


一部のテーブルのデータ量は非常に急速に増加しており、対応する SQL が大量の無効なデータをスキャンするため、SQL が遅くなります。確認後、これらの大きなテーブルはすべて流水、レコード、およびログ タイプのデータであり、保持する必要があるのは 1 ~ 3 個だけですが、この時点で、軽量化を達成するためにテーブル内のデータをクリーンアップする必要があります。

この記事では、InnoDB ストレージ領域の分散、削除によるパフォーマンスへの影響、最適化の提案の観点から、データの削除が推奨されない理由を説明します。
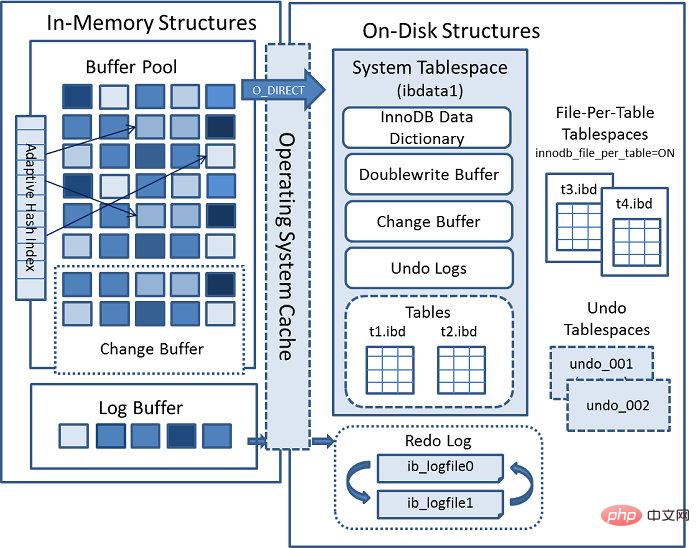
この図からわかるように、InnoDB ストレージ構造は主に、論理ストレージ構造と物理ストレージ構造の 2 つの部分で構成されています。
論理的にはテーブルスペース→セグメントまたはinode→エリアエクステント→データページで構成されており、Innodbの論理的な管理単位はセグメント、領域割り当ての最小単位はエクステントです。表スペース FREE_PAGE から 32 ページを割り当てます。これらの 32 ページが十分でない場合は、次の原則に従って拡張されます: 現在のエクステントが 1 エクステント未満の場合は、1 エクステントに拡張されます。表スペースが 32MB 未満の場合、各セグメントは 1 エクステントに拡張されます。一度に 1 エクステントを拡張します。表スペースが 32MB より大きい場合は、一度に 4 エクステントを拡張します。
物理的には、主にシステム ユーザー データ ファイルとログ ファイルで構成されます。データ ファイルには主に MySQL ディクショナリ データとユーザー データが保存されます。ログ ファイルはデータ ページの変更記録を記録し、MySQL のリカバリ時に使用されます。クラッシュします。
InnoDB ストレージには、システム テーブル スペース、ユーザー テーブル スペース、および Undo テーブル スペースの 3 種類のテーブル スペースが含まれています。
システム テーブル スペース: 主に、information_schema 下のデータなど、MySQL の内部データ ディクショナリ データを格納します。
ユーザー テーブル スペース: innodb_file_per_table=1 がオンになっている場合、データ テーブルはシステム テーブル スペースから分離され、table_name.ibd コマンドを使用してデータ ファイルに保存されます。情報はファイルの table_name.frm に保存されます。
UNDO 表スペース: UNDO 情報を保管する (スナップショット整合読み取りやフラッシュバックなど)。これらはすべて UNDO 情報を使用します。
MySQL 8.0 以降、ユーザーはテーブル スペースをカスタマイズできます。具体的な構文は次のとおりです:
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name' #数据文件名
USE LOGFILE GROUP logfile_group #自定义日志文件组,一般每组2个logfile。
[EXTENT_SIZE [=] extent_size] #区大小
[INITIAL_SIZE [=] initial_size] #初始化大小
[AUTOEXTEND_SIZE [=] autoextend_size] #自动扩宽尺寸
[MAX_SIZE [=] max_size] #单个文件最大size,最大是32G。
[NODEGROUP [=] nodegroup_id] #节点组
[WAIT]
[COMMENT [=] comment_text]
ENGINE [=] engine_nameこれの利点は、ホット データとコールド データを分離し、HDD とハードウェアを使用できることです。 SSD を使用してそれぞれを保存します。データへの効率的なアクセスを実現し、コストを節約できます。たとえば、2 つの 500G ハードディスクを追加し、ボリューム グループ vg を作成し、論理ボリューム lv を分割し、データ ディレクトリを作成して、対応する lv をマウントします。 2つに分かれたディレクトリを/hot_dataと/cold_dataとする。
これにより、ユーザーテーブルや注文テーブルなどの基幹業務テーブルは高性能SSDディスクに保存し、一部のログやフローテーブルは通常のHDDに保存することができます。 :
#创建热数据表空间 create tablespace tbs_data_hot add datafile '/hot_data/tbs_data_hot01.dbf' max_size 20G; #创建核心业务表存储在热数据表空间 create table booking(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_hot; #创建冷数据表空间 create tablespace tbs_data_cold add datafile '/hot_data/tbs_data_cold01.dbf' max_size 20G; #创建日志,流水,备份类的表存储在冷数据表空间 create table payment_log(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_cold; #可以移动表到另一个表空间 alter table payment_log tablespace tbs_data_hot;
mysql> create table user(id bigint not null primary key auto_increment,
-> name varchar(20) not null default '' comment '姓名',
-> age tinyint not null default 0 comment 'age',
-> gender char(1) not null default 'M' comment '性别',
-> phone varchar(16) not null default '' comment '手机号',
-> create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
-> update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
