

次のコラムでは、#Redis チュートリアルコラムで Redis6.0 でマルチスレッドが導入される理由を紹介します。 , 困っている友達のお役に立てれば幸いです!


なぜ Redis は 6.0 より前にシングルスレッド モデルを使用したのですか?
シングルスレッド モデルのパフォーマンスがこれほど高いのはなぜですか?

まず、Redis のほとんどの操作はメモリに基づいており、純粋な kv (キーと値) 操作であるため、コマンドの実行速度は非常に高速です。 Redis 上のデータは大きな HashMap に格納されていることが大まかに理解できますが、HashMap の利点は、検索と書き込みの時間計算量が O(1) であることです。 Redis はこの構造を使用してデータを内部に保存し、Redis の高いパフォーマンスの基盤を築きます。 Redis 公式 Web サイトの説明によると、理想的な状況下では、Redis は 1 秒あたり 100 万件のリクエストを送信でき、各リクエストの送信に必要な時間はナノ秒のオーダーです。 Redis のすべての操作は非常に高速で、単一のスレッドで完全に処理できるため、わざわざマルチスレッドを使用する必要はありません。
スレッド コンテキストの切り替えの問題さらに、マルチスレッド シナリオでは、スレッド コンテキストの切り替えが発生します。スレッドは CPU によってスケジュールされます。CPU の 1 つのコアは、タイム スライス内で同時に 1 つのスレッドのみを実行できます。一連の操作は、CPU がスレッド A からスレッド B に切り替わるときに発生します。メイン プロセスには実行の保存が含まれますスレッドAの実行シーンを読み込み、スレッドBの実行シーンを読み込みます。この処理が「スレッドコンテキストの切り替え」です。これには、スレッド関連の命令の保存と復元が含まれます。
スレッド コンテキストの切り替えが頻繁に行われると、パフォーマンスが急激に低下する可能性があり、その結果、リクエストの処理速度が向上しないだけでなく、パフォーマンスも低下することになります。これが、Redis が慎重な理由の 1 つです。マルチスレッド技術。
Linux システムでは、vmstat コマンドを使用してコンテキスト スイッチの数を確認できます。次に、vmstat を使用してコンテキスト スイッチの数を確認する例を示します:
