


香港中文大学(深セン)のウー・バオユアン教授の研究グループと浙江大学のチン・ザン教授の研究グループは、バックドア防御の分野で共同論文を発表し、無事受理されました。 ICLR2022による。
近年、バックドアの問題が広く注目を集めています。バックドア攻撃が提案され続けるにつれ、一般的なバックドア攻撃に対する防御方法を提案することはますます困難になっています。この論文では、セグメント化されたバックドア トレーニング プロセスに基づいたバックドア防御方法を提案します。
この記事では、バックドア攻撃が、バックドアを特徴空間に投影するエンドツーエンドの教師ありトレーニング手法であることを明らかにしています。これに基づいて、この記事ではバックドア攻撃を回避するためのトレーニング プロセスを分割します。この手法の有効性を証明するために、この手法と他のバックドア防御手法との比較実験が行われました。
#インクルージョン カンファレンス: ICLR2022
##記事リンク: https://arxiv.org/pdf/ 2202.03423 .pdf
コードリンク: https://github.com/SCLBD/DBD
1
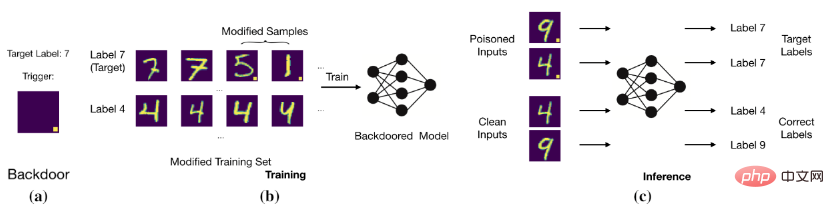 基本的なバックドア攻撃
基本的なバックドア攻撃
2
1. ポイズニング ラベル攻撃: BadNets (Gu et al., 2019) は、最初で最も代表的なポイズニング ラベル攻撃です。その後 (Chen et al., 2017) は、毒された画像の不可視性はその良性の画像の不可視性と同様であるべきであると提案し、これに基づいて混合攻撃が提案されました。最近 (Xue et al., 2020; Li et al., 2020; 2021) は、ポイズニング タグのバックドア攻撃をより秘密裏に実行する方法をさらに研究しました。最近、よりステルスで効果的な攻撃である WaNet (Nguyen & Tran、2021) が提案されました。 WaNet は、画像の歪みをバックドア トリガーとして使用し、画像のコンテンツを変形しながら保持します。
2. クリーン タグ攻撃: ユーザーがイメージとタグの関係をチェックすることでバックドア攻撃に気づくことができるという問題を解決するために、Turner et al. (2019) はクリーン タグ攻撃パラダイムを提案しました。ターゲットラベルは、汚染されたサンプルの元のラベルと一致します。このアイデアは (Zhao et al., 2020b) で攻撃ビデオ分類に拡張され、ターゲット全体の敵対的摂動 (Moosavi-Dezfooli et al., 2017) をトリガーとして採用しました。クリーン タグのバックドア攻撃はポイズン タグのバックドア攻撃よりも巧妙ですが、通常、そのパフォーマンスは比較的低く、バックドアを作成することさえできない可能性があります (Li et al., 2020c)。
#2.2 バックドア防御
1. 検出ベースの防御 (Xu et al, 2021; Zeng et al, 2011; Xiang et al, 2022) は、疑わしいモデルまたはサンプルが攻撃されているかどうかをチェックし、悪意のあるオブジェクトの使用を拒否します。 。
