


ゼロショット学習 (Zero-Shot Learning) は、学習プロセス中に出現しなかったカテゴリの分類に焦点を当てており、意味記述に基づくゼロショット学習は、各カテゴリに対して事前に定義された高次の意味情報を通じて実装されます。カテゴリ: 見えるクラスから見えないクラスへの知識の伝達。従来のゼロショット学習はテスト段階で未認識のクラスを識別するだけでよいのに対し、一般化ゼロショット学習(GZSL)は可視クラスと未可視クラスの両方を識別する必要があり、その評価指標は可視クラスの平均精度と未可視クラスの平均精度です。クラス精度の調和平均。
一般的なゼロショット学習戦略は、目に見えるクラス サンプルとセマンティクスを使用して、セマンティック空間からビジュアル サンプル空間への条件付き生成モデルをトレーニングし、次に、目に見えないクラスを生成することです。目に見えないクラス セマンティクスの疑似サンプルを使用し、最後に、目に見えるクラス サンプルと目に見えないクラスの疑似サンプルを使用して分類ネットワークをトレーニングします。ただし、2 つのモダリティ (意味論的モダリティと視覚的モダリティ) 間の適切なマッピング関係を学習するには、通常、大量のサンプル (CLIP を参照) が必要であり、これは従来のゼロショット学習環境では達成できません。したがって、目に見えないクラスのセマンティクスを使用して生成された視覚的なサンプル分布は、通常、実際のサンプル分布から逸脱します。これは、次の 2 つの点を意味します。 1. この方法で得られる目に見えないクラスの精度には限界があります。 2. 目に見えないクラスのクラスごとに生成される疑似サンプルの平均数が、可視クラスの各クラスの平均サンプル数と等しい場合、目に見えないクラスの精度と可視クラスの精度の間には大きな差が生じます。以下の表 1 に示します。

#カテゴリの中心点へのセマンティクスのマッピングのみを学習した場合でも、次のことができることがわかりました。目に見えないクラス セマンティクスもマップします。 単一のサンプル ポイントを複数回コピーしてから分類器トレーニングに参加することでも、生成モデルを使用するのに近い効果を達成できます。これは、生成モデルによって生成された目に見えない疑似サンプルの特徴が分類器に対して比較的同質であることを意味します。
従来のメソッドは通常、多数の未認識クラスの疑似サンプルを生成することで GZSL 評価メトリクスに対応します (ただし、多数のサンプルは未確認クラスには役に立ちません)階級間差別))。ただし、この再サンプリング戦略は、実際のサンプルのクラス特性から逸脱する擬似的に目に見えない一部の特徴に対して分類器が過剰適合する原因となることがロングテール学習の分野で証明されています。この状況は、目に見えるクラスと見えないクラスの実際のサンプルを識別するのに役立ちません。それでは、このリサンプリング戦略を放棄し、代わりに、目に見えないクラスの疑似サンプルを生成する際のオフセットと均一性 (または、見えているクラスと見えないクラス間のクラスの不均衡) を帰納的バイアスとして使用することはできるでしょうか? 分類器の学習についてはどうでしょうか?
これに基づいて、コードを 1 行変更するだけで生成的ゼロショット学習を改善できるプラグアンドプレイ分類器モジュールを提案しました。 . メソッドの効果。 SOTA レベルを達成するために、未認識のクラスごとに 10 個の擬似サンプルのみが生成されます。 他のゼロサンプル生成手法と比較して、新しい手法は計算の複雑さの面で大きな利点があります。 研究メンバーは南京科技大学とオックスフォード大学から構成されています。

方法
1. パラメータ化された事前計算の導入ここで、 はグローバル精度、
はグローバル精度、 は分類子の出力、
は分類子の出力、 はサンプル分布を表し、
はサンプル分布を表し、 はサンプル X の対応するラベルです。 GZSL の評価指標は、
はサンプル X の対応するラベルです。 GZSL の評価指標は、
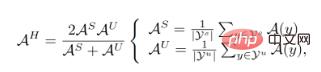

 # および
# および  # です。それぞれ可視クラスと非可視クラスのコレクションを表します。トレーニングの目的とテストの目的の間に一貫性がないということは、以前の分類子のトレーニング戦略では、目に見えるクラスと目に見えないクラスの違いが考慮されていなかったことを意味します。当然のことながら、
# です。それぞれ可視クラスと非可視クラスのコレクションを表します。トレーニングの目的とテストの目的の間に一貫性がないということは、以前の分類子のトレーニング戦略では、目に見えるクラスと目に見えないクラスの違いが考慮されていなかったことを意味します。当然のことながら、 を導き出すことで、トレーニング目標とテスト目標の間で一貫した結果を達成しようとします。導出後、その下限を取得しました。
を導き出すことで、トレーニング目標とテスト目標の間で一貫した結果を達成しようとします。導出後、その下限を取得しました。

