


GPT-4 が今週リリースされると報告されており、マルチモダリティがそのハイライトの 1 つになるでしょう。現在の大規模言語モデルは、さまざまなモダリティを理解するための普遍的なインターフェースになりつつあり、さまざまなモダリティ情報に基づいて返信テキストを与えることができますが、大規模言語モデルによって生成されるコンテンツはテキストに限定されます。一方、現行の拡散モデルであるDALL・E 2、Imagen、Stable Diffusionなどはビジュアル制作に革命を起こしていますが、これらのモデルはテキストから画像への単一のクロスモーダル機能のみをサポートしており、まだ十分とは言えません。普遍的な生成モデルからの距離。マルチモーダル大規模モデルは、さまざまなモダリティの機能を解放し、任意のモダリティ間の変換を実現することができ、これがユニバーサル生成モデルの将来の開発方向であると考えられています。
清華大学コンピューターサイエンス学部の Zhu Jun 教授が率いる TSAIL チームは最近、論文「One Transformer fits All Distributions in Multi-Modal Diffusion at Scale」を発表しました。マルチモーダルを最初に公開した人 生成モデルに関するいくつかの探索的な作業により、任意のモード間の相互変換が可能になりました。

紙のリンク: https://ml.cs.tsinghua .edu.cn/diffusion/unidiffuser.pdf
##オープンソース コード: https://github.com/thu-ml/unidiffuser この論文は、マルチモダリティ向けに設計された確率的モデリング フレームワーク UniDiffuser を提案し、オープンソースの大規模グラフィックおよびテキスト データを使用するためにチームが提案したトランスフォーマー ベースのネットワーク アーキテクチャ U-ViT を採用します。 10 億のパラメータを持つモデルは LAION-5B でトレーニングされ、基礎となるモデルがさまざまな生成タスクを高品質で完了できるようになりました (図 1)。簡単に言うと、一方向のテキスト生成に加えて、画像生成、画像とテキストの結合生成、無条件の画像とテキスト生成、画像とテキストの書き換えなどの複数の機能も実現でき、制作効率が大幅に向上します。テキストと画像コンテンツの効率を高め、テキストとグラフィックスの生成をさらに向上させる 数式モデルの応用想像力。
この論文の筆頭著者である Bao Fan は現在博士課程の学生であり、Analytic-DPM の前の提案者であり、ICLR 2022 の優秀論文賞を受賞しました (現在は、 1 つだけ)拡散モデルにおける彼の優れた業績に対して、本土部隊が独自に完成させた賞を受賞した論文)。
さらに、Machine Heart は、TSAIL チームによって提案された DPM-Solver 高速アルゴリズムについて以前に報告しました。これは、依然として拡散モデルの最速生成アルゴリズムです。マルチモーダル大規模モデルは、チームによる長期にわたる徹底的なアルゴリズムと深い確率モデルの原理の蓄積を集中的に示したものです。この研究の共同研究者には、人民大学ヒルハウス人工知能大学院の Li Chongxuan 氏、北京知源研究所の Cao Yue 氏などが含まれます。

