


7 月 22 日にアップロードされた arXiv 論文「JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes」は、オーストラリアのシドニー大学の Tao Dacheng 教授と北京 JD Research Institute の研究について報告しています。 。

奥行き推定、ビジュアル オドメトリ (VO)、および鳥瞰図 (BEV) シーン レイアウト推定は、自動運転車の動きの鍵である運転シーン認識のための 3 つの重要なタスクです。運転計画とナビゲーションの基礎。補完的ではありますが、通常は個別のタスクに焦点を当て、3 つすべてに同時に取り組むことはほとんどありません。
単純なアプローチは、これを逐次的または並列的に独立して実行することですが、3 つの欠点があります、すなわち、1) 深度および VO の結果は、固有のスケール曖昧さの問題の影響を受ける、2) BEV レイアウトは通常行われます。明示的なオーバーレイとアンダーレイの関係を無視して道路と車両を独立して推定する; 3) 深度マップはシーンのレイアウトを推測するための有用な幾何学的手がかりですが、BEV のレイアウトは実際には、深度関連の情報を使用せずに正面図の画像から直接予測されます。
本論文では、これらの問題を解決し、同時に単眼ビデオシーケンスからスケール知覚深度、VO、BEVレイアウトを推定するための共同知覚フレームワークJPerceiverを提案します。クロスビュー幾何変換 (CGT) を使用して、慎重に設計されたスケール損失に従って、絶対スケールを道路レイアウトから深度および VO に伝播します。同時に、クロスビューおよびクロスモーダル転送 (CCT) モジュールは、奥行きの手がかりを使用して、注意メカニズムを通じて道路と車両のレイアウトを推論するように設計されています。 JPerceiver は、エンドツーエンドのマルチタスク学習方法でトレーニングされています。この方法では、CGT スケール ロス モジュールと CCT モジュールがタスク間の知識伝達を促進し、各タスクの特徴学習を促進します。
コードとモデルはダウンロードできます
https://github.com/sunnyHelen/JPerceiver. 図に示すように、JPerceiver は深度、姿勢、道路レイアウトの 3 つのネットワークで構成されており、すべてエンコーダー/デコーダー アーキテクチャに基づいています。深度ネットワークは、現在のフレーム It の深度マップ Dt を予測することを目的としています。ここで、各深度値は 3D ポイントとカメラの間の距離を表します。