

Redis 分散ロックを本当に理解していますか?次の記事では、Redis の分散ロックについて詳しく説明し、ロックの実装方法、ロックの解放方法、分散ロックの欠陥などについて説明します。お役に立てば幸いです。

Redis といえば、データをキャッシュする機能が最初に思い浮かびます。 process 、高いパフォーマンス特性を備えており、分散ロックにもよく使用されます。 [関連する推奨事項: Redis ビデオ チュートリアル ]
ロックは、プログラム内で共有リソースに同時に 1 つのスレッドのみがアクセスできるようにする同期ツールとして機能することは誰もが知っています。 Java よく使用する同期ロックやロックなどのロックはよく知られていますが、Java のロックは 1 台のマシンでのみ有効であることが保証されており、分散クラスタ環境では何もできません。今度は、分散ロックを使用する必要があります。
分散ロックは、名前が示すとおり、分散プロジェクト開発で使用されるロックです。分散システム間の共有リソースへの同期アクセスを制御するために使用できます。一般的に、分散ロックが満たす必要がある特性は次のとおりです。いくつかのポイントが続きます:
1. 相互排他性: いつでも、同じデータに対して 1 つのアプリケーションだけが分散ロックを取得できます;
2. 高可用性: 分散型ロックシナリオ この状況では、少数のサーバーのダウンタイムは通常の使用には影響しません。この場合、分散ロックを提供するサービスをクラスターにデプロイする必要があります。
3. ロック タイムアウトの防止:クライアントが積極的にロックを解放するのではなく、クライアントがダウンしている場合やネットワークにアクセスできない場合にデッドロックを防ぐために、サーバーは一定時間が経過すると自動的にロックを解放します;
4. 排他性: ロックとロック解除は、同じサーバー、つまりロックによって実行されます ロックを解除できるのは所有者のみであり、追加したロックは他の人がロックを解除することはできません;
業界には、分散型の効果を実現できるツールが多数あります。ロックしますが、操作は次のとおりです: ロック、ロック解除、ロック タイムアウトの防止。
この記事は Redis 分散ロックについて話しているので、もちろん Redis のナレッジ ポイントを使用して拡張します。
最初に Redis のいくつかのコマンドを紹介します、
1.SETNX、使用方法は SETNX キーの値
SETNX は「SET if Not eXists」(存在しない場合は SET)の略で、設定に成功した場合は 1 を返し、そうでない場合は 0 を返します。
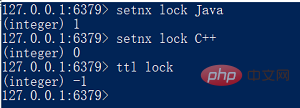
key を lock に変更すると、次のことがわかります。値を「Java」に設定した後、別の値に設定すると失敗します。非常に単純で排他ロックのように見えますが、key# という致命的な問題があります。 ## には有効期限がないため、まず、キーを手動で削除するか、ロックを取得した後に有効期限を設定しない限り、他のスレッドがロックを取得することはありません。 この場合、いつでもキーに有効期限を追加し、ロックを取得するときにスレッドに 2 段階の操作を直接実行させることができます。
`SETNX Key 1` `EXPIRE Key Seconds`
この解決策にも問題があります。ロックの取得と有効期限の設定の 2 つのステップに分かれているため、アトミックな操作ではありません。
ロックの取得は成功しても、時間の設定は失敗するという可能性があります。無駄ではないでしょうか。 ? しかし、心配しないでください。Redis 公式がすでにこれを検討しているため、次のコマンドが導入されました。
2, SETEX, 使用法
SETEX キー秒値 値
を key に関連付け、key の有効期間を 秒 (秒単位) に設定します。 key がすでに存在する場合、SETEX コマンドは古い値を上書きします。 このコマンドは、次の 2 つのコマンドに似ています。
`SET key value` `EXPIRE key seconds # 设置生存时间`
これら 2 つのステップはアトミックであり、同時に完了します。
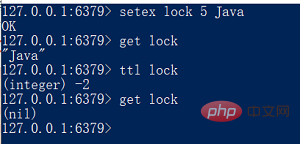 setex の使用法
setex の使用法
PSETEX キーのミリ秒値
これこのコマンドは SETEX コマンドに似ていますが、key
ただし、Redis バージョン 2.6.12 以降、SET コマンドはパラメーターを使用して、SETNX、SETEX、および PSETEX の 3 つのコマンドと同じ効果を実現できます。
