


ChatGPT およびその他の生成 AI (GAI) テクノロジーは、人工知能生成コンテンツ (AIGC) のカテゴリに分類されます。AIGC には、AI モデルによる画像、音楽、自然言語などのデジタル コンテンツの作成が含まれます。 AIGC の目標は、コンテンツ作成プロセスをより効率的かつアクセスしやすくし、高品質のコンテンツをより迅速に作成できるようにすることです。 AIGCは、人間の指示から意図情報を抽出・理解し、その知識や意図情報に基づいてコンテンツを生成することで実現されます。
近年、AIGC では大規模モデルの重要性がますます高まっています。これは、より適切な意図抽出が可能となり、生成結果が向上するためです。データとモデルのサイズが大きくなるにつれて、モデルが学習できる分布はより包括的で現実に近づき、その結果、より現実的で高品質なコンテンツが得られます。
この記事では、シングルモーダル インタラクションからマルチモーダル インタラクションまで、AIGC の歴史、基本コンポーネント、最近の進歩について包括的にレビューします。 単一モーダルの観点から、テキストと画像の生成タスクと関連モデルが紹介されます。マルチモーダルの観点から、上記のモダリティ間のクロスアプリケーションが紹介されます。最後に、AIGC の未解決の問題と将来の課題について説明します。

紙のアドレス: https://arxiv.org/abs/2303.04226
はじめに近年、人工知能生成コンテンツ (AIGC) がコンピューター サイエンス コミュニティの外で広く注目を集めており、社会全体が大手テクノロジー企業に注目し始めています。 3 ] ChatGPT[4] や DALL-E2[5] など、さまざまなコンテンツ生成製品を構築しました。 AIGC とは、人間の作成者によって作成されたコンテンツではなく、高度な生成 AI (GAI) テクノロジーを使用して生成されたコンテンツを指します。AIGC は、短時間で大量のコンテンツを自動的に作成できます。たとえば、ChatGPT は、人間の言語入力を効果的に理解し、有意義な方法で応答できる会話型人工知能システムを構築するために OpenAI によって開発された言語モデルです。さらに、DALL-E-2 も OpenAI によって開発されたもう 1 つの最先端の GAI モデルであり、図 1 に示すように、テキストの説明から独自の高品質画像を数分で作成できます。リアルなスタイルの乗馬」。 AIGC の傑出した成果により、多くの人が、これが人工知能の新時代となり、全世界に大きな影響を与えると信じています。
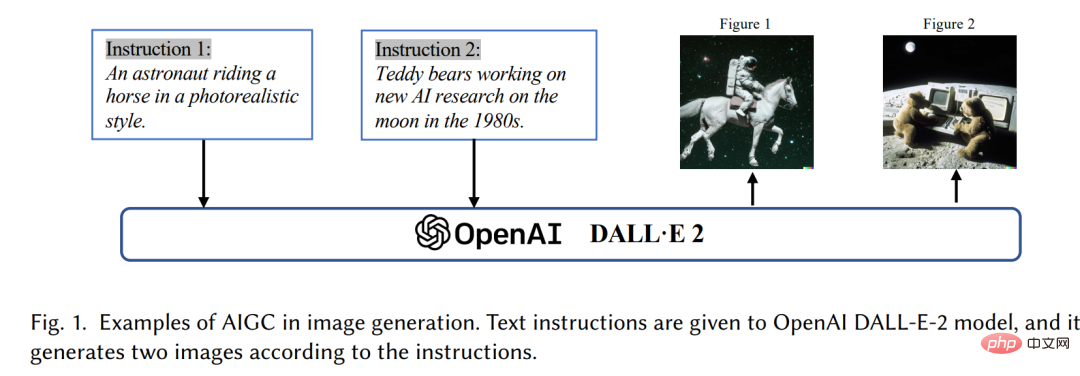