2. 前処理ベースの防御 (Doan et al, 2020; Li et al, 2021; Zeng et al, 2021) は、攻撃サンプルに含まれるトリガー パターンを破壊することを目的としています。バックドアのアクティベーションを防ぐために、モデルに画像を入力する前に前処理モジュールが導入されます。
3. モデルの再構築に基づく防御 (Zhao et al, 2020a; Li et al, 2021;) は、モデルを直接変更することでモデル内の隠れたバックドアを排除することです。
4. 包括的な防御 (Guo et al, 2020; Dong et al, 2021; Shen et al, 2021) を発動するには、まずバックドアを学習し、次にその影響を抑制することで隠れたバックドアを排除します。
5. ポイズニング抑制に基づく防御 (Du et al, 2020; Borgnia et al, 2021) は、隠れたバックドアの生成を防ぐために、トレーニング プロセス中にポイズニングされたサンプルの有効性を低下させます
##1. 半教師あり学習: 現実世界の多くのアプリケーションでは、ラベル付きデータ 多くの場合、手動のラベル付けに依存しますが、これは非常にコストがかかります。それに比べて、ラベルのないサンプルを入手するのははるかに簡単です。ラベルなしサンプルとラベル付きサンプルの両方の力を活用するために、多数の半教師あり学習方法が提案されています (Gao et al., 2017; Berthelot et al, 2019; Van Engelen & Hoos, 2020)。最近では、モデルのセキュリティを向上させるために半教師あり学習も使用されており (Stanforth et al, 2019; Carmon et al, 2019)、敵対的トレーニングでラベルのないサンプルを使用します。最近 (Yan et al、2021) は、半教師あり学習をバックドアする方法について議論しました。ただし、この方法では、トレーニング サンプルの変更に加えて、他のトレーニング コンポーネント (トレーニング損失など) も制御する必要があります。
2. 自己教師あり学習: 自己教師あり学習パラダイムは教師なし学習のサブセットであり、データ自体によって生成された信号を使用してモデルがトレーニングされます (Chen et al、2020a) ;グリルら、2020;リューら、2021)。これは、敵対的な堅牢性を高めるために使用されます(Hendrycks et al、2019; Wu et al、2021; Shi et al、2021)。最近、いくつかの記事 (Saha et al, 2021; Carlini & Terzis, 2021; Jia et al, 2021) では、自己教師あり学習にバックドアを導入する方法が検討されています。ただし、これらの攻撃では、トレーニング サンプルの変更に加えて、他のトレーニング コンポーネント (トレーニング損失など) の制御も必要になります。
CIFAR-10 データセットに対して BadNets 攻撃とクリーンラベル攻撃を実施しました (Krizhevsky、2009)。有害なデータセットでの教師あり学習とラベルのないデータセットでの自己教師あり学習 SimCLR (Chen et al., 2020a)。
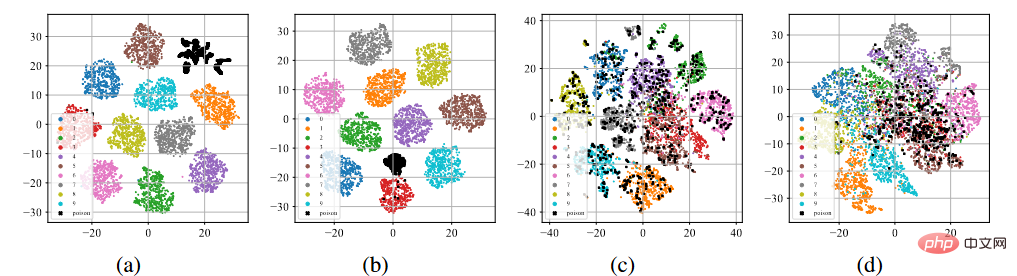
#バックドアの特性の T-sne 表示