`SET key value NX EX seconds`
`if redis.call("get",KEYS[1]) == ARGV[1]`
`then`
`return redis.call("del",KEYS[1])`
`else`
`return 0`
`end`KEYS[1]是当前key的名称,ARGV[1]可以是当前线程的ID(或者其他不固定的值,能识别所属线程即可),这样就可以防止持有过期锁的线程,或者其他线程误删现有锁的情况出现。
知道了原理后,我们就可以手写代码来实现Redis分布式锁的功能了,因为本文的目的主要是为了讲解原理,不是为了教大家怎么写分布式锁,所以我就用伪代码实现了。
首先是redis锁的工具类,包含了加锁和解锁的基础方法:
`public class RedisLockUtil {`
`private String LOCK_KEY = "redis_lock";`
`// key的持有时间,5ms`
`private long EXPIRE_TIME = 5;`
`// 等待超时时间,1s`
`private long TIME_OUT = 1000;`
`// redis命令参数,相当于nx和px的命令合集`
`private SetParams params = SetParams.setParams().nx().px(EXPIRE_TIME);`
`// redis连接池,连的是本地的redis客户端`
`JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);`
`/**`
`* 加锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean lock(String id) {`
`Long start = System.currentTimeMillis();`
`Jedis jedis = jedisPool.getResource();`
`try {`
`for (;;) {`
`// SET命令返回OK ,则证明获取锁成功`
`String lock = jedis.set(LOCK_KEY, id, params);`
`if ("OK".equals(lock)) {`
`return true;`
`}`
`// 否则循环等待,在TIME_OUT时间内仍未获取到锁,则获取失败`
`long l = System.currentTimeMillis() - start;`
`if (l >= TIME_OUT) {`
`return false;`
`}`
`try {`
`// 休眠一会,不然反复执行循环会一直失败`
`Thread.sleep(100);`
`} catch (InterruptedException e) {`
`e.printStackTrace();`
`}`
`}`
`} finally {`
`jedis.close();`
`}`
`}`
`/**`
`* 解锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean unlock(String id) {`
`Jedis jedis = jedisPool.getResource();`
`// 删除key的lua脚本`
`String script = "if redis.call('get',KEYS[1]) == ARGV[1] then" + " return redis.call('del',KEYS[1]) " + "else"`
`+ " return 0 " + "end";`
`try {`
`String result =`
`jedis.eval(script, Collections.singletonList(LOCK_KEY), Collections.singletonList(id)).toString();`
`return "1".equals(result);`
`} finally {`
`jedis.close();`
`}`
`}`
`}`具体的代码作用注释已经写得很清楚了,然后我们就可以写一个demo类来测试一下效果:
`public class RedisLockTest {`
`private static RedisLockUtil demo = new RedisLockUtil();`
`private static Integer NUM = 101;`
`public static void main(String[] args) {`