ポーズ ネットワークの目的は、現在のフレーム It とその隣接フレーム It m の間のポーズ変換 Tt → t m を予測することです。道路レイアウト ネットワークの目的は、現在のフレームの BEV レイアウト Lt、つまりトップビュー デカルト平面における道路と車両の意味論的な占有を推定することです。 3 つのネットワークはトレーニング中に共同で最適化されます。
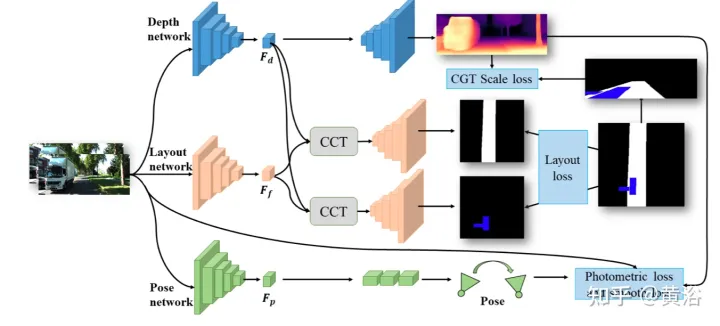 #深度と姿勢を予測する 2 つのネットワークは、自己監視型の方法で測光損失と滑らかさ損失を使用して共同で最適化されます。さらに、CGT スケール損失は、単眼の深さと VO 推定のスケール曖昧さの問題を解決するようにも設計されています。
#深度と姿勢を予測する 2 つのネットワークは、自己監視型の方法で測光損失と滑らかさ損失を使用して共同で最適化されます。さらに、CGT スケール損失は、単眼の深さと VO 推定のスケール曖昧さの問題を解決するようにも設計されています。
BEV レイアウトのスケール情報を使用して、スケールを意識した環境認識を実現するために、CGT のスケール損失が深度推定と VO に提案されます。 BEV レイアウトは BEV デカルト平面での意味占有を示すため、車両の前方の Z メートルと左右の (Z/2) メートルの範囲をカバーします。これは、図に示すように、自然距離フィールド z、つまり自車両に対する各ピクセルのメトリック距離 zij を提供します。
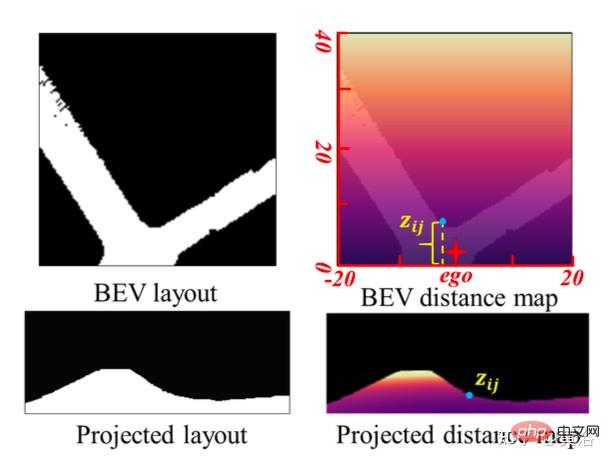 BEV 平面が地面であると仮定します。 , その原点は自車座標系の原点の直下にあり、カメラの外部パラメータに基づいて、BEV 平面をホモグラフィー変換によって前方カメラに投影できます。したがって、上の図に示すように、BEV 距離フィールド z を前方カメラに投影し、予測深さ d を調整するために使用することで、CGT スケール損失を導き出すことができます。
BEV 平面が地面であると仮定します。 , その原点は自車座標系の原点の直下にあり、カメラの外部パラメータに基づいて、BEV 平面をホモグラフィー変換によって前方カメラに投影できます。したがって、上の図に示すように、BEV 距離フィールド z を前方カメラに投影し、予測深さ d を調整するために使用することで、CGT スケール損失を導き出すことができます。
CCT-CV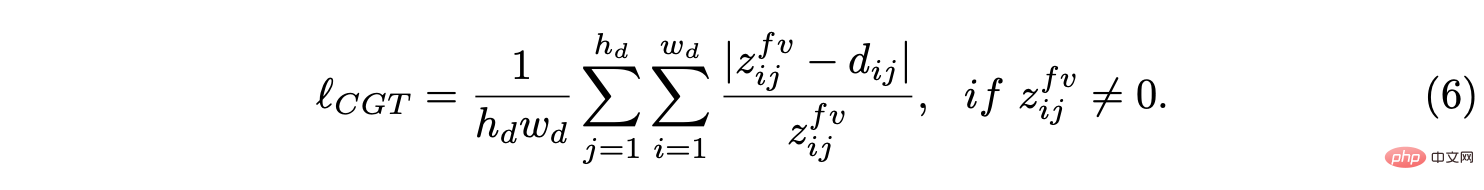 と
と
という 2 つの部分に分かれています。