効果の表示
以下の図 9 は、テキストから画像への UniDiffuser の効果を示しています。
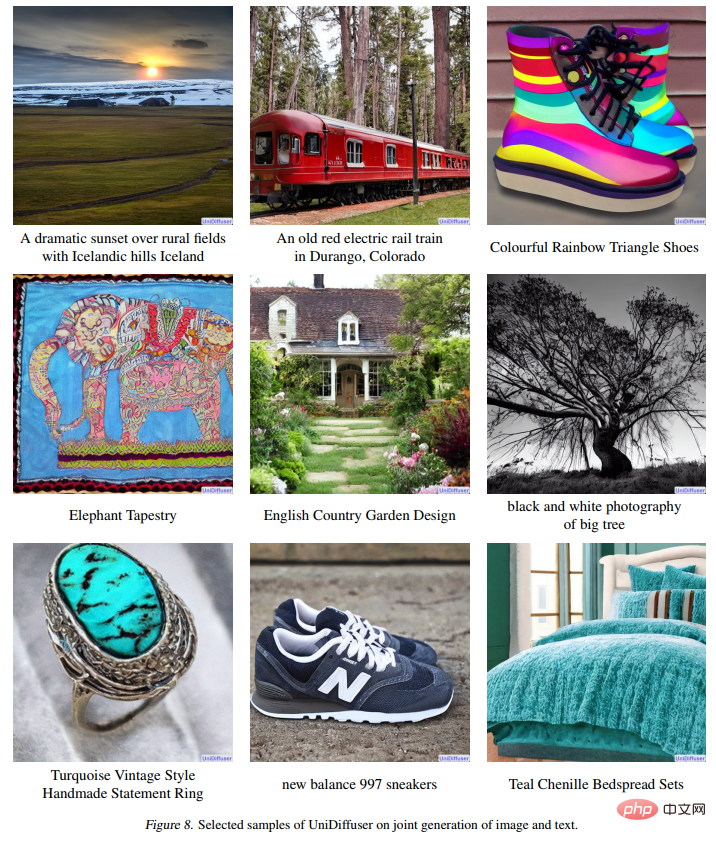
次の図 10 は、画像からテキストへの UniDiffuser の効果を示しています。

#次の図11 無条件画像生成に対する UniDiffuser の効果を示します:

次の図 12 は、画像書き換えに対する UniDiffuser の効果を示しています。

次の図 15以下の図 16 に示すように、UniDiffuser がグラフィックスとテキストの 2 つのモード間を行き来できることを示しています。 UniDiffuser は 2 つの実際の画像を補間できます:
方法の概要

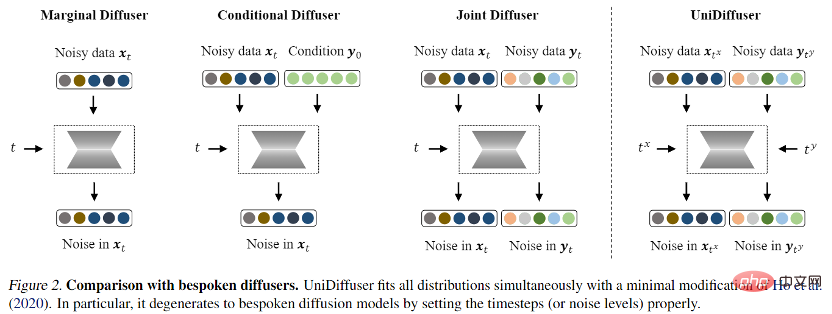
確率的モデリング フレームワーク: 画像とテキスト間のエッジ分布、条件付き分布、結合分布など、モード間のすべての分布を同時にモデル化できる確率的モデリング フレームワークを見つけることは可能ですか? 、など?
ネットワーク アーキテクチャ: さまざまな入力方式をサポートするように統合ネットワーク アーキテクチャを設計できますか?
# 二峰性モードを例として挙げると、最終的なトレーニング目的関数は次のとおりです。
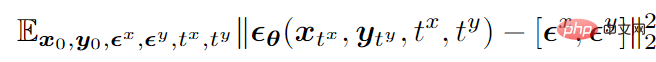


 ## は、2 つのモードで同時にノイズを予測するノイズ予測ネットワークです。
## は、2 つのモードで同時にノイズを予測するノイズ予測ネットワークです。
トレーニング後、UniDiffuser は 2 つのモダリティに適切な時間をノイズ予測ネットワークに設定することで、無条件、条件付き、および共同生成を実現できます。たとえば、テキストの時間を 0 に設定すると、テキストから画像への生成が実現できます。テキストの時間を最大値に設定すると、無条件の画像生成が実現できます。画像とテキストの時間を同じ値に設定すると、画像とテキストの共同生成。
UniDiffuser のトレーニング アルゴリズムとサンプリング アルゴリズムを以下に示しますが、これらのアルゴリズムは元の拡散モデルと比較してわずかな変更しか加えておらず、実装が簡単であることがわかります。