-> ) engine = InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户信息表';
Query OK, 0 rows affected (0.26 sec)# ls -lh user1.ibd -rw-r----- 1 mysql mysql 96K Nov 6 12:48 user.ibd
パラメータ innodb_file_per_table=1 を設定すると、テーブルの作成時にセグメントが自動的に作成されます, データを保存するための 32 データ ページを含むエクステントが同時に割り当てられます。この方法で作成された空のテーブルの既定のサイズは 96 KB です。エクステントが使用された後、64 の接続ページが適用されます。たとえば、一部の小さなテーブルや UNDO セグメントの場合、ディスク容量を節約するために、最初に適用できるスペースが少なくなります。
# python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0000> page offset 00000000, page type <Freshly Allocated Page> page offset 00000000, page type <Freshly Allocated Page> Total number of page: 6: #总共分配的页数 Freshly Allocated Page: 2 #可用的数据页 Insert Buffer Bitmap: 1 #插入缓冲页 File Space Header: 1 #文件空间头 B-tree Node: 1 #数据页 File Segment inode: 1 #文件端inonde,如果是在ibdata1.ibd上会有多个inode。
mysql> DELIMITER $$
mysql> CREATE PROCEDURE insert_user_data(num INTEGER)
-> BEGIN
-> DECLARE v_i int unsigned DEFAULT 0;
-> set autocommit= 0;
-> WHILE v_i < num DO
-> insert into user(`name`, age, gender, phone) values (CONCAT('lyn',v_i), mod(v_i,120), 'M', CONCAT('152',ROUND(RAND(1)*100000000)));
-> SET v_i = v_i+1;
-> END WHILE;
-> commit;
-> END $$
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER ;
#插入10w数据
mysql> call insert_user_data(100000);
Query OK, 0 rows affected (6.69 sec)# ls -lh user.ibd -rw-r----- 1 mysql mysql 14M Nov 6 10:58 /data2/mysql/test/user.ibd # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> #增加了一个非叶子节点,树的高度从1变为2. ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1
mysql> select min(id),max(id),count(*) from user; +---------+---------+----------+ | min(id) | max(id) | count(*) | +---------+---------+----------+ | 1 | 100000 | 100000 | +---------+---------+----------+ 1 row in set (0.05 sec) #删除50000条数据,理论上空间应该从14MB变长7MB左右。 mysql> delete from user limit 50000; Query OK, 50000 rows affected (0.25 sec) #数据文件大小依然是14MB,没有缩小。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 14M Nov 6 13:22 /data2/mysql/test/user.ibd #数据页没有被回收。 # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1 #在MySQL内部是标记删除,
mysql> use information_schema; Database changed mysql> SELECT A.SPACE AS TBL_SPACEID, A.TABLE_ID, A.NAME AS TABLE_NAME, FILE_FORMAT, ROW_FORMAT, SPACE_TYPE, B.INDEX_ID , B.NAME AS INDEX_NAME, PAGE_NO, B.TYPE AS INDEX_TYPE FROM INNODB_SYS_TABLES A LEFT JOIN INNODB_SYS_INDEXES B ON A.TABLE_ID =B.TABLE_ID WHERE A.NAME = 'test/user1'; +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | TBL_SPACEID | TABLE_ID | TABLE_NAME | FILE_FORMAT | ROW_FORMAT | SPACE_TYPE | INDEX_ID | INDEX_NAME | PAGE_NO | INDEX_TYPE | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | 1283 | 1207 | test/user | Barracuda | Dynamic | Single | 2236 | PRIMARY | 3 | 3 | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ 1 row in set (0.01 sec) PAGE_NO = 3 标识B-tree的root page是3号页,INDEX_TYPE = 3是聚集索引。 INDEX_TYPE取值如下: 0 = nonunique secondary index; 1 = automatically generated clustered index (GEN_CLUST_INDEX); 2 = unique nonclustered index; 3 = clustered index; 32 = full-text index; #收缩空间再后进行观察