技術的に言えば、AIGC は、タスクを完了するようにモデルを教え、導くのに役立つ人間による与えられた指示を指します。 、GAI アルゴリズムを使用して、指示を満たすコンテンツを生成します。 生成プロセスには通常、人間の指示からインテント情報を抽出するステップと、抽出されたインテントに基づいてコンテンツを生成するステップの 2 つのステップが含まれます。ただし、以前の研究 [6,7] で示されているように、上記 2 つのステップを含む GAI モデルのパラダイムは完全に新しいわけではありません。以前の研究と比較して、最近の AIGC の主な進歩は、より大きなデータ セットでより複雑な生成モデルをトレーニングし、より大きなベース モデル アーキテクチャを使用し、広範囲のコンピューティング リソースにアクセスできるようになった点です。たとえば、GPT-3 の主要なフレームワークは GPT-2 と同じですが、事前トレーニング データ サイズが WebText [8] (38GB) から CommonCrawl [9] (フィルタリング後 570GB) に増加し、ベース モデルのサイズが増加します。 1.5Bから175Bに増加します。したがって、GPT-3 は、人間の意図の抽出などのタスクに関して GPT-2 よりも優れた汎化能力を備えています。
データ量とコンピューティング能力の増加によるメリットに加えて、研究者は新しいテクノロジーを GAI アルゴリズムと統合する方法も模索しています。たとえば、ChatGPT は、ヒューマン フィードバックからの強化学習 (RLHF) [10-12] を利用して、特定の指示に対する最適な応答を決定し、それによってモデルの信頼性と精度が時間の経過とともに向上します。このアプローチにより、ChatGPT は長い会話における人間の好みをよりよく理解できるようになります。同時に、コンピュータビジョンの分野では、Stability によって安定拡散が提案されました [13]。 AIは2022年に画像生成においても大きな成功を収めています。これまでの方法とは異なり、生成拡散モデルは探索と活用の間のトレードオフを制御することで高解像度の画像を生成するのに役立ち、それによって生成された画像の多様性とそれらのトレーニング データとの類似性を調和して組み合わせることができます。
これらの進歩を組み合わせることで、このモデルは AIGC タスクにおいて大幅な進歩を遂げ、芸術 [14]、広告 [15]、教育 [16] などを含むさまざまな業界に適用されています。近い将来、AIGC は機械学習における重要な研究分野であり続けるでしょう。したがって、過去の研究を広範に調査し、この分野で未解決の疑問を特定することが重要です。 AIGC 分野のコア技術とアプリケーションをレビューします。