さらに、UniDiffuser は条件付き分布と無条件分布の両方をモデル化するため、UniDiffuser は分類子を使用しないガイダンスを自然にサポートします。以下の図 3 は、さまざまなガイダンス スケールにおける UniDiffuser の条件付き生成と共同生成の効果を示しています。

ネットワーク アーキテクチャ
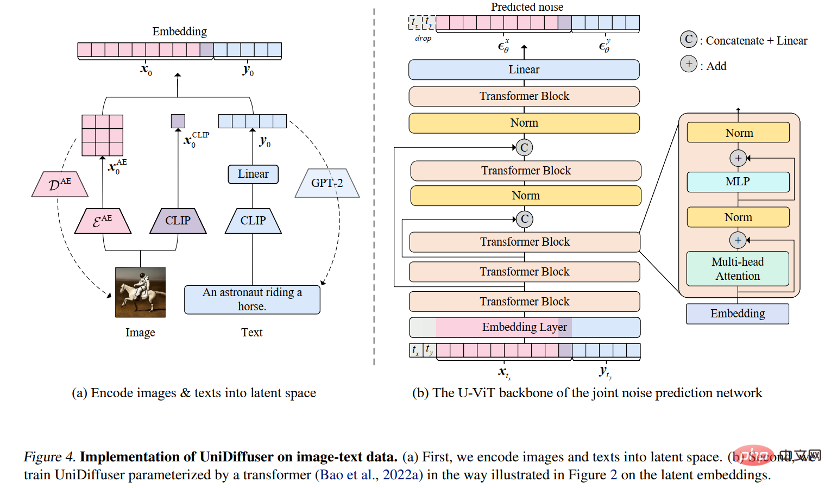
#ネットワーク アーキテクチャを考慮して、研究チームは、変圧器ベースのアーキテクチャを使用してノイズ予測ネットワークをパラメータ化することを提案しました。具体的には、研究チームは最近提案された U-ViT アーキテクチャを採用しました。 U-ViT はすべての入力をトークンとして扱い、トランス ブロック間に U 字型の接続を追加します。研究チームはまた、安定拡散戦略を採用して、さまざまなモダリティのデータを潜在空間に変換し、拡散モデルをモデル化しました。 U-ViT アーキテクチャもこの研究チームから提供され、https://github.com/baofff/U-ViT でオープンソース化されていることは注目に値します。
UniDiffuser はまず Versatile Diffusion と比較されました。 Versatile Diffusion は、マルチタスク フレームワークに基づいた過去のマルチモーダル普及モデルです。