



この章では、主に Python にはどのようなプログラミング モードがあるのかを理解し、Python の基本的な構文を習得し、理解できるようにするために、「Python の構文仕様とデータ型」に関する内容を更新します。コマンドラインパラメータの出力方法と基本的な応用 Python のデータ型を理解すると、さらに関連した操作を実行できるようになります。
①Python 対話型コマンド プログラミング。
②Pythonスクリプトプログラミング。
③中国語のエンコード処理。
対話型コマンド プログラミング モードは、典型的な 1 行ずつの読み取り実行モードです。
このプログラミング モードは、プログラムが 1 行以下の場合の一般的なアプリケーションです。
次の図では、プログラミングに PythonIDLE エディターを使用しています。このエディターのプログラミング モードは、典型的な対話型コマンド エンコーディング シンボルです。
#>>>> は、対話型コマンドを入力するためのプロンプトです。入力完了後に Enter キーを押すたびに、Python パーサーによってコマンドが実行されます。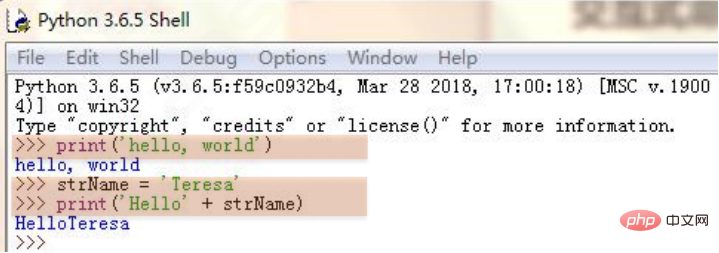
 #3. 文字プログラミング
#3. 文字プログラミング
コンピュータは数値のみを処理できるため、テキストを処理する場合は、処理する前にまずテキストを数値に変換する必要があります。
補足: 文字エンコーディングの開発の歴史
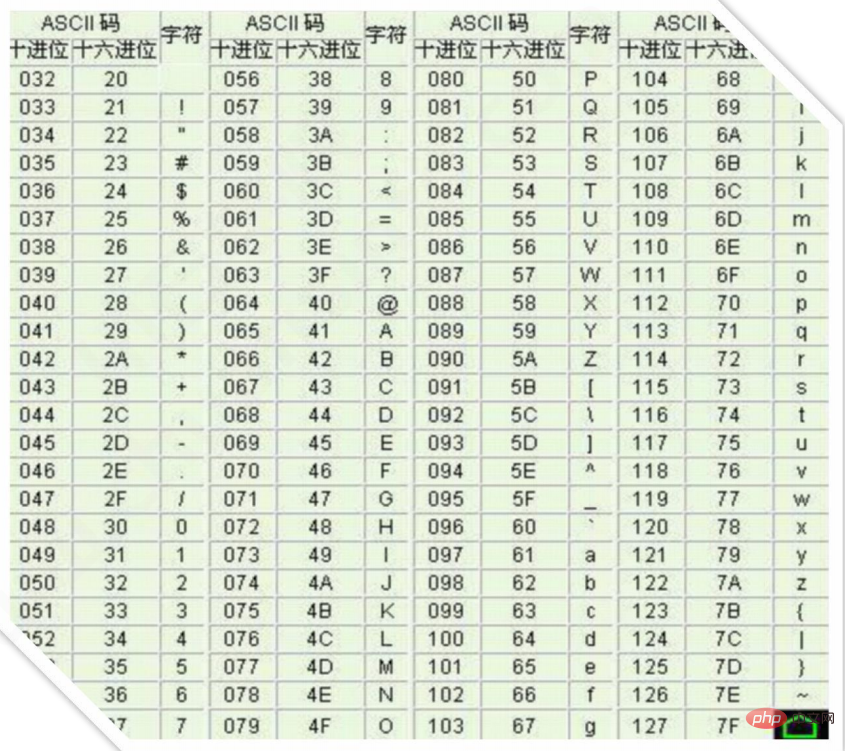
コンピューターはアメリカ人によって発明されて以来、最初にコンピューターにエンコードされたのは、英語の大文字と小文字、数字、および一部の記号の 127 文字だけでした。このエンコード テーブルは ASCII エンコードと呼ばれます。文字 文字 A のコードは 65、小文字 z のコードは 122 です。
 拡張機能: unicode 文字セット
拡張機能: unicode 文字セット
ソリューションの誕生:
Unicode エンコードを「可変長エンコード」に変換する UTF-8 エンコードが再び登場しました。#UTF-8 エンコーディングは、Unicode 文字をさまざまな数値サイズに応じて 1 ~ 6 バイトにエンコードします。一般的に使用される英語の文字は 1 バイトにエンコードされ、中国語の文字は通常 3 バイトにエンコードされます。非常にまれな文字のみがエンコードされます。 4 ~ 6 バイトにエンコードされます。
# 送信するテキストに英語の文字が多数含まれている場合は、UTF-8 エンコードを使用するとスペースを節約できます。 # UTF-8 エンコードには追加の利点があります。つまり、ASCII エンコードは実際には UTF-8 エンコードの一部と見なすことができるため、ASCII エンコードのみをサポートする多数の歴史的なレガシー ソフトウェアをエンコードできます。 UTF-8 でコーディングしながら作業を続けます。特記事項:
Unicode エンコードは、コンピューターのメモリ内で均一に使用されます。python3 文字エンコーディング
Python3 バージョンでは、文字列は Unicode でエンコードされます。つまり、Python 文字列は複数の言語をサポートします。 単一文字のエンコーディングの場合、Python は単一文字の 10 進整数表現を取得する ord() 関数と、エンコーディングを対応する文字に変換する chr() 関数を提供します。>>> ord(‘A’) 65 >>> ord(‘中’) 20013 >>> chr(66) ‘B’ >>> chr(25991) ‘文’
Python ソース コードもテキスト ファイルであるため、ソース コードに中国語が含まれている場合は、ソース コードを保存するときに UTF-8 エンコードを指定する必要があります。 Python インタープリターがソース コードを読み取るとき、UTF-8 エンコーディングで読み取れるようにするために、通常はファイルの先頭にこの行を書き込みます。
#-*- coding:utf-8 *-
コメントは、Python インタプリタに UTF-8 エンコーディングに従ってソース コードを読み取るように指示するものです。そうしないと、ソース コードに記述した中国語出力が文字化けする可能性があります。
以上が自動テスト: Python のいくつかの一般的なプログラミング パターンの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



