


この記事では、Damo Academy Magic Community ModelScope によって最近オープンソース化された、中国語 CLIP 大規模な事前トレーニング画像およびテキスト表現モデルを紹介します。これは、中国語および中国のインターネット画像をよりよく理解し、画像やテキストなどの複数のタスクを実行できます。テキスト検索とゼロサンプル画像分類 最良の結果を達成するために、コードとモデルはすべてオープンソースになっているため、ユーザーは Magic を使用してすぐに使い始めることができます。

現在のインターネット エコシステムには、画像とテキストの取得、画像分類、ビデオと画像とテキスト コンテンツ、その他のシナリオなど、無数のマルチモーダル関連タスクとシナリオがあります。近年、インターネット上で人気が高まっている画像生成はさらに人気が高まっており、すぐに世間から消え去ってしまいました。これらのタスクの背後には、強力な画像とテキストの理解モデルが明らかに必要です。 OpenAI が 2021 年に発表した CLIP モデルについては、誰もがよく知っていると思います。単純な画像とテキストのツインタワー比較学習と大量の画像とテキストのコーパスを通じて、このモデルは重要な画像とテキストの特徴の位置合わせ機能を備えており、さまざまな用途に使用できます。ゼロサンプル画像分類では、クロスモーダル検索で優れた結果をもたらし、DALLE2 や安定拡散などの画像生成モデルの主要モジュールとしても使用されます。