まず、UniDiffuser と Versatile Diffusion をテキストから画像への効果について比較しました。以下の図 5 に示すように、UniDiffuser は、さまざまな分類子を使用しないガイダンス スケールの下で、CLIP スコアと FID メトリクスの両方において Versatile Diffusion よりも優れています。
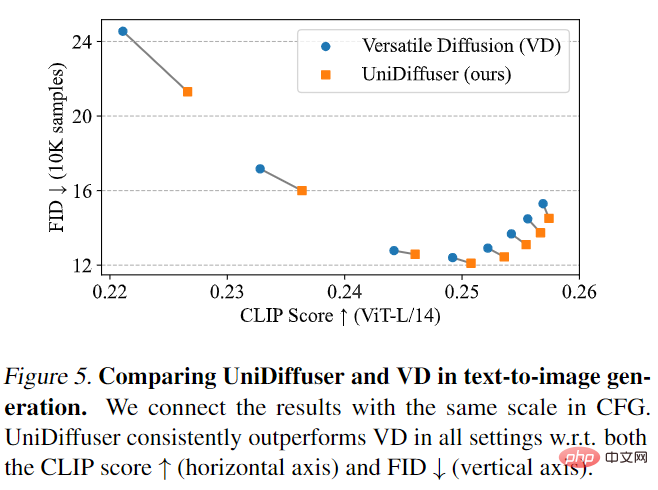
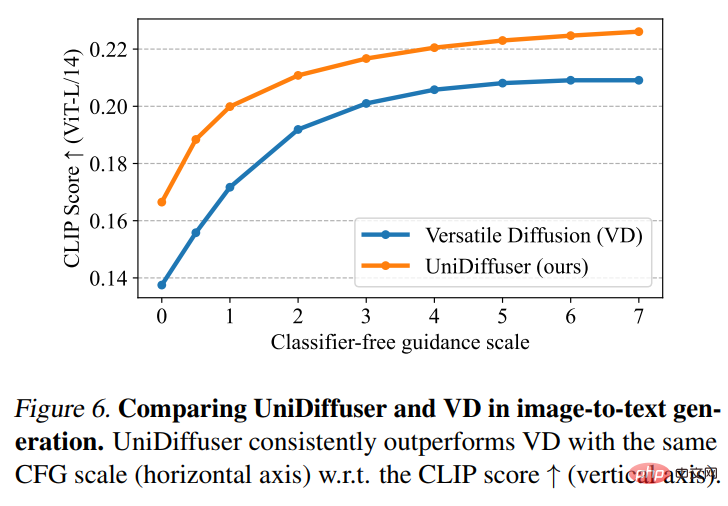
次に、UniDiffuser と Versatile Diffusion が画像とテキストの比較を実行しました。以下の図 6 に示すように、UniDiffuser は画像からテキストへのクリップ スコアが優れています。
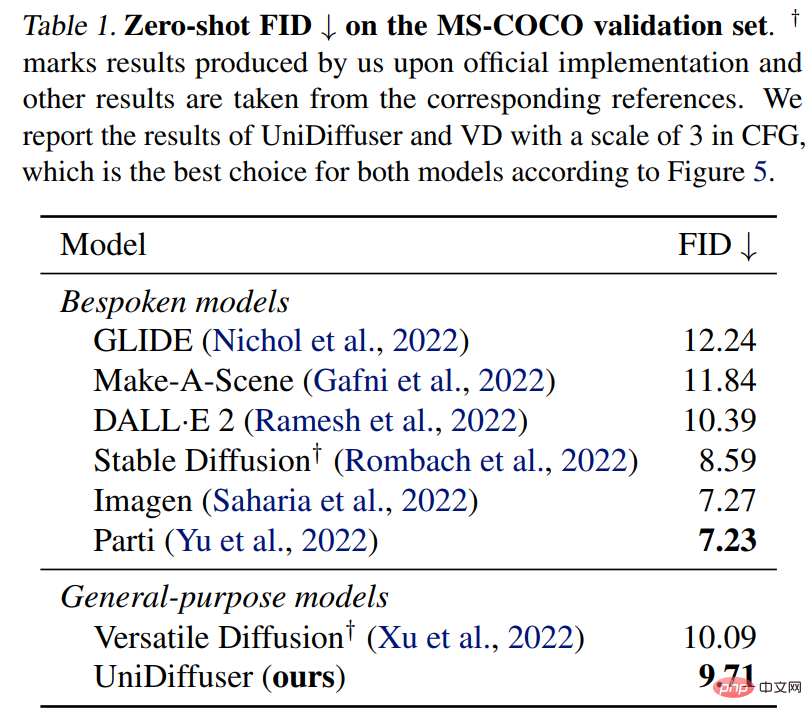
UniDiffuser は、MS-COCO 上で専用のテキストからグラフへのモデルとのゼロショット FID 比較も実行します。以下の表 1 に示すように、UniDiffuser は専用のテキストからグラフへのモデルと同等の結果を達成できます。
以上がZhu Jun 氏のチームは、清華大学の Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の書き換えを経て完全に完成しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