に示すように、上の図 (a) ~ (b) に示すように、標準的な教師付きトレーニング プロセスの後、ポイズニングされたサンプル (黒い点で表されます) は、ポイズン ラベル攻撃またはクリーン ラベル攻撃に関係なく、クラスターとなって個別のクラスターを形成する傾向があります。この現象は、既存のポイズニング ベースのバックドア攻撃の成功を示唆しています。過剰学習により、モデルはバックドア トリガーの特性を学習できるようになります。このモデルをエンドツーエンドの教師ありトレーニング パラダイムと組み合わせることで、特徴空間内の汚染されたサンプル間の距離を縮め、学習されたトリガー関連の特徴をターゲット ラベルと結び付けることができます。逆に、上記の図 (c) ~ (d) に示すように、ラベルのない汚染データ セットでは、自己教師ありトレーニング プロセスの後、汚染されたサンプルは元のラベルが付いているサンプルに非常に近くなっています。これは、自己教師あり学習によってバックドアを防止できることを示しています。4
#方法フローチャート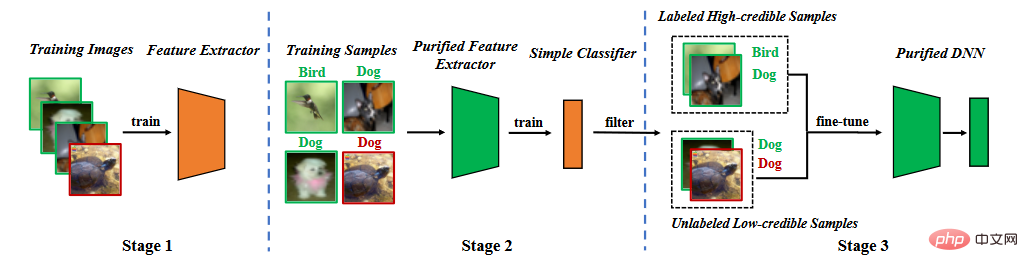 4.1 学習特徴抽出器
4.1 学習特徴抽出器
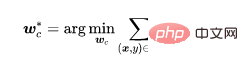 ここで、 は自己教師あり損失です (たとえば、SimCLR の NT-Xent (Chen et al、2020))。 、特徴抽出者がバックドアの機能を学習するのは難しいことがわかります。
ここで、 は自己教師あり損失です (たとえば、SimCLR の NT-Xent (Chen et al、2020))。 、特徴抽出者がバックドアの機能を学習するのは難しいことがわかります。
特徴抽出器がトレーニングされたら、特徴抽出器のパラメーターを修正し、トレーニング データ セットを使用して、さらに完全に学習します。接続層パラメータ ,
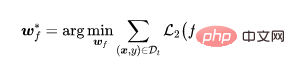
# ここで、 は教師あり学習損失 (たとえば、クロス エントロピー損失 (クロス エントロピー)) です。
このようなセグメンテーション プロセスにより、モデルがバックドアを学習することが困難になりますが、2 つの問題があります。まず、教師あり学習を通じて学習された方法と比較して、学習された特徴抽出器が第 2 段階でフリーズされるため、クリーン サンプルの予測精度がある程度低下します。次に、汚染されたラベル攻撃が発生すると、汚染されたサンプルが「外れ値」として機能し、学習の第 2 段階がさらに妨げられます。これら 2 つの問題は、汚染されたサンプルを削除し、モデル全体を再トレーニングまたは微調整する必要があることを示しています。
サンプルにバックドアがあるかどうかを判断する必要があります。モデルがバックドア サンプルから学習することは困難であると考えられるため、信頼性を区別指標として使用します。信頼性の高いサンプルはクリーンなサンプルであり、信頼性の低いサンプルは汚染されたサンプルです。実験を通じて、以下の図に示すように、対称クロスエントロピー損失を使用してトレーニングされたモデルは、2 つのサンプル間の損失ギャップが大きいため、識別度が高いことがわかります。
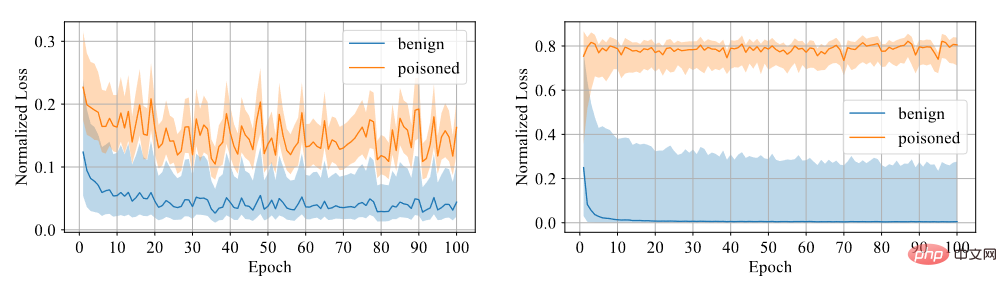
対称クロスエントロピー損失とクロスエントロピー損失の比較
したがって, 対称クロスエントロピー損失を使用した固定特徴抽出器で全結合層をトレーニングし、信頼度のサイズによってデータセットを信頼性の高いデータと信頼性の低いデータにフィルタリングします。
