


大規模な言語モデルの急速な「突然変異」により、人間社会の方向性はますますSF化しています。このテクノロジーツリーが点灯すると、『ターミネーター』の現実がどんどん私たちに近づいてきているように思えます。
数日前、Microsoft は、ChatGPT を使用してロボットやドローンを制御できる実験的なフレームワークを発表したばかりです。
もちろん、Google も遅れを取っていません。月曜日、Google とベルリン工科大学のチームは、史上最大のビジュアル言語モデルである PaLM-E を発表しました。

紙のアドレス: https://arxiv.org/abs/2303.03378
マルチモーダルな具体化された視覚言語モデル (VLM) として、PaLM-E は画像を理解するだけでなく、言語を理解して生成することもでき、さらにその 2 つを組み合わせて複雑なロボット命令を処理することもできます。
さらに、PaLM-540B 言語モデルと ViT-22B ビジュアル Transformer モデルの組み合わせにより、PaLM-E の最終的なパラメータ数は 5,620 億にも達します。

PaLM-E , 正式名称はPathways Language Model with Embodiedで、具体化されたビジュアル言語モデルです。
その威力は、視覚データを使用して言語処理能力を強化できることにあります。

#最大の視覚言語モデルをトレーニングし、それをロボットと組み合わせると何が起こるでしょうか?その結果、PaLM-E は 5,620 億パラメータの普遍的で具体化された視覚言語のジェネラリストであり、ロボット工学、視覚、言語を横断します
論文によると、PaLM-Eは、プレフィックスまたはプロンプトを指定して自己回帰的にテキスト補完を生成できるデコーダ専用 LLM です。トレーニング データは、視覚的な連続状態推定とテキスト入力エンコーディングを含むマルチモーダル センテンスです。
単一の画像プロンプトでトレーニングした後、PaLM-E はロボットがさまざまな複雑なタスクを完了できるようにガイドするだけでなく、画像を説明する言語を生成することもできます。