vmstat 1 は 1 秒あたり 1 回カウントすることを意味し、cs 列はコンテキスト スイッチの数を示します。一般に、アイドル システムのコンテキスト スイッチは 1 秒あたり 1500 未満です。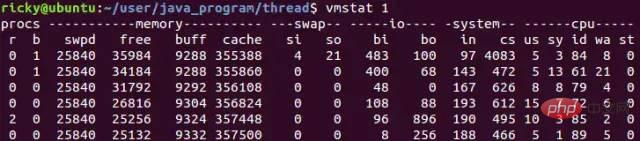
ネットワーク ボトルネックの場合、Redis はネットワーク I/O モデルで多重化テクノロジを使用して、ネットワーク ボトルネックの影響を軽減します。多くのシナリオでシングルスレッド モデルが使用されているからといって、プログラムがタスクを同時に処理できないわけではありません。 Redis はシングルスレッド モデルを使用してユーザー リクエストを処理しますが、I/O 多重化テクノロジを使用して、複数の接続から送信されるリクエストを待機しながら、クライアントからの複数の接続を「並列」処理します。 I/O 多重化テクノロジを使用すると、システムのオーバーヘッドが大幅に削減され、システムは接続ごとに専用のリスニング スレッドを作成する必要がなくなり、多数のスレッドの作成によって引き起こされる膨大なパフォーマンスのオーバーヘッドを回避できます。
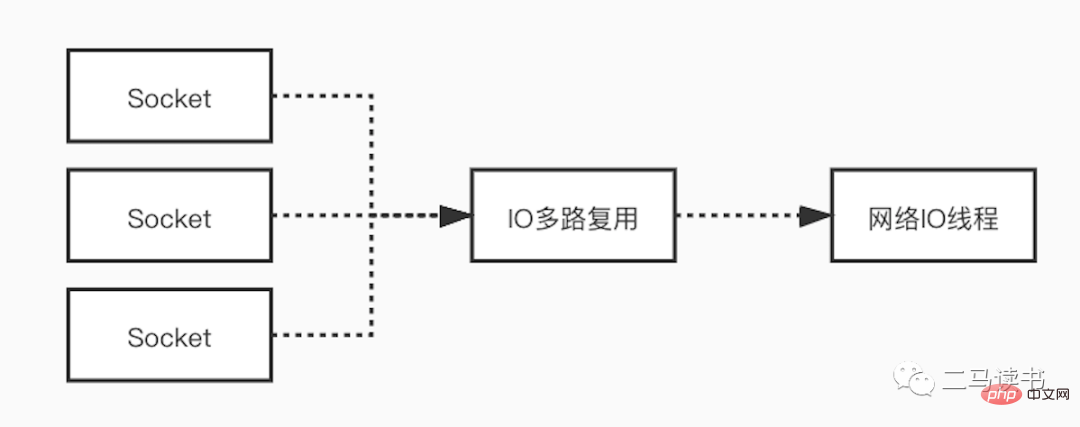
多重化 I/O モデルについて詳しく説明します。これをより完全に理解するには、まずいくつかの基本概念を理解します。
ソケット (ソケット): ソケットは、2 つのアプリケーションがネットワーク上で通信するときの 2 つのアプリケーションの通信エンドポイントとして理解できます。通信中、あるアプリケーションはソケットにデータを書き込み、そのデータをネットワーク カード経由で別のアプリケーションのソケットに送信します。私たちが通常 HTTP および TCP プロトコルと呼ぶリモート通信は、最下層の Socket に基づいて実装されます。 5 つのネットワーク IO モデルもすべて、Socket に基づいたネットワーク通信を実装しています。
ブロッキングと非ブロッキング: いわゆるブロッキングとは、すべてのロジックが処理されるまでリクエストをすぐに返すことができず、応答を返すことができないことを意味します。逆に、ノンブロッキングでは、すべてのロジックが処理されるのを待たずに、リクエストを送信し、すぐにレスポンスを返します。