まず、信頼性の低いデータのラベルを削除します。半教師あり学習を使用してモデル全体を微調整します。

ここで、 は半教師あり損失 (MixMatch の損失関数 (Berthelot et al、2019)) です。
半教師あり微調整では、モデルがバックドア トリガーを学習するのを防ぐだけでなく、クリーンなデータ セットでモデルが適切にパフォーマンスを発揮できるようにすることもできます。
この記事は 2 つの古典的なベンチマークに基づいていますデータ すべての防御は、CIFAR-10 (Krizhevsky、2009) および ImageNet (Deng et al.、2009) (サブセット) を含むセットで評価されます。この記事では ResNet18 モデルを使用しています (He et al., 2016)
この記事では、4 つの典型的な攻撃、すなわちバッドネット (Gu et al., 2019) から防御するためのすべての防御方法を研究しています。混合戦略 バックドア攻撃(混合)(Chen et al、2017)、WaNet(Nguyen & Tran、2021)、および敵対的摂動を伴うクリーンラベル攻撃(ラベル一貫性)(Turner et al、2019)。

#バックドア攻撃の例の写真
実験の判定基準は、BA が清浄サンプルの判定精度、ASR が汚染サンプルの判定精度です。
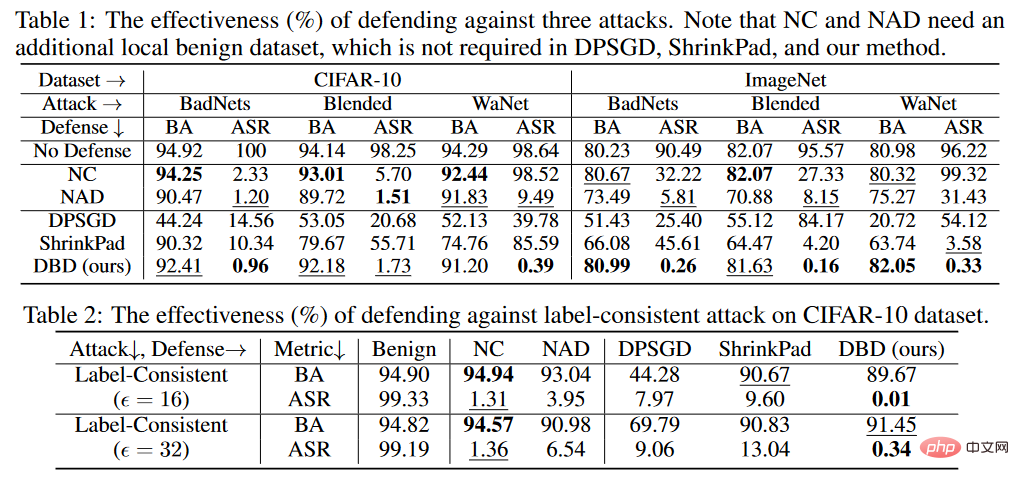
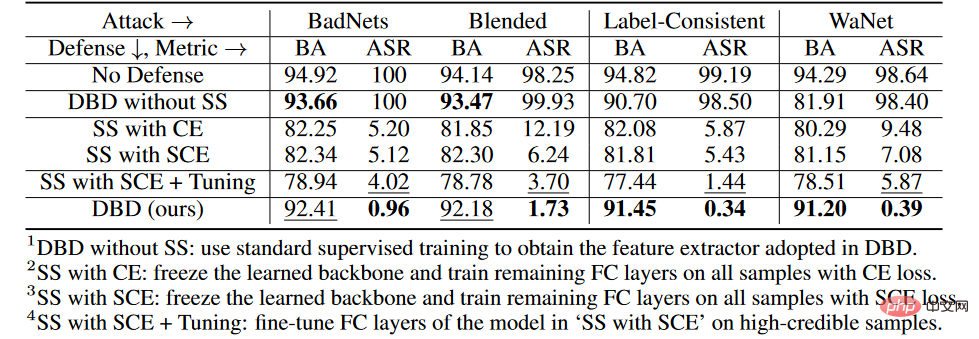
バックドア防御の比較結果 上の表に示されているように、DBD は、すべての攻撃に対して、同じ要件を持つ防御 (つまり、DPSGD と ShrinkPad) よりも大幅に優れています。すべてのケースにおいて、DBD は DPSGD よりも BA が 20% 多く、ASR が 5% 低いという点で優れています。 DBD モデルの ASR はすべてのケースで 2% 未満 (ほとんどの場合 0.5% 未満) であり、DBD が隠れたバックドアの作成を首尾よく防止できることが確認されています。 DBD は、他の 2 つの方法、つまり NC および NAD と比較されます。どちらの方法でも、防御側はクリーンなローカル データ セットを持つ必要があります。 上の表に示すように、NC と NAD は、ローカルのクリーン データ セットからの追加情報を利用するため、DPSGD と ShrinkPad よりも優れたパフォーマンスを発揮します。特に、NAD と NC は追加情報を使用しますが、DBD はそれらよりも優れています。特に ImageNet データセットでは、NC による ASR 削減効果は限定的です。比較すると、DBD は最小の ASR を達成しますが、DBD の BA はほとんどすべてのケースで最高か 2 番目に高くなります。また、防御トレーニングを行わなかったモデルと比較して、毒タグ攻撃に対する防御時のBAの低下は2%未満でした。比較的大きなデータセットでは、すべてのベースライン手法の効果が低下するため、DBD の方がさらに優れています。これらの結果は、DBD の有効性を検証します。 # CIFAR-10 データセットで、提案された DBD とその 4 つのバリアント ( 1 を含む) を比較しました。SS なしの DBD は自己教師あり学習からバックボーンを生成します。