CCT では、Ff と Fd は対応する知覚ブランチのエンコーダーによって抽出されますが、Fb はビュー投影 MLP によって取得されて Ff を BEV に変換し、サイクル損失によって同じ MLP が Ff' に再変換されるように制約されました。 。
CCT-CV では、クロスアテンション メカニズムを使用して、前方視界と BEV 特徴の間の幾何学的対応を発見し、前方視界情報の改良を導き、BEV 推論の準備をします。前方ビュー画像の特徴を最大限に活用するために、Fb と Ff がそれぞれクエリとキーとしてパッチ: Qbi と Kbi に投影されます。
前方ビュー機能の利用に加えて、CCT-CM は Fd からの 3D 幾何学的情報を強制するためにも導入されています。 Fd は前方ビュー画像から抽出されるため、Ff をブリッジとして使用してクロスモーダルギャップを減らし、Fd と Fb の間の対応関係を学習するのが合理的です。 Fd は Value の役割を果たし、BEV 情報に関連する貴重な 3 次元幾何学情報を取得し、道路レイアウト推定の精度をさらに向上させます。
異なるレイアウトを同時に予測するための共同学習フレームワークを探索するプロセスでは、異なるセマンティック カテゴリの特性と分布に大きな違いがあります。フィーチャについては、通常、運転シナリオの道路レイアウトを接続する必要がありますが、さまざまな車両ターゲットをセグメント化する必要があります。
分布に関しては、曲がり角のシーンよりも直線道路のシーンが多く観察されますが、これは実際のデータセットでは合理的です。この場合、単純なクロスエントロピー (CE) 損失または L1 損失では失敗するため、この違いと不均衡により、BEV レイアウトの学習、特に異なるカテゴリを共同で予測することが困難になります。分散ベースの CE 損失、地域ベースの IoU 損失、境界損失などのいくつかのセグメンテーション損失がハイブリッド損失に結合され、各カテゴリのレイアウトが予測されます。
実験結果は次のとおりです。
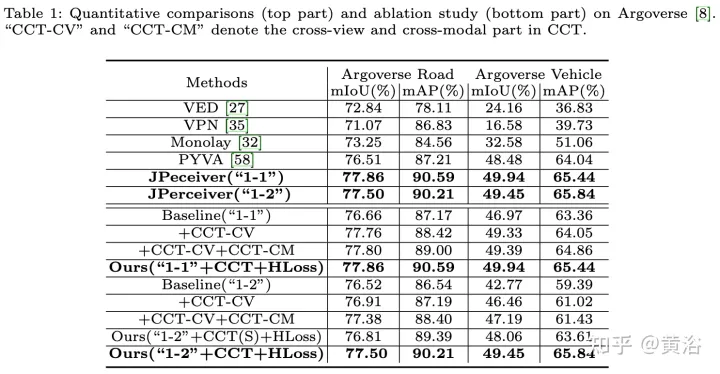
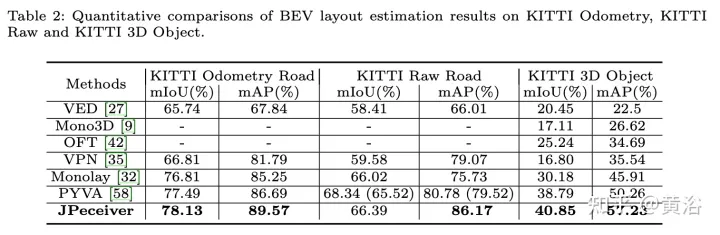
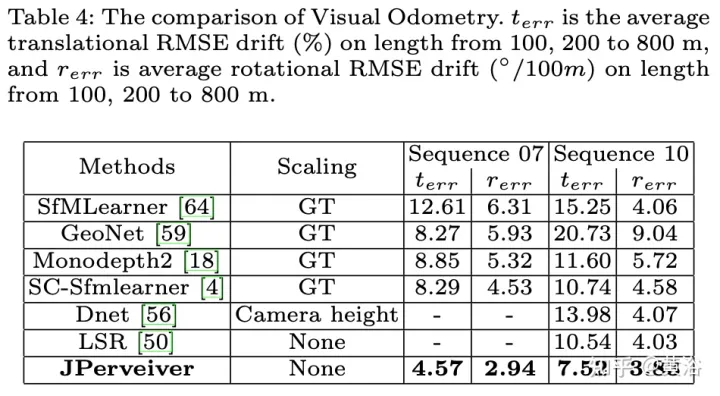
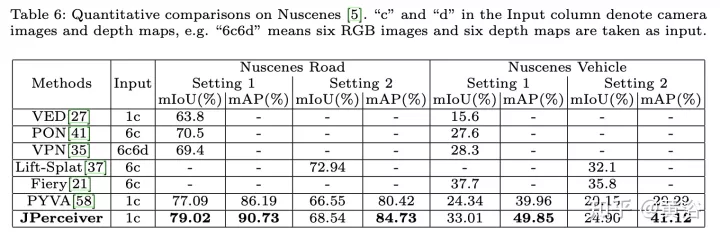
##
以上が共同運転シナリオにおける深度、姿勢、道路推定のための知覚ネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