PaLM-E は前例のない柔軟性と適応性を示し、特に人間とコンピューターのインタラクションの分野で大きな進歩を遂げたと言えます。
さらに重要なのは、複数のロボットと一般的な視覚言語を組み合わせたさまざまなハイブリッドタスクのトレーニングにより、視覚言語から身体的な意思決定への移行につながる可能性があることを研究者らが実証したことです。タスクを計画するときにデータを効果的に活用します。
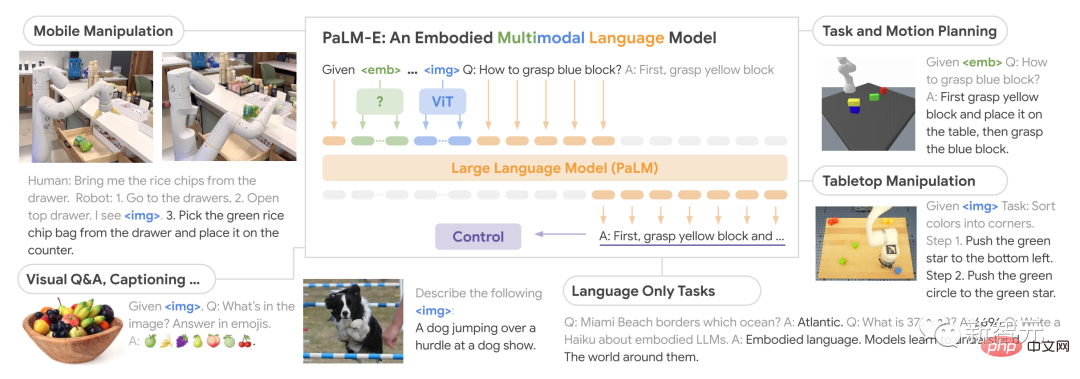
インターネット規模での一般的な視覚言語タスクを含む、さまざまなドメインでトレーニングされた PaLM-E は、単一タスクを実行するロボット モデルと比較して大幅に向上したパフォーマンスを実現します。
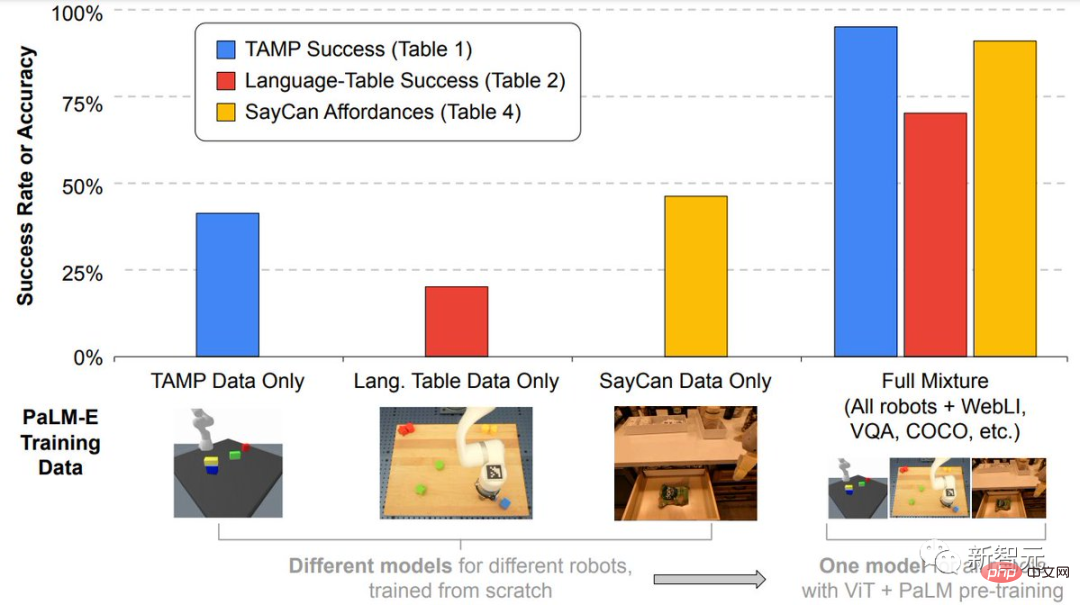
言語モデルが大きいほど、視覚言語およびロボットタスクのトレーニング中により強力な言語能力が維持されます。 モデル スケールの観点から見ると、5,620 億個のパラメーターを備えた PaLM-E は、その言語機能のほぼすべてを維持しています。 PaLM-E は、単一の画像のみでトレーニングされているにもかかわらず、マルチモーダル思考連鎖推論や複数画像推論などのタスクで優れた能力を示します。 OK-VQA ベンチマークでは、PaLM-E が新しい SOTA を達成しました。 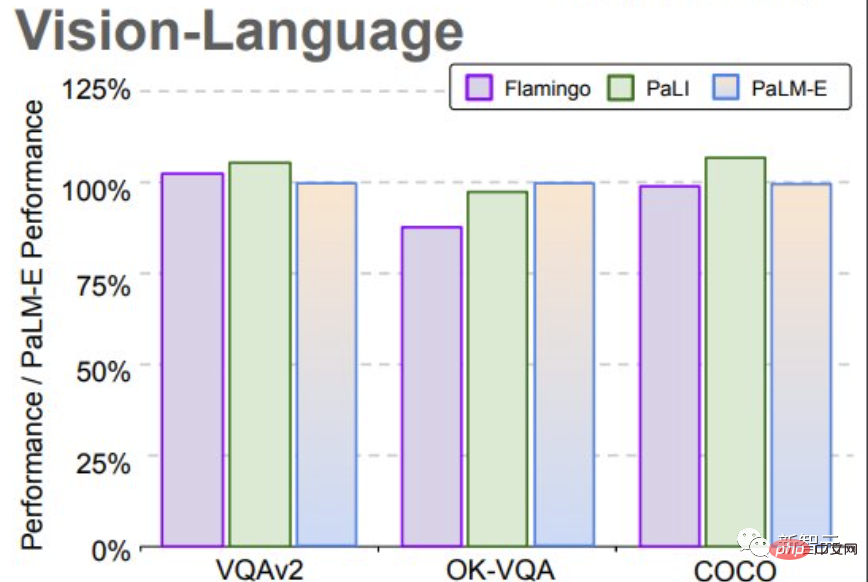
研究者らはテストで、PaLM の使用方法を示しました。 -E は、2 つの異なるエンティティに対して計画タスクと長期にわたるタスクを実行します。
これらの結果はすべて、同じデータでトレーニングされた同じモデルを使用して得られたものであることは注目に値します。
これまで、ロボットが長期にわたるタスクを完了するには通常人間の支援が必要でした。しかし今では、PaLM-E は自主学習を通じてそれを行うことができます。