MySQL は実際には内部的にスペースを削除せず、削除をマーク (デルフラグ) します。 :N delflag:Y に変更します。コミット後、削除リンク リストにパージされます。次回、より大きなレコードが挿入された場合、削除後のスペースは再利用されません。挿入されたレコードが以下の場合、このブロックの内容は、Zhishutang の innblock ツールを通じて分析できます。
データはファイル システムに保存されており、それに割り当てられた物理スペースの 100% が常に使用できるわけではないことがわかっています。データを削除します ページ上にいくつかの「穴」が残るか、ランダムな書き込み (クラスタ化インデックスの非線形増加) によりページ分割が発生します。ページ分割により、ページ使用率が 50% 未満になります。また、テーブルへの追加、削除、および変更により、対応する二次的な変更が発生します。レベルレベルのインデックス値のランダムな追加、削除、および変更も、インデックス構造のデータ ページにいくつかの「穴」が残る原因になります。ホールは再利用できますが、最終的には物理スペースの一部が未使用になる、つまり断片化が発生します。
同時に、Fill Factor が 100% に設定されている場合でも、Innodb はページの 1/16 を予約スペースとして積極的に残します (innodb_fill_factor を 100 に設定すると、スペースの 1/16 が残ります)クラスタ化インデックス ページでは、将来のインデックスの増加に備えて空き領域が確保されます)。これは、更新による行のオーバーフローを防ぐためです。
mysql> select table_schema,
-> table_name,ENGINE,
-> round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
-> round(DATA_LENGTH/1024/1024) data_mb, round(INDEX_LENGTH/1024/1024) index_mb, round(DATA_FREE/1024/1024) free_mb, round(DATA_FREE/DATA_LENGTH*100,2) free_ratio
-> from information_schema.TABLES where TABLE_SCHEMA= 'test'
-> and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 4 | 50000 | 4 | 0 | 6 | 149.42 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)Data_free は割り当てられた未使用のバイト数であり、完全に断片化された領域であることを意味するものではありません。
InnoDB テーブルの場合、次のコマンドを使用してフラグメントをリサイクルし、スペースを解放できます。これはランダム読み取り IO 操作であり、時間がかかり、また、テーブルに対する通常の操作をブロックします。DML 操作にはさらに多くのディスク領域が必要です。RDS の場合、ディスク領域がすぐにいっぱいになる可能性があり、インスタンスは即座にロックされ、アプリケーションは DML 操作を実行できないため、オンライン環境での実行は禁止されています。
#执行InnoDB的碎片回收 mysql> alter table user engine=InnoDB; Query OK, 0 rows affected (9.00 sec) Records: 0 Duplicates: 0 Warnings: 0 ##执行完之后,数据文件大小从14MB降低到10M。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 10M Nov 6 16:18 /data2/mysql/test/user.ibd
mysql> select table_schema,
->table_name,ENGINE,
->round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
->round(DATA_LENGTH/1024/1024) data_mb,
->round(INDEX_LENGTH/1024/1024) index_mb,
->round(DATA_FREE/1024/1024) free_mb,
->round(DATA_FREE/DATA_LENGTH*100,2) free_ratio from information_schema.TABLES where TABLE_SCHEMA= 'test' and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 5 | 50000 | 5 | 0 | 2 | 44.29 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)#插入100W数据 mysql> call insert_user_data(1000000); Query OK, 0 rows affected (35.99 sec) #添加相关索引 mysql> alter table user add index idx_name(name), add index idx_phone(phone); Query OK, 0 rows affected (6.00 sec) Records: 0 Duplicates: 0 Warnings: 0 #表上索引统计信息 mysql> show index from user; +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | user | 0 | PRIMARY | 1 | id | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_name | 1 | name | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_phone | 1 | phone | A | 2 | NULL | NULL | | BTREE | | | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.00 sec) #执行SQL语句 mysql> select id, age ,phone from user where name like 'lyn12%'; +--------+-----+-------------+ | id | age | phone | +--------+-----+-------------+ | 124 | 3 | 15240540354 | | 1231 | 30 | 15240540354 | | 12301 | 60 | 15240540354 | ............................. | 129998 | 37 | 15240540354 | | 129999 | 38 | 15240540354 | | 130000 | 39 | 15240540354 | +--------+-----+-------------+ 11111 rows in set (0.03 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) #查看相关状态呢变量 mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 11111 | #请求读的行数 | INNODB_DATA_READS | 7868409 | #数据物理读的总数 | INNODB_PAGES_READ | 7855239 | #逻辑读的总数 | LAST_QUERY_COST | 10.499000 | #SQL语句的成本COST,主要包括IO_COST和CPU_COST。 +-------------------+----------------+ 4 rows in set (0.00 sec)
#删除50w数据 mysql> delete from user limit 500000; Query OK, 500000 rows affected (3.70 sec) #分析表统计信息 mysql> analyze table user; +-----------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +-----------+---------+----------+----------+ | test.user | analyze | status | OK | +-----------+---------+----------+----------+ 1 row in set (0.01 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.01 sec) mysql> select id, age ,phone from user where name like 'lyn12%'; Empty set (0.05 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 0 | | INNODB_DATA_READS | 7868409 | | INNODB_PAGES_READ | 7855239 | | LAST_QUERY_COST | 10.499000 | +-------------------+----------------+ 4 rows in set (0.00 sec)
| 操作 | COST | 物理读次数 | 逻辑读次数 | 扫描行数 | 返回行数 | 执行时间 |
|---|---|---|---|---|---|---|
| 初始化插入100W | 10.499000 | 7868409 | 7855239 | 22226 | 11111 | 30ms |
| 100W随机删除50W | 10.499000 | 7868409 | 7855239 | 22226 | 0 | 50ms |
这也说明对普通的大表,想要通过delete数据来对表进行瘦身是不现实的,所以在任何时候不要用delete去删除数据,应该使用优雅的标记删除。
对于一个大的系统来说,需要根据业务特点去拆分子系统,每个子系统可以看做是一个service,例如美团APP,上面有很多服务,核心的服务有用户服务user-service,搜索服务search-service,商品product-service,位置服务location-service,价格服务price-service等。每个服务对应一个数据库,为该数据库创建单独账号,同时只授予DML权限且没有delete权限,同时禁止跨库访问。
#创建用户数据库并授权 create database mt_user charset utf8mb4; grant USAGE, SELECT, INSERT, UPDATE ON mt_user.* to 'w_user'@'%' identified by 't$W*g@gaHTGi123456'; flush privileges;
在MySQL数据库建模规范中有4个公共字段,基本上每个表必须有的,同时在create_time列要创建索引,有两方面的好处:
一些查询业务场景都会有一个默认的时间段,比如7天或者一个月,都是通过create_time去过滤,走索引扫描更快。
一些核心的业务表需要以T +1的方式抽取数据仓库中,比如每天晚上00:30抽取前一天的数据,都是通过create_time过滤的。
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `is_deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否逻辑删除:0:未删除,1:已删除', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间' #有了删除标记,业务接口的delete操作就可以转换为update update user set is_deleted = 1 where user_id = 1213; #查询的时候需要带上is_deleted过滤 select id, age ,phone from user where is_deleted = 0 and name like 'lyn12%';
