


Doug Lea 氏の働きのおかげで、HashMap は最も頻繁に使用され、インタビューされる API になりました。これをうまく設計する方法はありません。
HashMap は JDK 1.2 で初めて登場し、基礎となる実装はハッシュ アルゴリズムに基づいています。 HashMap では null キーと null 値が許可されます。ハッシュ キーのハッシュ値を計算する場合、null キーのハッシュ値は 0 になります。 HashMap はキーと値のペアの順序を保証しません。つまり、特定の操作後にキーと値のペアの順序が変わる可能性があります。さらに、HashMap は非スレッドセーフなクラスであるため、マルチスレッド環境では問題が発生する可能性があることに注意してください。
HashMap は、JDK 1.2 で初めて登場しました。最下層はハッシュ アルゴリズムに基づいています。数世代にわたる最適化と更新により、そのソース コードはこれまでより複雑になり、多くの知識ポイントが含まれています。JDK に含まれています1.8; 1. ハッシュテーブル実装、2. 外乱関数、3. 初期化容量、4. 負荷係数、5. 拡張要素分割、6. リンクリストツリー形成、7. 赤黒ツリー、8. 挿入、9. 検索、10. 削除、11. トラバース、12. セグメントロックなど、多くの知識が関係するため、個別に説明する必要がありますが、この章では、最初にデータに関する最初の 5 つの項目に焦点を当てます。構造物の使用。
データ構造は数学に関連することがよくあります。学習プロセス中に実験検証のために、対応するソース コードをダウンロードすることをお勧めします。このプロセスは少し頭が痛いかもしれませんが、学習後は理解できるでしょう。丸暗記せずに知識の一部を得る。
この章に関連するソース コードとリソースは、
100,000 ワードのテスト データを含む、プロジェクト Interview-04 のドキュメントにあります。フォルダー
摂動関数 Excel 表示、doc フォルダー内
#テスト ソース コード部分は、interview-04 プロジェクトにあります
公開アカウントをフォローすることで入手できます。 bugstack ワームホール スタックとダウンロードへの返信 {ダウンロードへの返信後に取得したリンクを開き、番号 ID: 19 を確認します}
HashMap を学習する前に、最も重要なことは、まずデータを保存するためのデータ構造がどのようなものであるかを理解することです。 HashMap の複数のバージョンを繰り返し処理した後でも、コードは一見すると非常に複雑です。昔は短パンしか履いていなかったのに、今ではロングジョンとウィンドブレーカーも着るようになったのと同じです。そこで、まず最も基本的な HashMap がどのようなものであるか、つまりパンツのみを着用した場合にどのような影響があるかを見てから、そのソース コードを分析してみましょう。
質問: 配列に格納する必要がある 7 つの文字列のセットがあるが、各要素を取得する際の時間計算量は O(1) である必要があるとします。つまり、ループ トラバーサルでは取得できませんが、配列 ID を見つけて、対応する要素を直接取得する必要があります。
解決策: ID によって配列から要素を取得する必要がある場合は、各文字列の配列内の位置 ID を計算する必要があります。文字列から ID を取得するにはどのような方法が考えられますか?文字列から数値関連の情報を取得する最も直接的な方法は HashCode ですが、HashCode の値の範囲は [-2147483648, 2147483647] と大きすぎるため、直接使用することはできません。次に、HashCode と配列の長さを使用して AND 演算を実行し、配列内に表示できる位置を取得する必要があります。同じ ID を持つ要素が 2 つある場合、2 つの文字列がこの配列 ID の下に格納されます。
上記は実際には、文字列を配列にハッシュするための基本的なアイデアです。次に、このアイデアをコードに実装します。
// 初始化一组字符串
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("小傅哥");
list.add("e4we");
list.add("alpo");
list.add("yhjk");
list.add("plop");
// 定义要存放的数组
String[] tab = new String[8];
// 循环存放
for (String key : list) {
int idx = key.hashCode() & (tab.length - 1);// 计算索引位置
System.out.println(String.format("key值=%s Idx=%d", key, idx));
if (null == tab[idx]) {
tab[idx] = key;
continue;
}
tab[idx] = tab[idx] + "->" + key;
}
// 输出测试结果
System.out.println(JSON.toJSONString(tab));このコードは全体的に非常にシンプルで複雑さはありません。主に次の内容が含まれています。
key值=jlkk Idx=2 key值=lopi Idx=4 key值=小傅哥 Idx=7 key值=e4we Idx=5 key值=alpo Idx=2 key值=yhjk Idx=0 key值=plop Idx=5 测试结果:["yhjk",null,"jlkk->alpo",null,"lopi","e4we->plop",null,"小傅哥"]