カーネル空間とユーザー空間: Linux では、アプリケーション プログラムの安定性はオペレーティング システム プログラムの安定性よりもはるかに劣るため、オペレーティング システムの安定性を確保するために、Linux はカーネル空間とユーザー空間を区別します。カーネル空間ではオペレーティング システム プログラムとドライバーが実行され、ユーザー空間ではアプリケーションが実行されることが理解できます。このようにして、Linux はオペレーティング システムのプログラムとアプリケーションを分離し、アプリケーションがオペレーティング システム自体の安定性に影響を与えるのを防ぎます。これは、Linux システムが非常に安定している主な理由でもあります。ディスク ファイルの読み取りと書き込み、メモリの割り当てとリサイクル、ネットワーク インターフェイスの呼び出しなど、すべてのシステム リソース操作はカーネル空間で実行されます。したがって、ネットワーク IO 読み取りプロセス中、データはネットワーク カードからユーザー空間のアプリケーション バッファーに直接読み取られるのではなく、まずネットワーク カードからカーネル空間バッファーにコピーされ、次にカーネルからユーザーにコピーされます。スペース、アプリケーションバッファ。ネットワーク IO 書き込みプロセスの場合はその逆で、まずユーザー空間のアプリケーション バッファからカーネル バッファにデータがコピーされ、次にカーネル バッファからネットワーク カードを介してデータが送信されます。
多重化 I/O モデルは、マルチチャネル イベント分離関数 select、poll、および epoll に基づいて構築されています。 Redis で使用される epoll を例にとると、読み取りリクエストを開始する前に、まず epoll のソケット監視リストが更新され、その後 epoll 関数が戻るのを待ちます (このプロセスはブロックしているため、多重化 IO は本質的にブロッキング IO モデルです)。 。特定のソケットからデータが到着すると、epoll 関数が戻ります。この時点で、ユーザー スレッドはデータを読み取って処理するための読み取りリクエストを正式に開始します。このモードでは、専用の監視スレッドを使用して複数のソケットをチェックし、特定のソケットにデータが到着すると、ワーカー スレッドに引き渡されて処理されます。 