たとえば、「引き出しからポテトチップスを取り出す」などの指示には、複数の計画ステップが含まれます。ロボットのカメラからの視覚的なフィードバック。
PaLM-E はエンドツーエンドでトレーニングされており、ピクセルから直接ロボットを計画できます。このモデルは制御ループに統合されているため、ロボットはポテトチップスを選ぶ際の途中での外乱に対して堅牢です。
人間: ポテトチップスをください。
ロボット: 1. 引き出しに行きます。 2. 一番上の引き出しを開けます。 3. 一番上の引き出しから緑色のポテトチップスを取り出します。 4. カウンターの上に置きます。

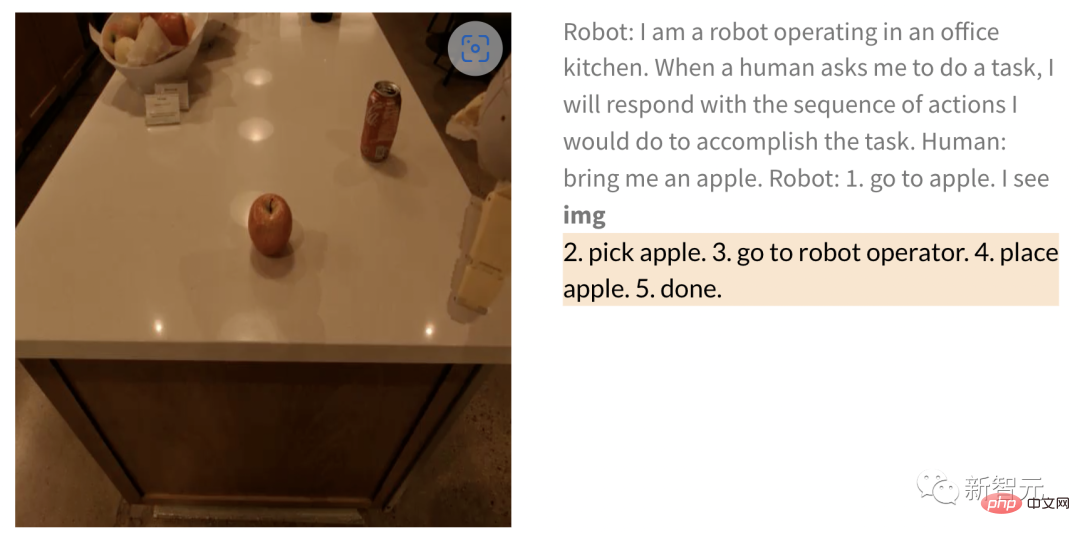
同様に、ロボットにリンゴを拾うように指示する場合、写真が与えられた後、次の手順が実行されます。ロボットがタスクを実行する手順は次のとおりです。 ——
人間: リンゴを持ってきてください。
ロボット: 1. リンゴのところに行きます。 2. リンゴを拾います。 3. リンゴをオペレーターのところに持ってきます。 4. リンゴを置きます。 5. 完了します。