しかし、残念なことに、OpenAI CLIP の事前トレーニングでは主に英語世界のグラフィック データとテキスト データが使用されており、当然のことながら中国語をサポートすることはできません。コミュニティ内に、翻訳されたテキストを通じて多言語バージョンの Multilingual-CLIP (mCLIP) を抽出した研究者がいるとしても、彼らは依然として中国語世界のニーズを満たすことができず、中国語分野のテキストに対する理解はあまり良くありません。 「Spring Festival couplets」を検索すると、返されるのはクリスマス関連のコンテンツです:

##mCLIP デモの取得 検索「春節の対句」 結果を返します
これは、中国語をよりよく理解し、言語を理解するだけでなく、中国語のイメージも理解できる CLIP が必要であることも示しています。中華の世界。
2. 方法DAMO アカデミーの研究者は、LAION-5B 中国語のデータを含む、大規模な中国語の画像とテキストのペア データ (サイズ約 2 億) を収集しました。サブセット、Wukong の中国語データ、COCO、Visual Genome などからの翻訳されたグラフィックおよびテキスト データ。トレーニング画像とテキストのほとんどは公開データ セットから取得されているため、再現の困難さが大幅に軽減されます。トレーニング方法に関しては、トレーニング効率とモデルの効果を効果的に向上させるために、研究者らは 2 段階のトレーニング プロセスを設計しました。
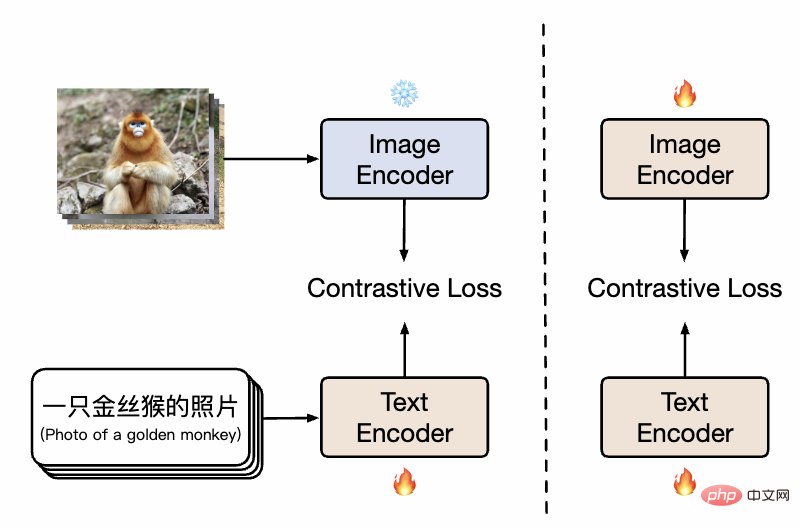
##中国の CLIP メソッドの図
図に示すように、最初の段階では、モデルは既存の画像事前トレーニング モデルを使用します。モデルは、中国語-CLIP のツインタワーを個別に初期化し、画像側パラメータをフリーズします。