以上我们实现了一个简单的HashMap,或者说还算不上HashMap,只能算做一个散列数据存放的雏形。但这样的一个数据结构放在实际使用中,会有哪些问题呢?
以上这些问题可以归纳为;扰动函数、初始化容量、负载因子、扩容方法以及链表和红黑树转换的使用等。接下来我们会逐个问题进行分析。
在HashMap存放元素时候有这样一段代码来处理哈希值,这是java 8的散列值扰动函数,用于优化散列效果;
static final int hash(Object key){
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}理论上来说字符串的hashCode是一个int类型值,那可以直接作为数组下标了,且不会出现碰撞。但是这个hashCode的取值范围是[-2147483648, 2147483647],有将近40亿的长度,谁也不能把数组初始化得这么大,内存也是放不下的。
我们默认初始化的Map大小是16个长度 DEFAULT_INITIAL_CAPACITY = 1 << 4,所以获取的Hash值并不能直接作为下标使用,需要与数组长度进行取模运算得到一个下标值,也就是我们上面做的散列列子。
那么,hashMap源码这里不只是直接获取哈希值,还进行了一次扰动计算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移16位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。计算方式如下图;

bugstack.cn 扰动函数
从上面的分析可以看出,扰动函数使用了哈希值的高半区和低半区做异或,混合原始哈希码的高位和低位,以此来加大低位区的随机性。
但看不到实验数据的话,这终究是一段理论,具体这段哈希值真的被增加了随机性没有,并不知道。所以这里我们要做一个实验,这个实验是这样做;
扰动函数对比方法
public class Disturb {
public static int disturbHashIdx(String key, int size){
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
public static int hashIdx(String key, int size){
return (size - 1) & key.hashCode();
}
}单元测试
// 10万单词已经初始化到words中
@Test
public void test_disturb(){
Map<Integer, Integer> map = new HashMap<>(16);
for (String word : words) {
// 使用扰动函数
int idx = Disturb.disturbHashIdx(word, 128);
// 不使用扰动函数
// int idx = Disturb.hashIdx(word, 128);
if (map.containsKey(idx)) {
Integer integer = map.get(idx);
map.put(idx, ++integer);
} else {
map.put(idx, 1);
}
}
System.out.println(map.values());
}以上分别统计两种函数下的下标值分配,最终将统计结果放到excel中生成图表。
以上的两张图,分别是没有使用扰动函数和使用扰动函数的,下标分配。实验数据;
未使用扰动函数