`for (int i = 0; i < 100; i++) {`
`new Thread(() -> {`
`String id = Thread.currentThread().getId() + "";`
`boolean isLock = demo.lock(id);`
`try {`
`// 拿到锁的话,就对共享参数减一`
`if (isLock) {`
`NUM--;`
`System.out.println(NUM);`
`}`
`} finally {`
`// 释放锁一定要注意放在finally`
`demo.unlock(id);`
`}`
`}).start();`
`}`
`}`
`}`我们创建100个线程来模拟并发的情况,执行后的结果是这样的:
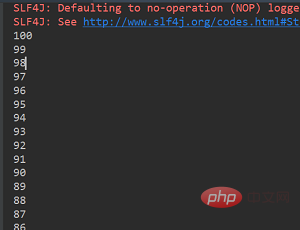
代码执行结果
可以看出,锁的效果达到了,线程安全是可以保证的。
当然,上面的代码只是简单的实现了效果,功能肯定是不完整的,一个健全的分布式锁要考虑的方面还有很多,实际设计起来不是那么容易的。
我们的目的只是为了学习和了解原理,手写一个工业级的分布式锁工具不现实,也没必要,类似的开源工具一大堆(Redisson),原理都差不多,而且早已经过业界同行的检验,直接拿来用就行。
虽然功能是实现了,但其实从设计上来说,这样的分布式锁存在着很大的缺陷,这也是本篇文章想重点探讨的内容。
一、客户端长时间阻塞导致锁失效问题
客户端1得到了锁,因为网络问题或者GC等原因导致长时间阻塞,然后业务程序还没执行完锁就过期了,这时候客户端2也能正常拿到锁,可能会导致线程安全的问题。
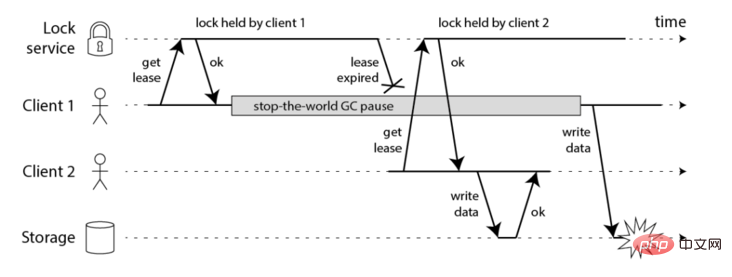
客户端长时间阻塞
那么该如何防止这样的异常呢?我们先不说解决方案,介绍完其他的缺陷后再来讨论。
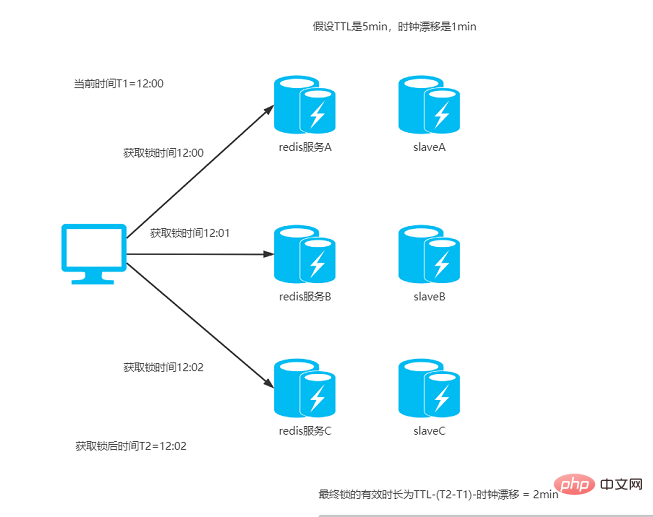
二、redis服务器时钟漂移问题
如果redis服务器的机器时钟发生了向前跳跃,就会导致这个key过早超时失效,比如说客户端1拿到锁后,key的过期时间是12:02分,但redis服务器本身的时钟比客户端快了2分钟,导致key在12:00的时候就失效了,这时候,如果客户端1还没有释放锁的话,就可能导致多个客户端同时持有同一把锁的问题。
三、单点实例安全问题
如果redis是单master模式的,当这台机宕机的时候,那么所有的客户端都获取不到锁了,为了提高可用性,可能就会给这个master加一个slave,但是因为redis的主从同步是异步进行的,可能会出现客户端1设置完锁后,master挂掉,slave提升为master,因为异步复制的特性,客户端1设置的锁丢失了,这时候客户端2设置锁也能够成功,导致客户端1和客户端2同时拥有锁。
为了解决Redis单点问题,redis的作者提出了RedLock算法。
该算法的实现前提在于Redis必须是多节点部署的,可以有效防止单点故障,具体的实现思路是这样的:
1、获取当前时间戳(ms);
2、先设定key的有效时长(TTL),超出这个时间就会自动释放,然后client(客户端)尝试使用相同的key和value对所有redis实例进行设置,每次链接redis实例时设置一个比TTL短很多的超时时间,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个redis实例。
比如:TTL(也就是过期时间)为5s,那获取锁的超时时间就可以设置成50ms,所以如果50ms内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁;
3、client通过获取所有能获取的锁后的时间减去第一步的时间,还有redis服务器的时钟漂移误差,然后这个时间差要小于TTL时间并且成功设置锁的实例数>= N/2 + 1(N为Redis实例的数量),那么加锁成功
比如TTL是5s,连接redis获取所有锁用了2s,然后再减去时钟漂移(假设误差是1s左右),那么锁的真正有效时长就只有2s了;
4、如果客户端由于某些原因获取锁失败,便会开始解锁所有redis实例。
根据这样的算法,我们假设有5个Redis实例的话,那么client只要获取其中3台以上的锁就算是成功了,用流程图演示大概就像这样:
キーの有効時間
わかりました。アルゴリズムが導入されました。設計の観点から見ると、主要なアイデアは間違いありません。 RedLock アルゴリズムの特徴は、Redis の単一点障害を効果的に防止するために、TTL の設計時にサーバー クロック ドリフトの誤差も考慮され、分散ロックのセキュリティが大幅に向上しました。
しかし、これは本当にそうなのでしょうか?
