


NumPy (数値 Python) は、Python 用のオープンソース数値計算拡張機能です。このツールは、大規模な行列の保存と処理に使用できます。Python 独自の入れ子になったリスト構造 (行列の表現にも使用できます) よりもはるかに効率的で、多数の次元配列および行列の演算をサポートしています。配列演算用の数学関数ライブラリも多数提供しています。
Numpy は主に ndarray を使用して N 次元配列を処理します。Numpy のほとんどのプロパティとメソッドは ndarray に対応するため、Numpy での ndarray の一般的な操作を習得することが非常に必要です。
NumPy の主なオブジェクトは、同型多次元配列です。これは要素 (通常は数値) のリストであり、すべて同じ型で、非負の整数のタプルによってインデックスが付けられます。 NumPy 次元の軸と呼ばれます。
以下に示す例では、配列には 2 つの軸があります。最初の軸の長さは 2 で、2 番目の軸の長さは 3 です。
[[ 1., 0., 0.], [ 0., 1., 2.]]
ndarray.ndim: の軸 (次元)配列) の番号。 Python の世界では、次元の数をランクと呼びます。
ndarray.shape: 配列の次元。これは、各次元の配列のサイズを表す整数のタプルです。 n 行 m 列の行列の場合、形状は (n,m) になります。したがって、形状タプルの長さは、次元 ndim のランクまたは数になります。
ndarray.size: 配列要素の合計数。これは、形状要素の積に等しい。
ndarray.dtype: 配列内の要素のタイプを記述するオブジェクト。 dtype は、標準の Python タイプを使用して作成または指定できます。さらに、NumPy は独自の型を提供します。たとえば、numpy.int32、numpy.int16、numpy.float64 などです。
ndarray.itemsize : 配列内の各要素のバイト サイズ。たとえば、float64 型の要素を含む配列の項目サイズは 8 (=64/8) ですが、complex32 型の配列の項目サイズは 4 (=32/8) です。 ndarray.dtype.itemsize と同じです。
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
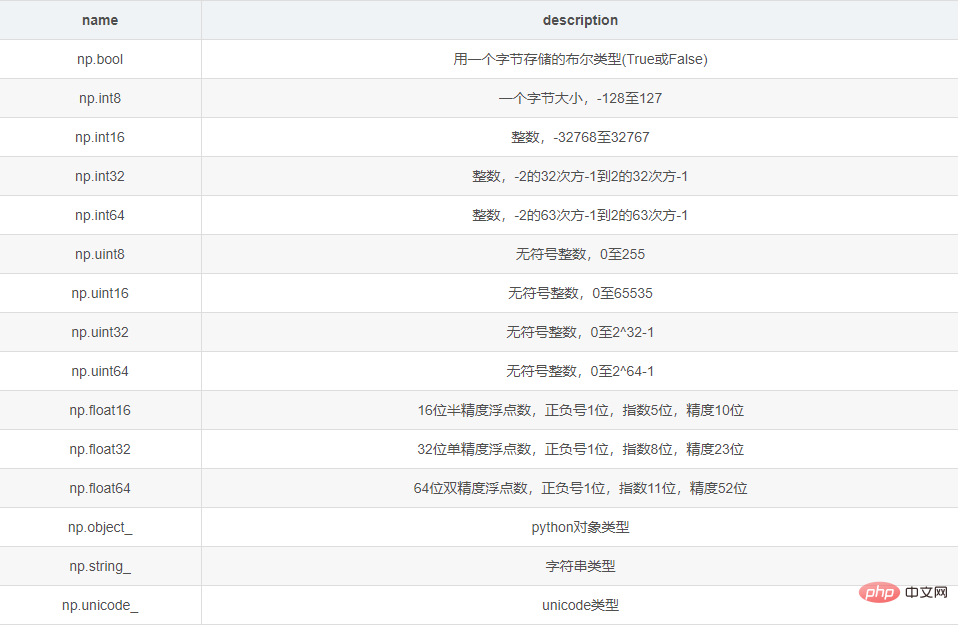
<type 'numpy.ndarray'>同じ ndarray には、同じ型のデータが格納されます。ndarray の一般的なデータ型は次のとおりです。
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
astype(dtype[, order, Casting, subok, copy]): ndarray のデータ型を変更します。変更する必要があるデータ型を渡します。他のキーワード パラメーターは無視できます。
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
NumPy は主に np.array() 関数を通じて ndarray 配列を作成します。
>>> import numpy as np >>> a = np.array([2,3,4]) >>> a array([2, 3, 4]) >>> a.dtype dtype('int64') >>> b = np.array([1.2, 3.5, 5.1]) >>> b.dtype dtype('float64')
作成時に配列の型を明示的に指定することもできます。
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])np.random.random# を使用して作成することもできます。 ## 関数 ランダムな ndarray 配列。
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]]) を作成するための関数をいくつか提供します。これにより、コストのかかる操作であるアレイの拡張の必要性が軽減されます。 Functionzeros
は 0 で構成される配列を作成し、関数 ones は完全な配列を作成し、関数 empty は初期内容がランダムである配列を作成します。記憶の状態。 デフォルトでは、作成される配列の dtype は float64 です。 数値の配列を作成するために、NumPy は、リストの代わりに配列を返す >>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])ログイン後にコピー
に似た関数を提供します。 <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">>>> np.arange( 10, 30, 5 )
array([10, 15, 20, 25])
>>> np.arange( 0, 2, 0.3 ) # it accepts float arguments
array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])</pre><div class="contentsignin">ログイン後にコピー</div></div>5 ndarray 配列の一般的な操作
は NumPy 配列で要素ごとに操作します。行列積は、@ 演算子 (Python> = 3.5 の場合) または dot 関数またはメソッドを使用して実行できます: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])</pre><div class="contentsignin">ログイン後にコピー</div></div> 特定の演算 (例:
および *=) は、新しい行列配列を作成せずに、操作対象の行列配列をより直接的に変更します。 <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype(&#39;float64&#39;) to dtype(&#39;int64&#39;) with casting rule &#39;same_kind&#39;</pre><div class="contentsignin">ログイン後にコピー</div></div>異なる型の配列を操作する場合、結果の配列の型は、より一般的または正確な配列に対応します (アップキャストと呼ばれる動作)。
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'配列内のすべての要素の合計の計算など、多くの単項演算は、
ndarray クラスのメソッドとして実装されます。 <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:py;">>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595</pre><div class="contentsignin">ログイン後にコピー</div></div>
6 ndarray 配列のインデックス付け、スライス、反復>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 计算每一列的和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 计算每一行的和
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+0ログイン後にコピー
配列は、リストや他の Python シーケンス タイプと同様に、インデックス付け、スライス、反復が可能です。 >>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729])
>>> a[ : :-1] # 将a反转
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
ログイン後にコピー
配列は、軸ごとに 1 つのインデックスを持つことができます。これらのインデックスは、カンマ区切りのタプルとして指定されます: 几个数组可以沿不同的轴堆叠在一起,例如: 使用 以上がPython Numpyにおけるndarrayの一般的な操作例の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])ログイン後にコピー7 ndarray数组的堆叠、拆分
np.vstack()函数和np.hstack()函数>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])ログイン後にコピーcolumn_stack()函数将1D数组作为列堆叠到2D数组中。>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])ログイン後にコピーhsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]ログイン後にコピー
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