PaLM-E では、長期にわたるタスクの実行に加えて、ロボットが計画タスクを実行できるようにすることができます。 、積み木を並べるなど。
研究者らは、視覚的および口頭による入力に基づいて複数段階の計画を実行し、長期的な視覚的フィードバックと組み合わせて、モデルが長期的なタスクを適切に計画できるようにすることに成功しました。ブロックを色ごとに異なるコーナーに配置します。」
以下のように、配置と組み合わせに関して、ロボットはジェネラリストに変形し、色に従って構成要素を分類します。
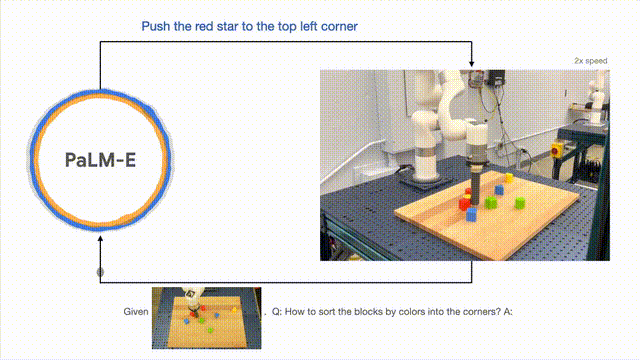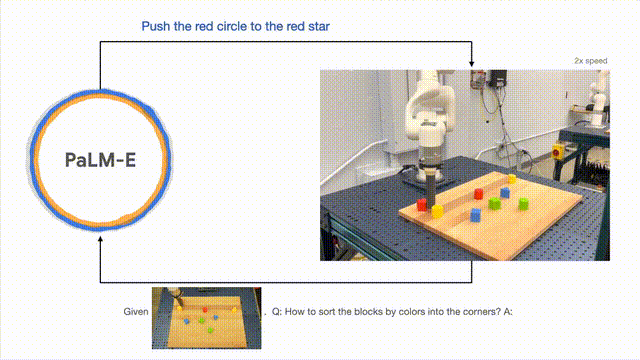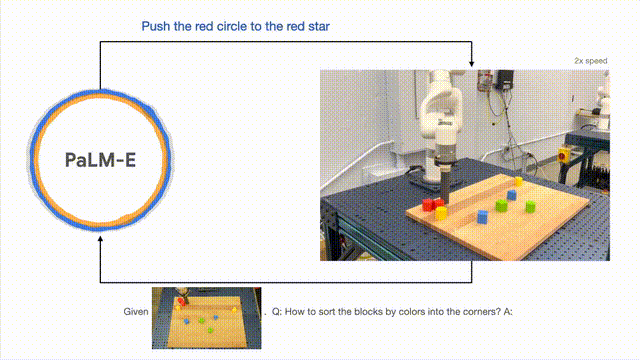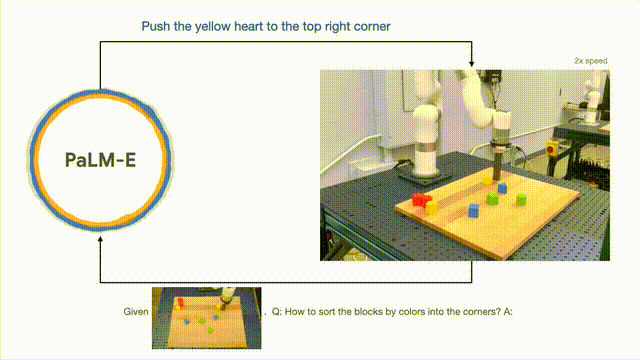
モデルの一般化の観点から、PaLM-E によって制御されるロボットは、赤いビルディング ブロックをコーヒーカップの側面。
データ セットにはコーヒー カップを使用した 3 つのデモンストレーションのみが含まれていますが、それらのどれにも赤い構成要素は含まれていないことに注意してください。