これにより、トレーニングのオーバーヘッドを削減しながら、言語モデルを既存の画像の事前トレーニング表現空間に関連付けることができます。続いて、第 2 段階では、画像側のパラメータが解凍され、中国語の特徴を持つデータ分布をモデル化しながら、画像モデルと言語モデルを関連付けることができます。研究者らは、最初から事前トレーニングする場合と比較して、この方法は複数の下流タスクで大幅に優れた実験結果を示し、その大幅に高い収束効率はトレーニングのオーバーヘッドも小さいことを意味することを発見しました。トレーニングの 1 段階でテキスト側のみをトレーニングする場合と比較して、トレーニングの 2 段階目を追加すると、下流のグラフィックスおよびテキスト タスク、特に (英語のデータセットから翻訳されたものではなく) 中国語ネイティブのグラフィックスとテキスト タスクに対する効果をさらに効果的に向上させることができます。
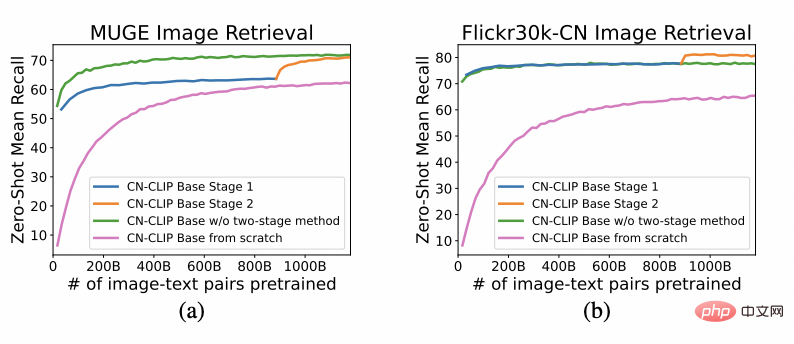
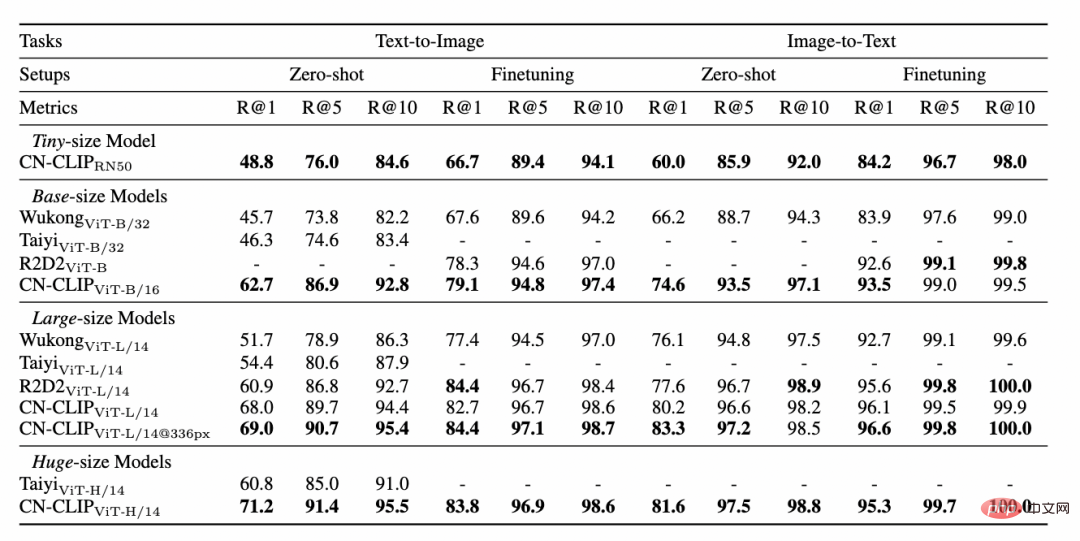
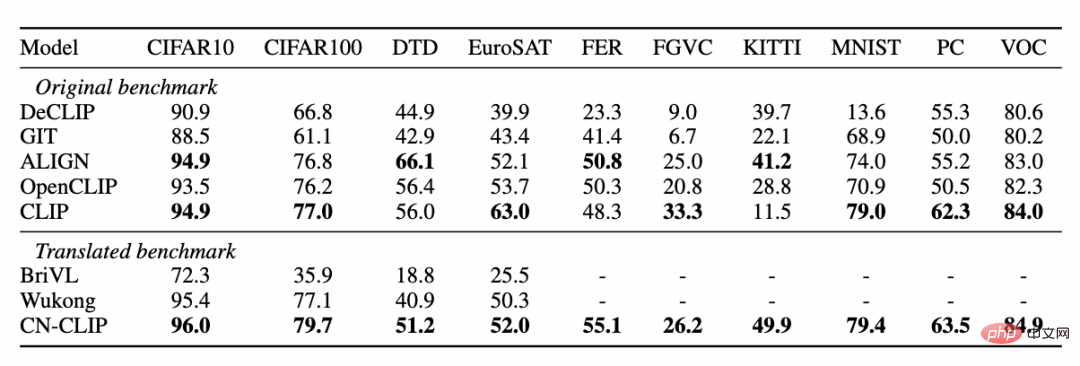
2 つのデータ セット: MUGE 中国の電子商取引画像とテキスト検索、Flickr30K-CN 翻訳バージョンの一般画像、およびテキストの取得 事前トレーニングを続行しながら、ゼロショットのエフェクト変化の傾向を観察します この戦略を使用して、研究者は、最小の ResNet-50、ViT-Base、Large から ViT-Huge まで、複数のスケールのモデルをトレーニングしました。それらはすべてオープンになり、ユーザーはオンデマンドで完全にアクセスできるようになりました。