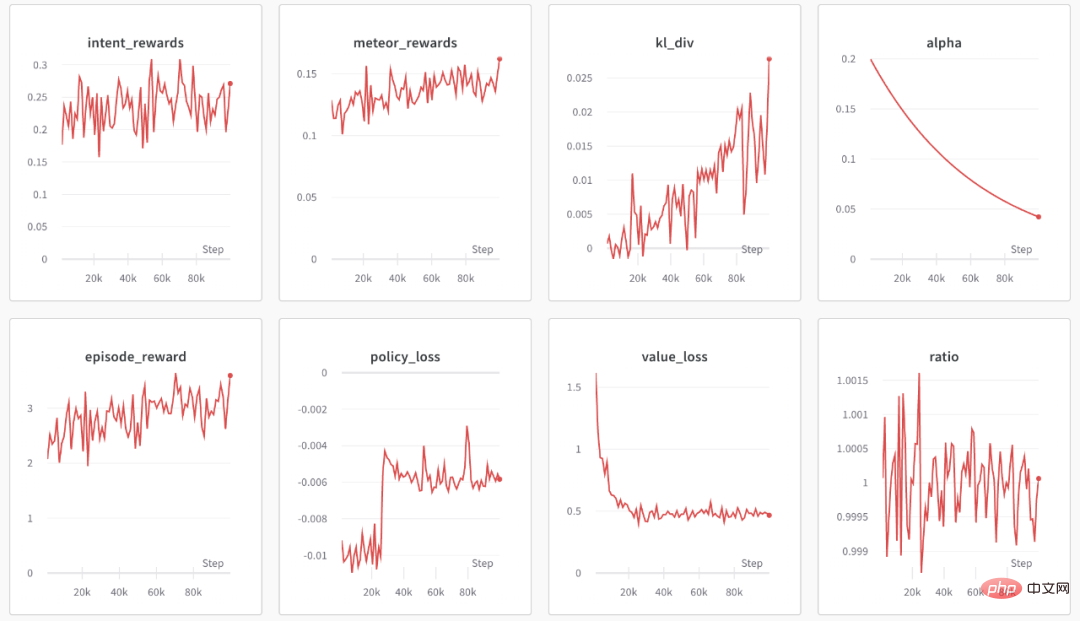
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
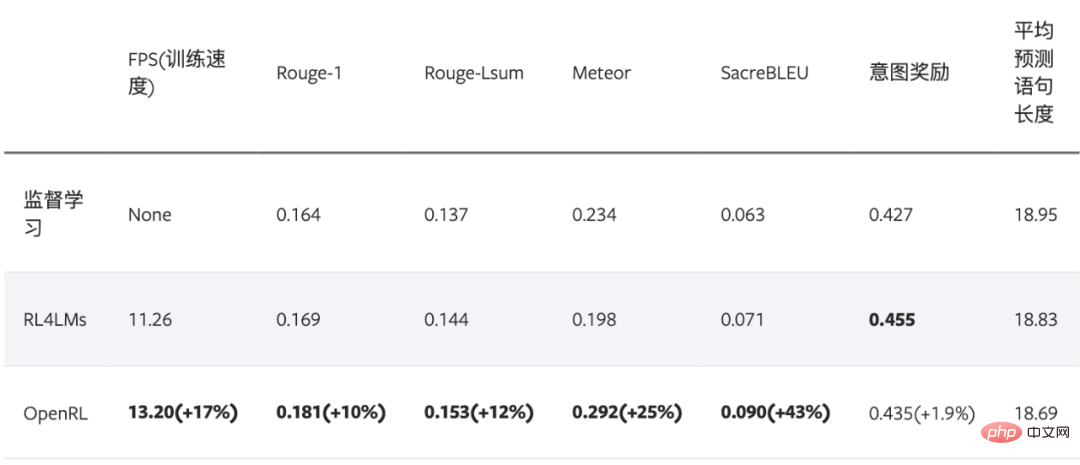
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>执行 python chat.py ,便可以和训练好的智能体进行对话了:

OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
OpenRL 框架的开发吸取了其他强化学习框架的优点:
現在、OpenRL はまだ継続的な開発と構築の段階にあります。将来的には、OpenRL はさらに多くの機能をオープンソース化する予定です:
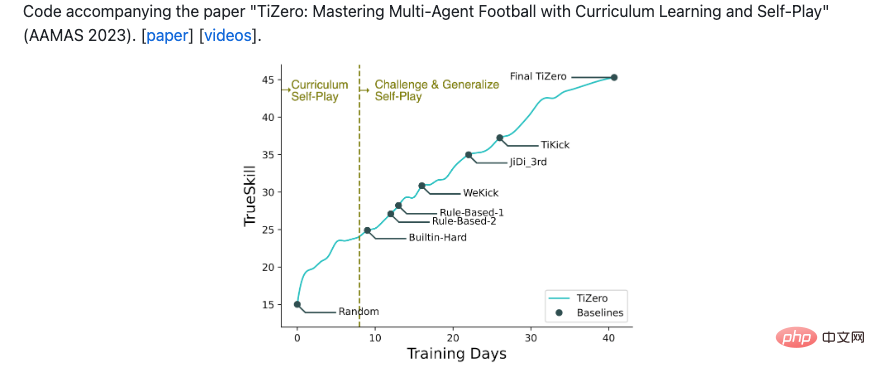
#2022 年 10 月 28 日の時点で、Tizero は Jidi 評価プラットフォームで 1 位にランクされました:
以上がトレーニング速度が 17% 向上 4 番目のパラダイムのオープンソース強化学習研究フレームワークは、シングルおよびマルチエージェントのトレーニングをサポートします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