#1. 创建归档表,一般在原表名后面添加_bak。 CREATE TABLE `ota_order_bak` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `order_id` varchar(255) DEFAULT NULL COMMENT '订单id', `ota_id` varchar(255) DEFAULT NULL COMMENT 'ota', `check_in_date` varchar(255) DEFAULT NULL COMMENT '入住日期', `check_out_date` varchar(255) DEFAULT NULL COMMENT '离店日期', `hotel_id` varchar(255) DEFAULT NULL COMMENT '酒店ID', `guest_name` varchar(255) DEFAULT NULL COMMENT '顾客', `purcharse_time` timestamp NULL DEFAULT NULL COMMENT '购买时间', `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `create_user` varchar(255) DEFAULT NULL, `update_user` varchar(255) DEFAULT NULL, `status` int(4) DEFAULT '1' COMMENT '状态 : 1 正常 , 0 删除', `hotel_name` varchar(255) DEFAULT NULL, `price` decimal(10,0) DEFAULT NULL, `remark` longtext, PRIMARY KEY (`id`), KEY `IDX_order_id` (`order_id`) USING BTREE, KEY `hotel_name` (`hotel_name`) USING BTREE, KEY `ota_id` (`ota_id`) USING BTREE, KEY `IDX_purcharse_time` (`purcharse_time`) USING BTREE, KEY `IDX_create_time` (`create_time`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中无效的数据(需要跟开发同学确认数据保留范围) create table tbl_p201808 as select * from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59'; #3. 跟归档表分区做分区交换 alter table ota_order_bak exchange partition p201808 with table tbl_p201808; #4. 删除原表中已经规范的数据 delete from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59' limit 3000;
#1. 创建中间表 CREATE TABLE `ota_order_2020` (........) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中有效的数据,如果数据量在100W左右可以在业务低峰期直接插入,如果比较大,建议采用dataX来做,可以控制频率和大小,之前我这边用Go封装了dataX可以实现自动生成json文件,自定义大小去执行。 insert into ota_order_2020 select * from ota_order where create_time between '2020-08-01 00:00:00' and '2020-08-31 23:59:59'; #3. 表重命名 alter table ota_order rename to ota_order_bak; alter table ota_order_2020 rename to ota_order; #4. 插入差异数据 insert into ota_order select * from ota_order_bak a where not exists (select 1 from ota_order b where a.id = b.id); #5. ota_order_bak改造成分区表,如果表比较大不建议直接改造,可以先创建好分区表,通过dataX把导入进去即可。 #6. 后续的归档方法 #创建中间普遍表 create table ota_order_mid like ota_order; #交换原表无效数据分区到普通表 alter table ota_order exchange partition p201808 with table ota_order_mid; ##交换普通表数据到归档表的相应分区 alter table ota_order_bak exchange partition p201808 with table ota_order_mid;
这样原表和归档表都是按月的分区表,只需要创建一个中间普通表,在业务低峰期做两次分区交换,既可以删除无效数据,又能回收空,而且没有空间碎片,不会影响表上的索引及SQL的执行计划。
通过从InnoDB存储空间分布,delete对性能的影响可以看到,delete物理删除既不能释放磁盘空间,而且会产生大量的碎片,导致索引频繁分裂,影响SQL执行计划的稳定性;
同时在碎片回收时,会耗用大量的CPU,磁盘空间,影响表上正常的DML操作。
在业务代码层面,应该做逻辑标记删除,避免物理删除;为了实现数据归档需求,可以用采用MySQL分区表特性来实现,都是DDL操作,没有碎片产生。
另外一个比较好的方案采用Clickhouse,对有生命周期的数据表可以使用Clickhouse存储,利用其TTL特性实现无效数据自动清理。
相关推荐:《mysql教程》
以上がmysql はデータを削除するときに delete を使用しないのはなぜですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