シナリオに最適なモデル: 複数の実験データは、 Chinese-CLIP が次の用途で使用できることを示しています。中国のクロスモーダル検索が最高のパフォーマンスを達成 中国ネイティブの電子商取引画像検索データセット MUGE では、複数の規模の中国語 CLIP がこの規模で最高のパフォーマンスを達成しました。英語ネイティブの Flickr30K-CN などのデータセットでは、ゼロサンプルや微調整設定に関係なく、中国の CLIP は Wukong、Taiyi、R2D2 などの国内ベースライン モデルを大幅に超える可能性があります。これは主に、 Chinese-CLIP の大規模な中国語事前トレーニング画像およびテキスト コーパスによるものであり、 Chinese-CLIP は、トレーニング コストを最小限に抑え、画像側全体をフリーズするために、一部の既存の国内画像およびテキスト表現モデルとは異なります。は、中国分野への適応を高めるために 2 つの段階的なトレーニング戦略を使用します: MUGE 中国の電子商取引の画像とテキストの検索データ実験結果の設定 ##Flickr30K-CN 中国語画像およびテキスト検索データセットの実験結果
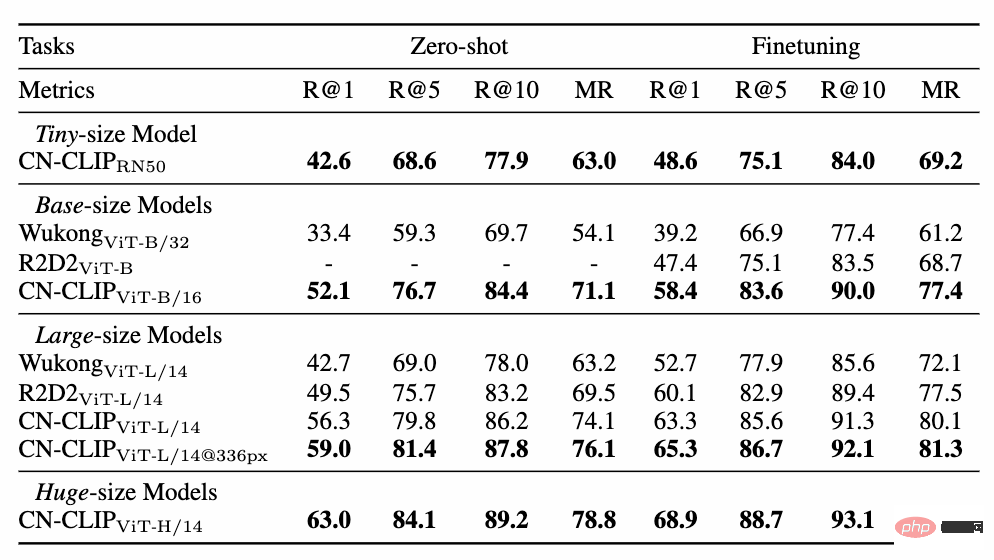
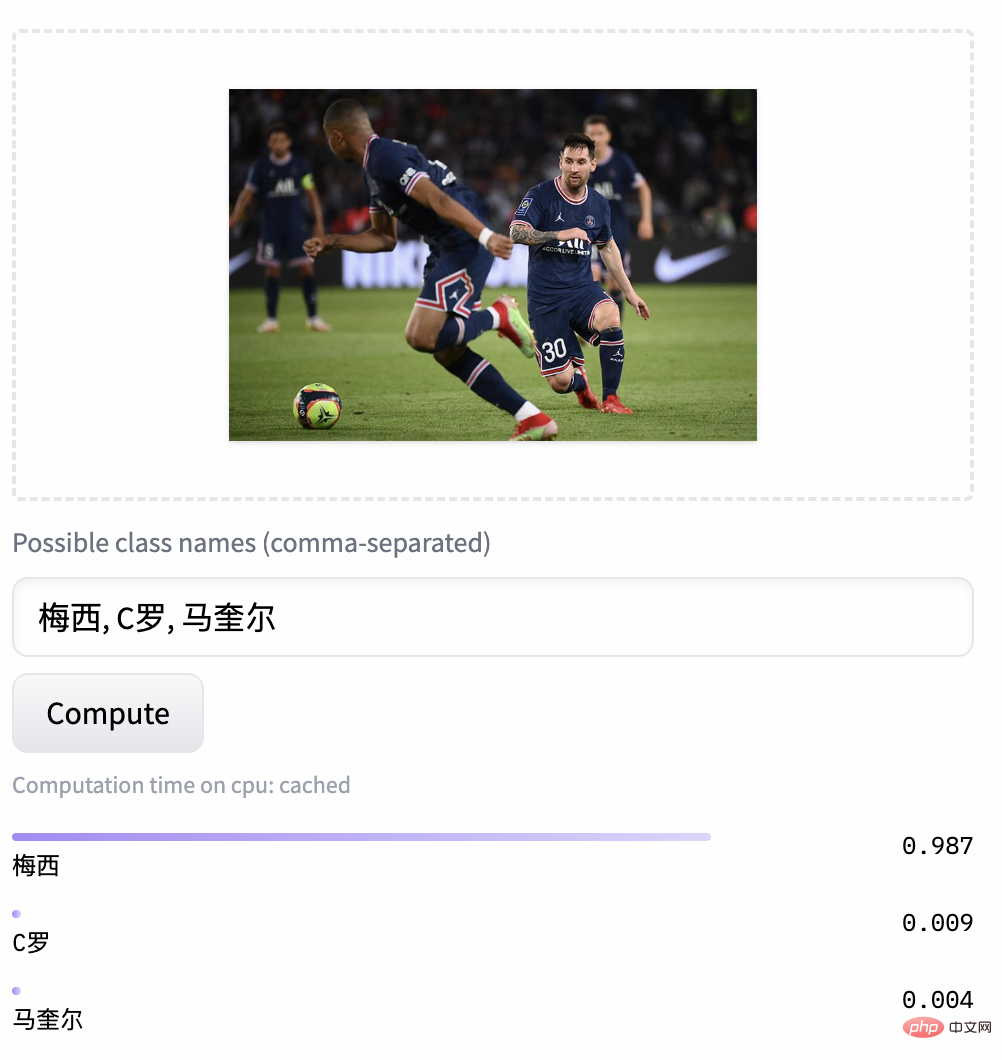
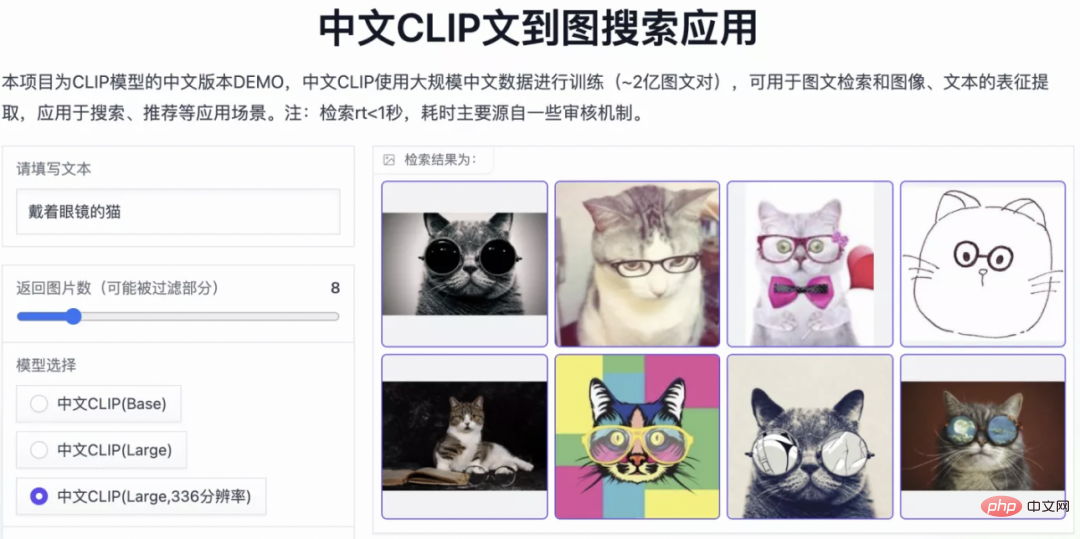
ゼロサンプル分類実験結果 # ###4。簡単な使い方 Chinese-CLIP を使用するにはどうすればよいですか?非常に簡単です。記事の先頭にあるリンクをクリックして Moda コミュニティにアクセスするか、オープン ソース コードを使用してください。