これは AIGC の最初の包括的なレビューであり、技術面と応用面の両方から GAI を要約しています。これまでの研究では、自然言語生成 [17]、画像生成 [18]、マルチモーダル機械学習での生成 [7、19] など、さまざまな観点から GAI に焦点を当ててきました。 ただし、以前の研究では AIGC の特定の部分のみに焦点を当てていました。この記事では、まず AIGC で一般的に使用される基本的なテクニックを確認します。図 2 に示すように、シングルピーク生成とマルチピーク生成を含む高度な GAI アルゴリズムの包括的な概要がさらに提供されます。さらに、AIGC のアプリケーションと潜在的な課題についても説明します。最後に、この分野における既存の問題点と今後の研究の方向性を指摘した。 要約すると、この論文の主な貢献は次のとおりです:
調査の残りの部分は次のように構成されています。セクション 2 では主に、視覚モダリティと言語モダリティの 2 つの側面から AIGC の歴史を概観します。セクション 3 では、GAI モデルのトレーニングで現在広く使用されている基本コンポーネントを紹介します。セクション 4 では、GAI モデルの最近の進歩を要約します。セクション 4.1 では単一モーダル生成の観点から進歩をレビューし、セクション 4.2 ではマルチモーダル生成の観点から進歩をレビューします。マルチモーダル生成では、ビジュアル言語モデル、テキストオーディオモデル、テキストグラフモデル、およびテキストコードモデルが導入されます。セクション 5 と 6 では、AIGC における GAI モデルの応用と、この分野に関連するいくつかの重要な研究について紹介します。セクション 7 と 8 では、AIGC テクノロジーのリスク、既存の問題、将来の開発の方向性を明らかにします。最後に、9 で研究をまとめます。
生成モデルには人工知能の分野で長い歴史があり、その起源は 1950 年代の隠れマルコフ モデル (HMM) にまで遡ります。 ) )[20]、混合ガウス モデル (GMM) の開発[21]。これらのモデルは、音声や時系列などの連続データを生成します。ただし、生成モデルのパフォーマンスが大幅に向上したのは、ディープ ラーニングの出現によって初めて見られました。
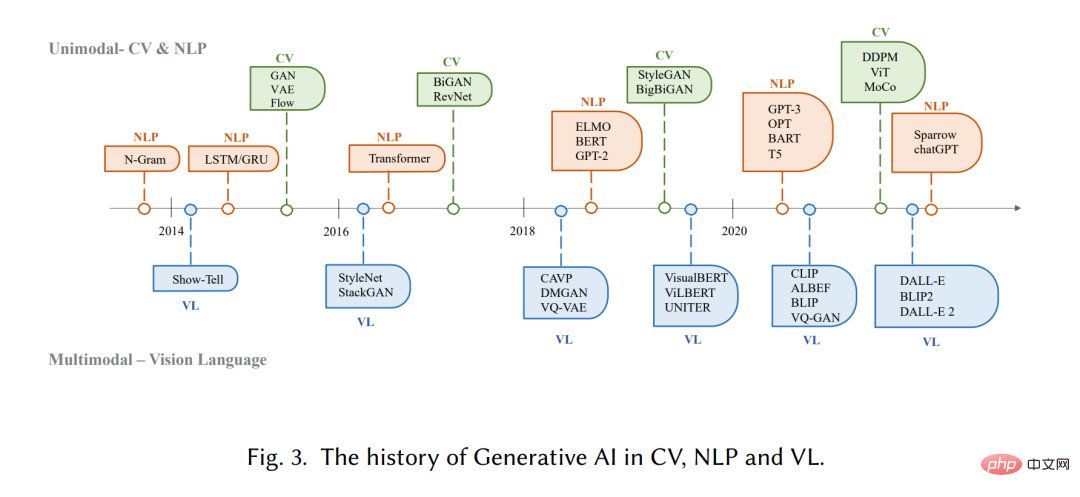
初期の深層生成モデルでは、通常、異なるドメインはあまり重複しませんでした。自然言語処理 (NLP) では、文章を生成する従来の方法は、N グラム言語モデリング [22] を使用して単語の分布を学習し、最適なシーケンスを検索することです。ただし、この方法は長い文章には効果的に適応できません。この問題を解決するために、リカレント ニューラル ネットワーク (RNN) [23] が後に言語モデリング タスクに導入され、比較的長い依存関係をモデル化できるようになりました。その後、長短期記憶 (LSTM) [24] およびゲート機構を利用してトレーニング中に記憶を制御するゲート反復ユニット (GRU) [25] が開発されました。これらのメソッドは、サンプル [26] で最大 200 個のトークンを処理できます。これは、N グラム言語モデルと比較して大幅な改善です。
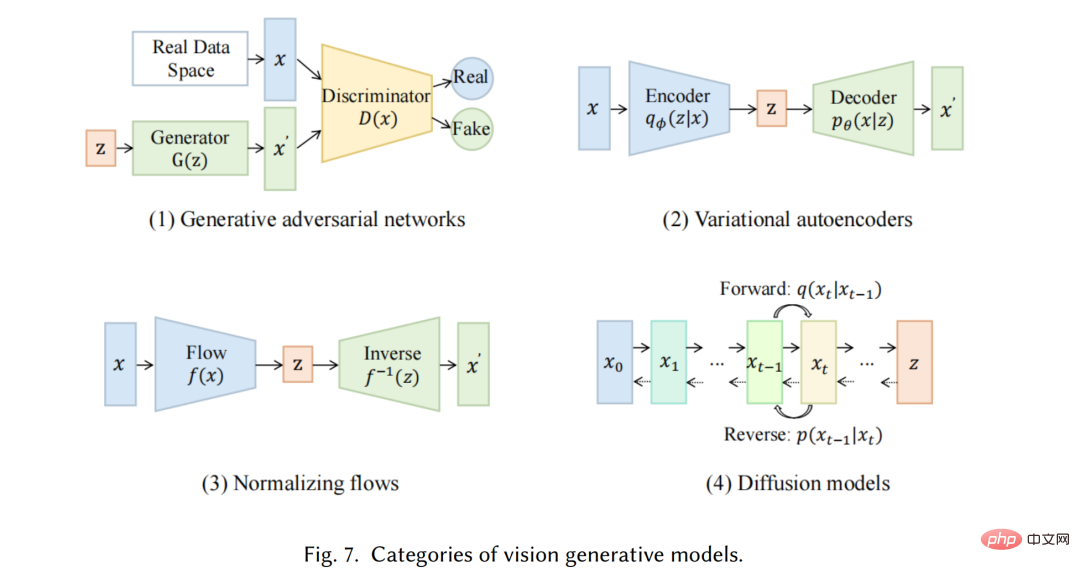