bugstack.cn 未使用扰动函数
使用扰动函数

bugstack.cn 使用扰动函数
接下来我们讨论下一个问题,从我们模仿HashMap的例子中以及HashMap默认的初始化大小里,都可以知道,散列数组需要一个2的幂次方的长度,因为只有2的幂次方在减1的时候,才会出现01111这样的值。
那么这里就有一个问题,我们在初始化HashMap的时候,如果传一个17个的值new HashMap<>(17);,它会怎么处理呢?
在HashMap的初始化中,有这样一段方法;
public HashMap(int initialCapacity, float loadFactor){
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}计算阈值大小的方法;
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}那这里我们把17这样一个初始化计算阈值的过程,用图展示出来,方便理解;
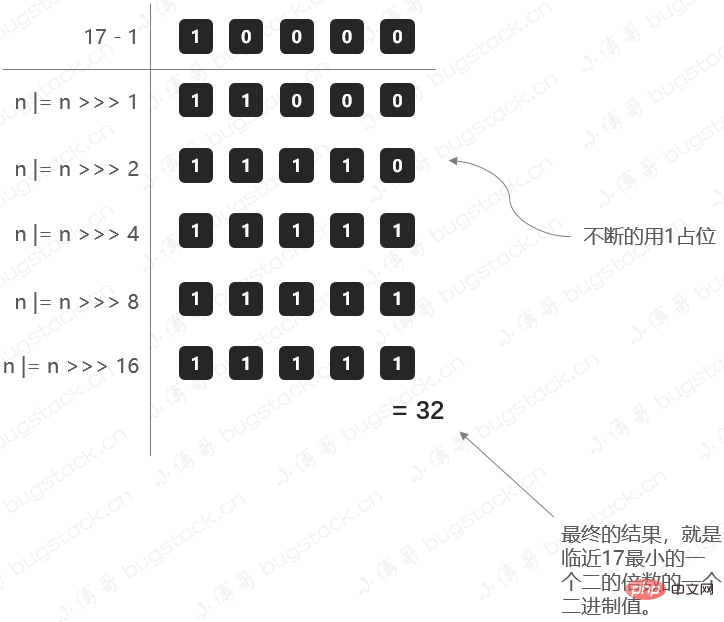
bugstack.cn 计算阈值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子是做什么的?
负载因子,可以理解成一辆车可承重重量超过某个阈值时,把货放到新的车上。
那么在HashMap中,负载因子决定了数据量多少了以后进行扩容。这里要提到上面做的HashMap例子,我们准备了7个元素,但是最后还有3个位置空余,2个位置存放了2个元素。 所以可能即使你数据比数组容量大时也是不一定能正正好好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了Map数组的性能。
所以,要选择一个合理的大小下进行扩容,默认值0.75就是说当阈值容量占了3/4时赶紧扩容,减少Hash碰撞。
同时0.75是一个默认构造值,在创建HashMap也可以调整,比如你希望用更多的空间换取时间,可以把负载因子调的更小一些,减少碰撞。
为什么扩容,因为数组长度不足了。那扩容最直接的问题,就是需要把元素拆分到新的数组中。拆分元素的过程中,原jdk1.7中会需要重新计算哈希值,但是到jdk1.8中已经进行优化,不再需要重新计算,提升了拆分的性能,设计的还是非常巧妙的。
@Test
public void test_hashMap(){
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("jmdw");
list.add("e4we");
list.add("io98");
list.add("nmhg");
list.add("vfg6");
list.add("gfrt");
list.add("alpo");
list.add("vfbh");
list.add("bnhj");
list.add("zuio");
list.add("iu8e");
list.add("yhjk");
list.add("plop");
list.add("dd0p");
for (String key : list) {
int hash = key.hashCode() ^ (key.hashCode() >>> 16);
System.out.println("字符串:" + key + " tIdx(16):" + ((16 - 1) & hash) + " tBit值:" + Integer.toBinaryString(hash) + " - " + Integer.toBinaryString(hash & 16) + " ttIdx(32):" + ((
System.out.println(Integer.toBinaryString(key.hashCode()) +" "+ Integer.toBinaryString(hash) + " " + Integer.toBinaryString((32 - 1) & hash));
}
}测试结果
字符串:jlkkIdx(16):3Bit值:1100011101001000010011 - 10000 Idx(32):19 1100011101001000100010 1100011101001000010011 10011 字符串:lopiIdx(16):14Bit值:1100101100011010001110 - 0 Idx(32):14 1100101100011010111100 1100101100011010001110 1110 字符串:jmdwIdx(16):7Bit值:1100011101010100100111 - 0 Idx(32):7 1100011101010100010110 1100011101010100100111 111 字符串:e4weIdx(16):3Bit值:1011101011101101010011 - 10000 Idx(32):19 1011101011101101111101 1011101011101101010011 10011 字符串:io98Idx(16):4Bit值:1100010110001011110100 - 10000 Idx(32):20 1100010110001011000101 1100010110001011110100 10100 字符串:nmhgIdx(16):13Bit值:1100111010011011001101 - 0 Idx(32):13 1100111010011011111110 1100111010011011001101 1101 字符串:vfg6Idx(16):8Bit值:1101110010111101101000 - 0 Idx(32):8 1101110010111101011111 1101110010111101101000 1000 字符串:gfrtIdx(16):1Bit值:1100000101111101010001 - 10000 Idx(32):17 1100000101111101100001 1100000101111101010001 10001 字符串:alpoIdx(16):7Bit值:1011011011101101000111 - 0 Idx(32):7 1011011011101101101010 1011011011101101000111 111 字符串:vfbhIdx(16):1Bit值:1101110010111011000001 - 0 Idx(32):1 1101110010111011110110 1101110010111011000001 1 字符串:bnhjIdx(16):0Bit值:1011100011011001100000 - 0 Idx(32):0 1011100011011001001110 1011100011011001100000 0 字符串:zuioIdx(16):8Bit值:1110010011100110011000 - 10000 Idx(32):24 1110010011100110100001 1110010011100110011000 11000 字符串:iu8eIdx(16):8Bit值:1100010111100101101000 - 0 Idx(32):8 1100010111100101011001 1100010111100101101000 1000 字符串:yhjkIdx(16):8Bit值:1110001001010010101000 - 0 Idx(32):8 1110001001010010010000 1110001001010010101000 1000 字符串:plopIdx(16):9Bit值:1101001000110011101001 - 0 Idx(32):9 1101001000110011011101 1101001000110011101001 1001 字符串:dd0pIdx(16):14Bit值:1011101111001011101110 - 0 Idx(32):14 1011101111001011000000 1011101111001011101110 1110

bugstack.cn 数据迁移
那么为什么 e.hash & oldCap == 0 为什么可以判断当前节点是否需要移位, 而不是再次计算hash;
仍然是原始长度为16举例:
old: 10: 0000 1010 15: 0000 1111 &: 0000 1010 new: 10: 0000 1010 31: 0001 1111 &: 0000 1010
从上面的示例可以很轻易的看出, 两次indexFor()的差别只是第二次参与位于比第一次左边有一位从0变为1, 而这个变化的1刚好是oldCap, 那么只需要判断原key的hash这个位上是否为1: 若是1, 则需要移动至oldCap + i的槽位, 若为0, 则不需要移动;
这也是HashMap的长度必须保证是2的幂次方的原因, 正因为这种环环相扣的设计, HashMap.loadFactor的选值是3/4就能理解了, table.length * 3/4可以被优化为((table.length >> 2) > 2) == table.length - (table.length >> 2), JAVA的位运算比乘除的效率更高, 所以取3/4在保证hash冲突小的情况下兼顾了效率;
以上がインタビュー記録: HashMap、外乱関数、負荷率、拡張リンクリスト分割に関するコア知識の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