同様に、モデルはこれまでカメを見たことがありませんが、緑色のブロックをカメに押し込むことができます。

ゼロショット推論に関して言えば、PaLM-E は画像を与えられてジョークを言い、ショーを行うことができます。能力には、知覚、ビジョンに基づいた対話、計画が含まれます。
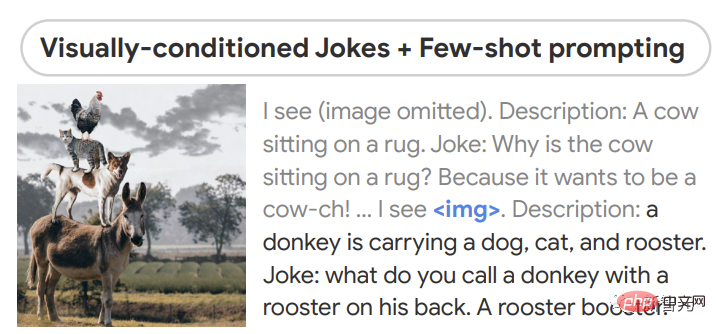
PaLM-E は複数の画像間の関係も理解します。たとえば、画像 1 (左) は画像内にあります。 2つ(右)のどの位置。

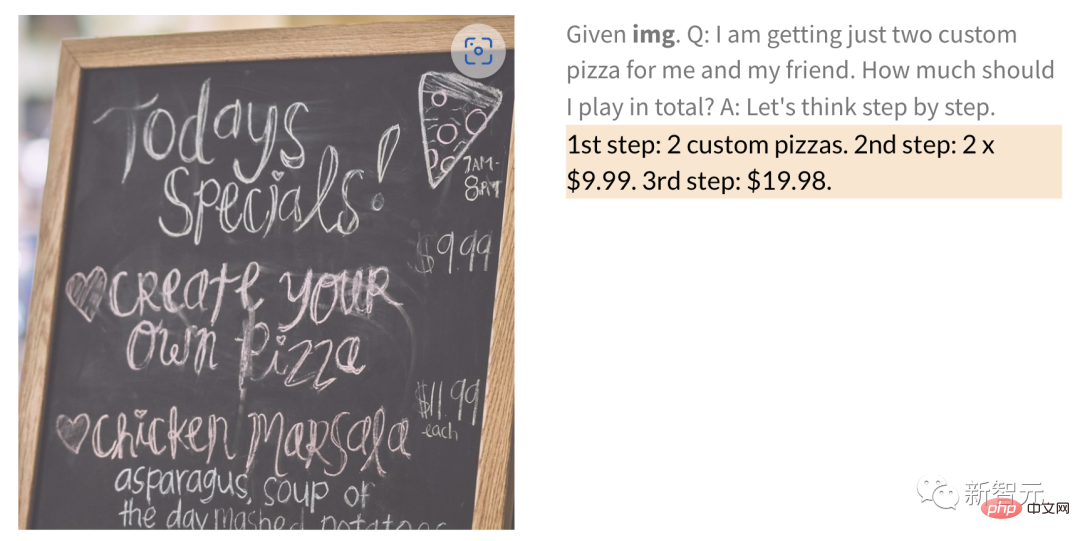
さらに、PaLM-E は、手書きの数字が含まれる画像を指定して数学演算を実行できます。
たとえば、次の手書きのレストラン メニューの場合、PaLM-E はピザ 2 枚の値段を直接計算できます。
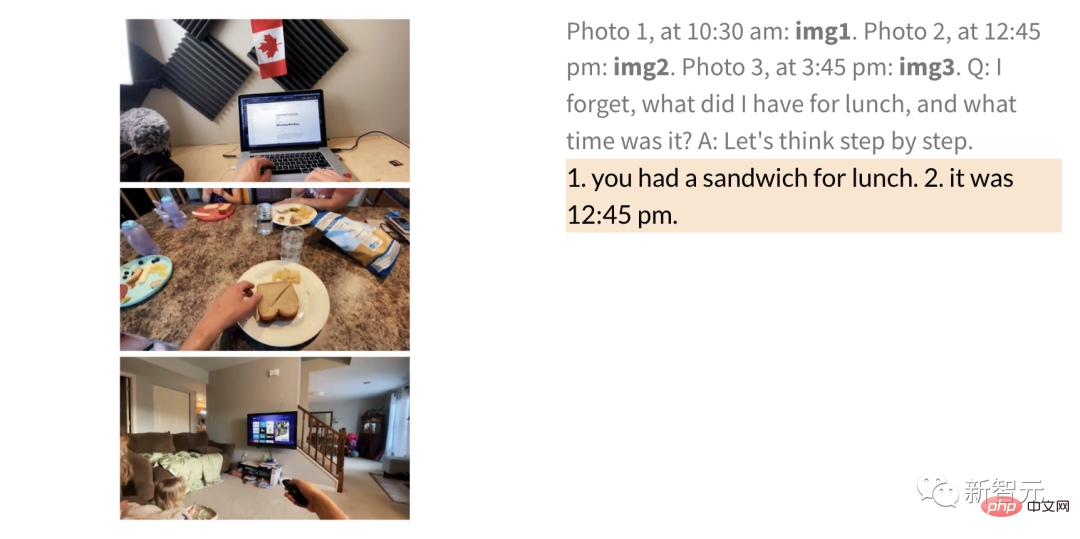
一般的な QA、注釈、その他のタスクも同様です。
最後に、この調査結果は、凍結された言語モデルが、言語機能を完全に保持する普遍的な具体化モデルへのゲートウェイであることも示唆しています。 . モーダルモデルの実現可能な道。
しかし同時に、研究者らはモデルの凍結を解除する別の方法、つまり言語モデルのサイズを増やすことで壊滅的な忘却を大幅に減らすことができることも発見しました。
以上がGoogleは、ターミネーターで最も強力な頭脳として知られ、5,620億個のパラメータを持ち、画像を通じてロボットと対話できる史上最大の汎用モデルPaLM-Eをリリースしました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