一方、コンピューター ビジョン (CV) の分野では、深層学習ベースの手法が登場する前は、従来の画像生成アルゴリズムではテクスチャ合成 [27] やテクスチャ マッピングなどの手法が使用されていました。 [28] 。これらのアルゴリズムは手作業で設計された機能に基づいており、複雑で多様な画像を生成する能力には限界があります。 2014 年に、敵対的生成ネットワーク (GAN) [29] が最初に提案され、さまざまなアプリケーションで目覚ましい結果を達成しました。これは、この分野における重要なマイルストーンです。変分オートエンコーダ (VAE) [30] や拡散生成モデル [31] などの他の方法も、画像生成プロセスをよりきめ細かく制御し、高品質の画像を生成する機能を目的として開発されています #
さまざまな分野での生成モデルの開発はさまざまな道をたどりますが、最終的にはトランスフォーマー アーキテクチャという横断的な問題が生じます [32]。 Vaswani らは 2017 年に NLP タスクを導入し、その後 Transformer は CV に適用され、その後、さまざまな分野の多くの生成モデルの主要なバックボーンになりました [9、33、34]。 NLP の分野では、BERT や GPT などの多くのよく知られた大規模言語モデルが、主要な構成要素としてトランスフォーマー アーキテクチャを採用しています。これには、LSTM や GRU などの以前の構成要素に比べて利点があります。 CV では、Vision Transformer (ViT) [35] と Swin Transformer [36] が、その後、画像ベースのダウンストリームに適用できるように、Transformer アーキテクチャとビジョン コンポーネントを組み合わせることにより、この概念をさらに発展させました。トランスフォーマーによって個々のモダリティにもたらされる改善に加え、このクロスオーバーにより、異なるドメインのモデルを融合してマルチモーダル タスクを完了することも可能になります。マルチモーダル モデルの例は CLIP [37] です。 CLIP は、トランスフォーマー アーキテクチャとビジョン コンポーネントを組み合わせた共同ビジョン言語モデルであり、大量のテキストおよび画像データでトレーニングできるようになります。事前トレーニング中に視覚的知識と言語的知識を組み合わせるため、マルチモーダルキュー生成の画像エンコーダーとしても使用できます。全体として、トランスベースのモデルの出現は人工知能の製造に革命をもたらし、大規模なトレーニングの可能性をもたらしました。
近年、研究者はこれらのモデルに基づいた新しいテクノロジーも導入し始めています。たとえば、NLP では、微調整よりも少数ショット ヒント [38] を好むことがあります。これは、モデルがタスクの要件をよりよく理解できるように、データセットから選択されたいくつかの例をヒントに含めることを指します。視覚言語では、研究者は多くの場合、モダリティ固有のモデルを自己教師ありの対比学習目標と組み合わせて、より堅牢な表現を提供します。今後、AIGCの重要性が高まるにつれ、より多くの技術が導入され、この分野は活力に満ちたものとなるでしょう。