トレーニング済みのバックボーンに置き換えます。 CE を使用して、教師ありの方法で他の部分を変更しないでください。 #2.SS を使用して、自己教師あり学習を通じて学習したバックボーンをフリーズし、すべてのトレーニング サンプルで実行します。残りの完全に接続された層 3.SS (SCE あり)。2 番目のバリアントと似ていますが、対称クロスエントロピー損失を使用してトレーニングされています。 4.SS と SCE チューニング。3 番目のバリアントでフィルタリングされた信頼性の高いサンプルの完全に接続されたレイヤーをさらに微調整します。 上の表に示すように、元のエンドツーエンドの教師ありトレーニング プロセスを切り離すことは、隠れたバックドアの作成を防ぐのに効果的です。さらに、2 番目と 3 番目の DBD 亜種を比較して、ポイズン タグ バックドア攻撃に対する防御における SCE 損失の有効性を検証します。さらに、4 番目の DBD 変異の ASR および BA は、3 番目の DBD 変異よりも低くなります。この現象は、信頼性の低いサンプルが削除されたことによるものです。これは、信頼性の低いサンプルからの有用な情報を利用しながら副作用を軽減することが防御にとって重要であることを示唆しています。 5.4 潜在的な適応型攻撃に対する耐性 攻撃設定 分類問題では、汚染する必要があるクリーンなサンプルを表し、サンプルを元のラベルで表し、訓練されたバックボーンであるとします。攻撃者による事前に汚染された画像の生成器が与えられた場合、適応型攻撃は、汚染された画像間の距離を最小限に抑えながら、汚染された画像の中心と、異なるラベルが付いた無害な画像のクラスターの中心との間の距離を最大化することにより、トリガー パターンを最適化することを目的としています。 .距離、つまり。
防御なしの適応攻撃のBAは94.96%、ASRは99.70%でした。ただし、DBDの防御結果はBA93.21%、ASR1.02%でした。言い換えれば、DBD はそのような適応型攻撃に対して耐性があります。 ポイズニングベースのバックドア攻撃のメカニズムは、トレーニング プロセス中にトリガー パターンとターゲット ラベルの間に潜在的な接続を確立することです。この論文では、この接続が主にエンドツーエンドの教師ありトレーニング パラダイム学習によるものであることを明らかにしています。この理解に基づいて、この記事ではデカップリングに基づくバックドア防御方法を提案します。多数の実験により、DBD 防御が良性サンプルの予測において高い精度を維持しながらバックドアの脅威を軽減できることが検証されています。 #5.3 アブレーション実験
攻撃者が DBD の存在を知っている場合、適応型攻撃を設計する可能性があります。攻撃者が防御者が使用するモデル構造を知ることができれば、以下に示すように、自己教師あり学習後にポイズニングされたサンプルが新しいクラスターに残るようにトリガー パターンを最適化することで適応型攻撃を設計できます。
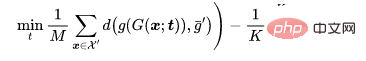
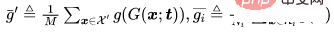 実験結果
実験結果
6 概要
以上が細分化されたバックドアトレーニングのバックドア防御手法:DBDの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