Socket データの到着を待つプロセスは非常に時間がかかるため、この方法は、ブロッキング IO モデルの 1 つの Socket 接続に 1 つのスレッドが必要であるという問題を解決し、非ブロック IO モデルでのビジー ポーリングによる CPU パフォーマンスの損失の問題も発生しません。 -ブロッキングIOモデル。多重 IO モデルには多くの実用的なアプリケーション シナリオがあり、よく知られている Redis、Java NIO、Dubbo が使用する通信フレームワークである Netty はすべてこのモデルを使用しています。
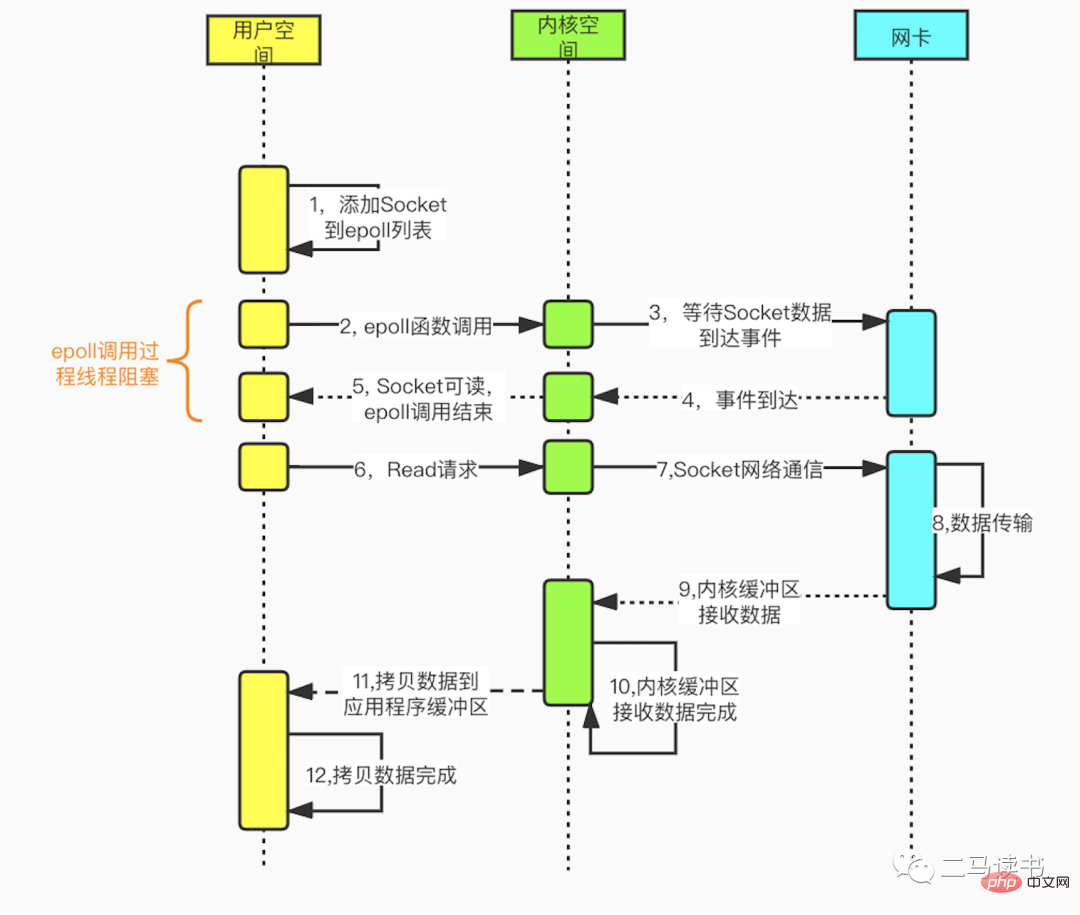
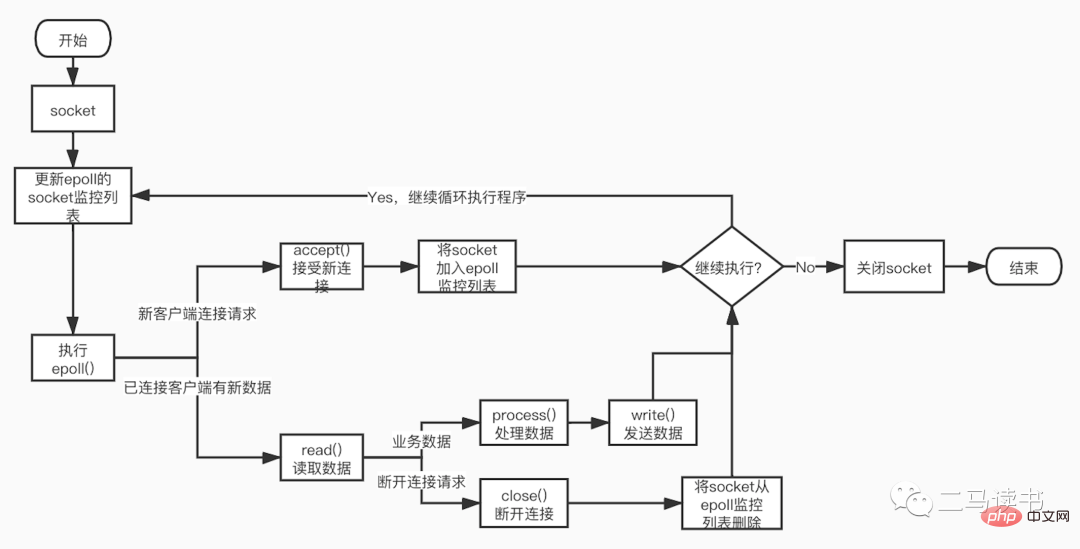
#次の図は、epoll 関数に基づくソケット プログラミングの詳細なプロセスです。
マルチスレッドによりマルチコア CPU を最大限に活用できることがわかっています。高い同時実行性の実現 このシナリオでは、I/O 待機による CPU の損失が軽減され、良好なパフォーマンスがもたらされます。ただし、マルチスレッドは諸刃の剣であり、利点がある一方で、コードのメンテナンス、オンラインの問題の特定とデバッグの困難、デッドロックなどの問題も引き起こします。マルチスレッド モデルにおけるコードの実行プロセスはシリアルではなくなり、複数のスレッドによって同時にアクセスされる共有変数も、適切に処理されないと奇妙な問題を引き起こす可能性があります。
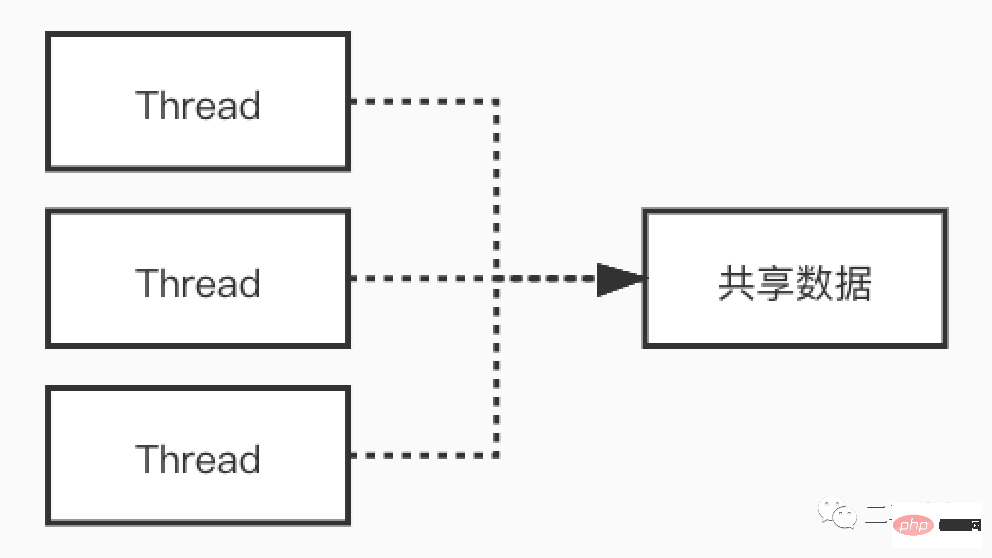
# 例を使用して、マルチスレッド シナリオで発生する奇妙な現象を見てみましょう。以下のコードを見てください。
class MemoryReordering { int num = 0; boolean flag = false; public void set() { num = 1; //语句1 flag = true; //语句2 } public int cal() { if( flag == true) { //语句3 return num + num; //语句4 } return -1; } }
flag が true の場合、cal() メソッドの戻り値は何ですか?多くの人はこう言うだろう:そもそも聞く必要があるのか?必ず 2