最先端のシングルモーダルを導入します生成モデル。これらのモデルは、テキストや画像などの特定の生データ モダリティを入力として受け入れ、入力と同じモダリティで予測を生成するように設計されています。 GPT3 [9]、BART [34]、T5 [56] などの生成言語モデルや、GAN [29]、VAE [30] などの生成視覚モデルを含む、これらのモデルで使用される最も有望な方法と技術のいくつかについて説明します。 ]および正規化された流れ[57]。
マルチモーダル生成は、今日の AIGC の重要な部分です。マルチモーダル生成の目標は、データのマルチモーダル接続と相互作用を学習することで、元のモダリティのモデルを生成する方法を学習することです [7]。このようなモダリティ間の接続や相互作用は非常に複雑になる場合があるため、単一モーダル表現空間と比較してマルチモーダル表現空間の学習が困難になります。しかし、前述した強力なパターン固有のインフラストラクチャの出現により、この課題に対処するための方法がますます提案されています。このセクションでは、ビジュアル言語生成、テキストオーディオ生成、テキストグラフィックス生成、およびテキストコード生成における最先端のマルチモーダルモデルを紹介します。ほとんどのマルチモーダル生成モデルは常に実際のアプリケーションとの関連性が高いため、このセクションでは主に下流タスクの観点からモデルを紹介します。 ########################応用######################### ##効率
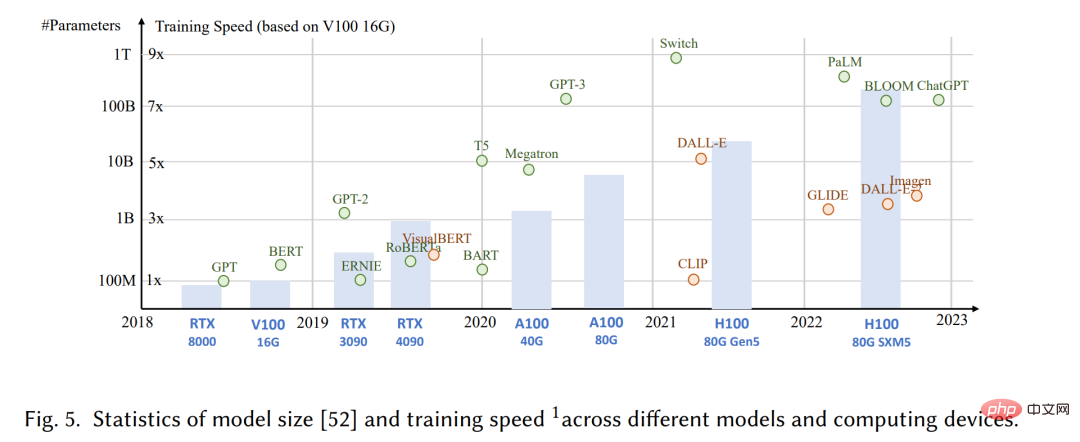
# 過去 10 年間、ニューラル ネットワークを使用した深層生成人工知能モデルが機械学習の分野を支配しており、その台頭は 2012 年の ImageNet コンペティション [210 ] によるものとされています。より深く、より複雑なモデルを作成する競争が生じています。この傾向は自然言語理解の分野にも現れており、BERT や GPT-3 などのモデルが多数のパラメーターを開発しています。ただし、モデルのフットプリントと複雑さの増加、およびトレーニングと展開に必要なコストとリソースが、現実世界での実際的な展開に課題をもたらしています。中心的な課題は効率であり、これは次のように分類できます: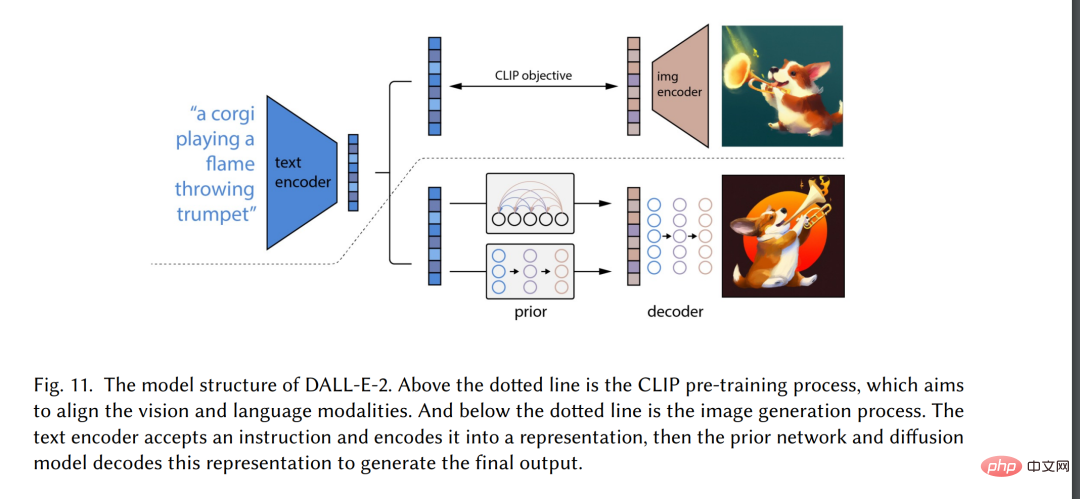
以上が「GAN から ChatGPT へ: リーハイ大学が AI 生成コンテンツの開発について詳しく説明」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