ここで、 は、可視クラス (以前の目に見えないクラス) を表します。データとは何の関係もなく、実験ではハイパーパラメータとして調整されます。
は、可視クラス (以前の目に見えないクラス) を表します。データとは何の関係もなく、実験ではハイパーパラメータとして調整されます。 は、可視クラスまたは不可視クラスの内部事前確率を表し、可視クラスの頻度に置き換えられます。実装プロセス中のサンプルまたは一様分布。
は、可視クラスまたは不可視クラスの内部事前確率を表し、可視クラスの頻度に置き換えられます。実装プロセス中のサンプルまたは一様分布。  の下限を最大化することで、最終的な最適化目標が得られます。
の下限を最大化することで、最終的な最適化目標が得られます。

したがって、分類はモデリングです。以前の目標と比較して次の変更が加えられています。

、分類子の損失は次のように得られます: 
これは、ロングテール学習におけるロジック調整 (ロジット調整) に似ているため、ゼロサンプル ロジック調整 (ZLA) と呼ばれます。これまでのところ、私たちはパラメータ化された事前分布の導入を実装して、見えているクラスと見えないクラスの間のカテゴリーの不均衡を帰納的バイアスとして分類器トレーニングに埋め込み、コード実装の元のロジットに追加のバイアス項を追加するだけで、上記のことを達成できます。効果。

これまでのところ、ゼロサンプル移行の中核はセマンティック事前です。) は再生のみです。トレーニング ジェネレーターと疑似サンプル生成段階での役割 未確認クラスの識別は、生成された未確認クラス疑似サンプルの品質に完全に依存します。明らかに、分類器のトレーニング段階で意味論的事前分布を導入できれば、目に見えないクラスを識別するのに役立ちます。ゼロショット学習の分野では、この機能を実現できる埋め込みベースのメソッドのクラスがあります。しかし、このタイプの方法は、生成モデルによって学習された知識、つまり意味論と視覚の間の接続 (意味論と視覚のリンク) に似ており、以前の生成フレームワークの直接導入につながりました (論文を参照) -CLSWGAN) に基づいています (分類子自体のゼロショット パフォーマンスが優れている場合を除き、埋め込まれた分類子は元の分類子よりも優れた結果を達成することはできません)。この論文で提案した ZLA 戦略を通じて、生成された未確認クラスの擬似サンプルが分類器トレーニングで果たす役割を変更できます。不可視クラス情報の最初の提供から、不可視クラスと可視クラスの間の決定境界の現在の調整まで、分類器トレーニング段階で意味論的事前分布を導入できます。具体的には、プロトタイプ学習手法を使用して、各カテゴリのセマンティクスを視覚的なプロトタイプ (つまり、分類器の重み) にマッピングし、調整された事後確率をサンプルと視覚的なプロトタイプ間のコサイン類似度としてモデル化します。つまり、

ここで、 は温度係数です。テスト段階では、サンプルはコサイン類似度が最も高いビジュアル プロトタイプのカテゴリに対応すると予測されます。
は温度係数です。テスト段階では、サンプルはコサイン類似度が最も高いビジュアル プロトタイプのカテゴリに対応すると予測されます。

提案された分類器と基本的な WGAN を組み合わせて、目に見えないクラスごとに 10 個のサンプルを生成します。その効果は以下に匹敵します。 SoTA。さらに、それをより高度な CE-GZSL メソッドに挿入し、他のパラメーター (生成されるサンプル数を含む) を変更せずに初期効果を向上させました。

#アブレーション実験では、世代ベースのプロトタイプ学習器と純粋なプロトタイプ学習器を比較しました。最後の ReLU 層が純粋なプロトタイプ学習器の成功にとって重要であることがわかりました。これは、負の数をゼロに設定すると、カテゴリ プロトタイプの未見のクラス特徴との類似性が高まるためです (未見のクラス特徴も ReLU によってアクティブ化されます)。ただし、一部の値をゼロに設定すると、プロトタイプの表現も制限され、さらなる認識パフォーマンスにはつながりません。擬似的に見えないクラス サンプルを使用して見えないクラス情報を補うことにより、RuLU を使用する場合に高いパフォーマンスを達成できるだけでなく、ReLU 層を使用せずにさらなるパフォーマンスの超越性を達成することもできます。

別のアブレーション研究では、プロトタイプ学習器と初期分類器を比較しました。結果は、未確認のクラス サンプルを大量に生成する場合、プロトタイプ学習器は初期分類子よりも利点がないことを示しています。この記事で提案する ZLA 技術を使用すると、プロトタイプ学習器がその優位性を示します。前述したように、これは、プロトタイプ学習器と生成モデルの両方が意味と視覚のつながりを学習しているため、意味情報を十分に活用することが難しいためです。 ZLA を使用すると、生成された未確認クラスのサンプルが、単に未確認クラスの情報を提供するのではなく、決定境界を調整できるようになり、それによってプロトタイプ学習器がアクティブになります。

以上が1 行のコードを使用してゼロショット学習法の効果を大幅に向上させる、南京理工大学とオックスフォードがプラグアンドプレイ分類器モジュールを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



