SQL データベース クエリ ステートメントの完全な構文は、「Select [オプションの選択] フィールド リスト [フィールド エイリアス]/* データ ソースから [where 句] [group by 句] [having 句] [order by sub」です。文][制限句];"。

このチュートリアルの動作環境: Windows7 システム、mysql8 バージョン、Dell G3 コンピューター。
データベースは mysql で、使用されるデータベース テーブル名は my_student です。
テーブルの完全なデータ情報は次のとおりです:
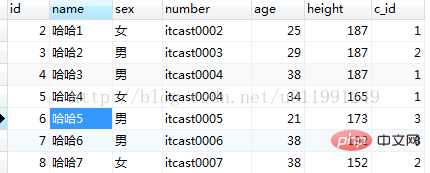
完全な構文は次のとおりです。
Select [オプションの選択] フィールド リスト [フィールド エイリアス]/* データ ソースから [where 句] [group by 句][having 句][order by 句][limit 句];
①[オプションの選択]:
オプションの選択には、ALL (すべて、デフォルト)、distinct (重複の削除) が含まれます。 Distinct は、クエリ結果のレコード全体を指します。
select DISTINCT(sex) from my_student;

##select DISTINCT(sex),name from my_student; 結果は selectDISTINCT sex,name from my_student と同じです; の。
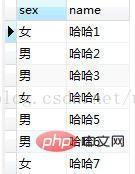
②[where 文]: ディスクからデータを取得する際に判定を開始する唯一の条件は、ディスクからレコードを取得して、どこから判定を開始するかです。判定結果が真であれば結果を取り出してメモリに保存し、そうでなければ諦める。
select * from my_student where name = 'Haha1';

#③[group by 句]: グループ化句、group by 句がメインです。関数は次のとおりです。表示のためではなく、統計操作のためにグループ化します (表示する場合、グループ化されたレコードの最初のレコードのみが表示されます)。グループ化する場合は、count()、max()、min()、avg()、sum() 関数が使用されます。
A. 単一のサブセグメントのグループ化:
selectc_id,count(*),max(height),min(height),avg(height),sum(age) from my_studentgroup by c_id ;

#SQL ステートメントの意味: my_student テーブルは c_id によってグループ化され、グループ化後の各グループの c_id 名、各グループの合計数、最高値、最低値、各グループの平均身長と年齢の合計。
B. 複数フィールドのグループ化
my_student グループから c_id、sex、count(*)、max(height)、min(height)、avg(height)、sum(age) を選択します。 by c_id,sex;
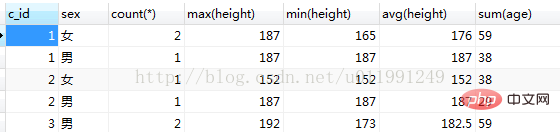
は、最初にテーブル全体が c_id に従ってグループ化され、次にこのグループ化に基づいて、各グループが性別に従ってグループ化されることを意味します。
C. 複数フィールドのグループ化 (さらに、各グループ内の特定のフィールドのすべてのデータを表示)
selectc_id,sex,count(*),max(height),min(height), avg(height),sum(age) ,GROUP_CONCAT(name)from my_student group by c_id ,sex;

④[having 句]:have の関数は次と似ています。 where と Has は、 where で実行できるほとんどすべてのことを実行できますが、主に
where がデータを操作できるのは、データがディスクから抽出されるときだけであるため、where で実行できることの多くは実行できません。メモリ内のデータをグループごとにグループ化した結果は、have によってのみ処理できます。
COUNT(*) >= 3 を持つ c_id による my_studentgroup からの selectc_id,count(*),max(height),min(height),avg(height),sum(age)
##⑤[order by 句]: 特定のフィールドに従ってデータを昇順または降順に並べ替えます。 (複数フィールドの並べ替えを実行する場合、最初に特定のフィールドに従って並べ替え、次に並べ替え順序内の特定のフィールドに従って並べ替えます)
A. 単一フィールドの並べ替え:
select * from my_student order by c_id;
B、複数フィールド並べ替え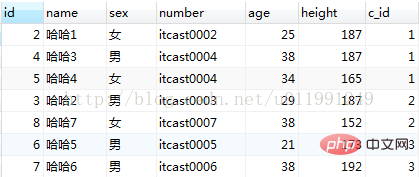
select * from my_student order by c_id,sex;
⑥[limit 句]: 結果の数を制限します。レコードのオフセット数を制限;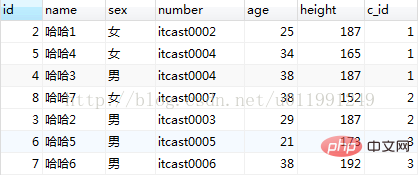
A、選択 * frommy_student 制限 2;
B、選択 * frommy_student 制限 0,3;
関連する推奨事項:「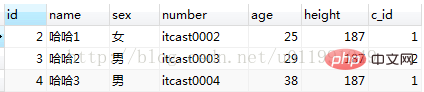 mysql チュートリアル
mysql チュートリアル
」
以上がSQLデータベースクエリステートメントの基本的な構文は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