まず第一に、RedLock アルゴリズムでは、ロックの有効時間が Redis インスタンスへの接続にかかる時間だけ短縮されることがわかります。このプロセスがネットワークの問題によって引き起こされた場合 時間がかかりすぎると、ロックに残される有効時間が大幅に減少します クライアントが共有リソースにアクセスする時間が非常に短いため、ロックが期限切れになる可能性がありますプログラム処理中。また、ロックの有効時間をサーバーの時計のずれから差し引く必要がありますが、どのくらい差し引くべきでしょうか?この値をうまく設定しないと問題が発生しやすくなります。
2 番目のポイントは、このアルゴリズムでは Redis の単一障害点を防ぐために複数のノードの使用が考慮されていますが、ノードがクラッシュして再起動した場合、複数のクライアントが同じ時点でロックを取得する可能性があるということです。同時に。
合計 5 つの Redis ノードがあると仮定します: A、B、C、D、E、クライアント 1 と 2 がそれぞれロックされています
クライアント 1 は正常にロックされていますA、B、C が取得され、ロックの取得に成功しました (ただし、D と E はロックされていません)。
ノード C のマスターがダウンしており、ロックはまだスレーブに同期されていません。スレーブはマスターにアップグレードされた後、クライアント 1 によって追加されたロックを失いました。
クライアント 2 はこの時点でロックを取得し、C、D、E をロックし、ロックの取得に成功しました。
このように、クライアント 1 とクライアント 2 は同時にロックを取得しますが、プログラム セキュリティの隠れた危険は依然として存在します。さらに、これらのノードのいずれかで時間のドリフトが発生すると、ロックのセキュリティの問題が発生する可能性があります。
したがって、可用性と信頼性はマルチインスタンスのデプロイメントによって向上しますが、RedLock は Redis の単一障害点の隠れた危険を完全に解決するわけではなく、クロック ドリフトやクライアントの長期使用によって引き起こされる問題も解決しませんロックのタイムアウト障害の問題とロックのセキュリティ リスクは依然として存在します。
さらに質問したい人もいるかもしれません。ロックの絶対的な安全性を確保するにはどうすればよいでしょうか?
私が言えるのは、ケーキを食べながらケーキを食べることはできないということだけです。分散ロック ツールとして Redis を使用する理由は、主に Redis の高効率性と単一プロセスの特性によるものです。高い同時実行条件下では十分に保証できますが、多くの場合、パフォーマンスとセキュリティのバランスを完全に取ることはできません。ロックのセキュリティを確保する必要がある場合は、制御に db や Zookeeper などの他のミドルウェアを使用できます。これらのツールは、ロックの安全性は非常に優れていますが、性能は不十分としか言いようがありません。そうでなければ、昔は誰もがそれを使用していたでしょう。
一般的に、Redis を使用して共有リソースを制御し、高度なデータ セキュリティ要件が必要な場合、最終的に保証される解決策は、ビジネス データを冪等に制御することです。このようにして、複数のクライアントがロックを取得したとしても、状況はデータの一貫性には影響しません。もちろん、すべてのシーンがこれに適しているわけではなく、具体的な選択は各審査員に任されていますが、結局のところ、完璧な技術など存在せず、適した技術だけが最良となります。
プログラミング関連の知識について詳しくは、プログラミング入門をご覧ください。 !
以上がRedis の分散ロックについて深く理解できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