画像とテキストの特徴抽出と類似度の計算をわずか数行で完了できます。すぐに使用して体験できるように、Moda コミュニティでは環境が設定されたノートブックが提供されており、右上隅をクリックして使用できます。 Chinese-CLIP は、ユーザーが独自のデータを使用して微調整することもサポートしており、誰もが実際に体験できる画像とテキストの検索のデモも提供します中国語 - さまざまなスケールの CLIP モデルの効果: 5. 結論 今回、Damoda コミュニティは中国語を開始しました。 CLIP プロジェクトは、中国のマルチモーダル研究および業界ユーザーの大多数に、優れた事前トレーニング済みの画像とテキストの理解モデルを提供し、誰もが画像とテキストの特徴と類似性の計算、画像とテキストの検索、およびゼロ-しきい値なしでサンプルを分類し、それを使用してみることができます。画像生成など、より複雑なマルチモーダル アプリケーションの構築に適しています。中国のマルチモーダル分野で自分の才能を発揮したい友人は、ぜひお見逃しなく!これは Moda コミュニティのアプリケーションの 1 つにすぎませんが、ModelScope を使用すると、AI 分野の多くの基本モデルがアプリケーション ベースの役割を果たすことができ、より革新的なモデル、アプリケーション、さらには製品の誕生をサポートできます。 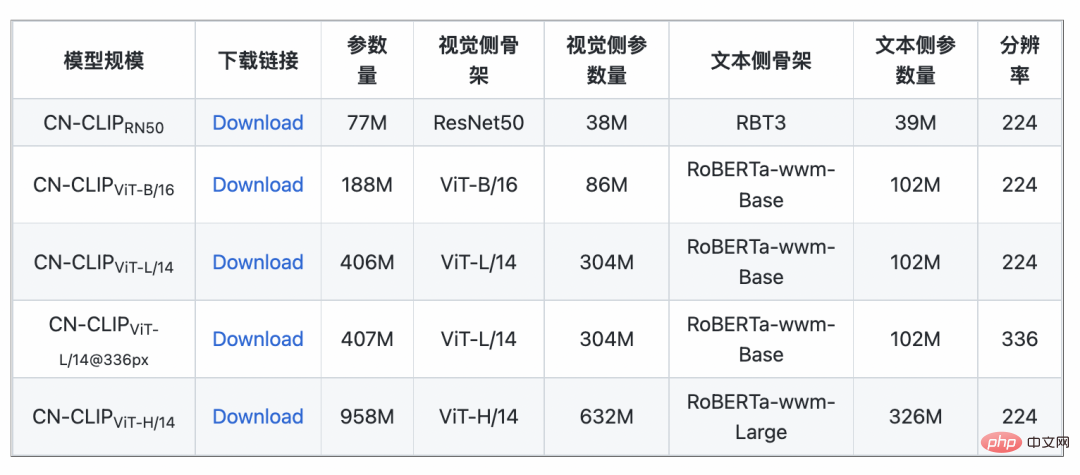
3. 実験

以上がCLIPは現実的ではありませんか?中国語をよりよく理解できるモデルが必要ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