结果可能会让你大吃一惊!上面的这段代码,由于语句1和语句2没有数据依赖性,可能会发生指令重排序,有可能编译器会把flag=true放到num=1的前面。此时set和cal方法分别在不同线程中执行,没有先后关系。cal方法,只要flag为true,就会进入if的代码块执行相加的操作。可能的顺序是:
语句1先于语句2执行,这时的执行顺序可能是:语句1->语句2->语句3->语句4。执行语句4前,num = 1,所以cal的返回值是2
语句2先于语句1执行,这时的执行顺序可能是:语句2->语句3->语句4->语句1。执行语句4前,num = 0,所以cal的返回值是0
我们可以看到,在多线程环境下如果发生了指令重排序,会对结果造成严重影响。
当然可以在第三行处,给flag加上关键字volatile来避免指令重排。即在flag处加上了内存栅栏,来阻隔flag(栅栏)前后的代码的重排序。当然多线程还会带来可见性问题,死锁问题以及共享资源安全等问题。
boolean volatile flag = false;
Redis6.0引入的多线程部分,实际上只是用来处理网络数据的读写和协议解析,执行命令仍然是单一工作线程。
从上图我们可以看到Redis在处理网络数据时,调用epoll的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,达到几万的QPS,此处可能会成为瓶颈。一般我们遇到此类网络IO瓶颈的问题,可以增加线程数来解决。开启多线程除了可以减少由于网络I/O等待造成的影响,还可以充分利用CPU的多核优势。Redis6.0也不例外,在此处增加了多线程来处理网络数据,以此来提高Redis的吞吐量。当然相关的命令处理还是单线程运行,不存在多线程下并发访问带来的种种问题。
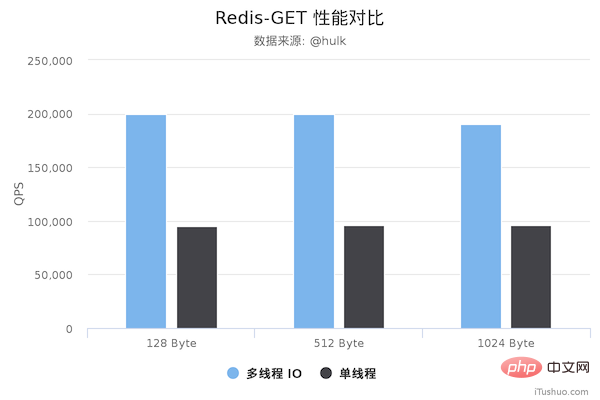
性能对比
压测配置:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge
多线程版本Redis 6.0,单线程版本是 Redis 5.0.5。多线程版本需要新增以下配置:
io-threads 4 # 开启 4 个 IO 线程 io-threads-do-reads yes # 请求解析也是用 IO 线程
压测命令:redis-benchmark -h 192.168.0.49 -a foobared -t set,get -n 1000000 -r 100000000 --threads 4 -d ${datasize} -c 256
图片来源于网络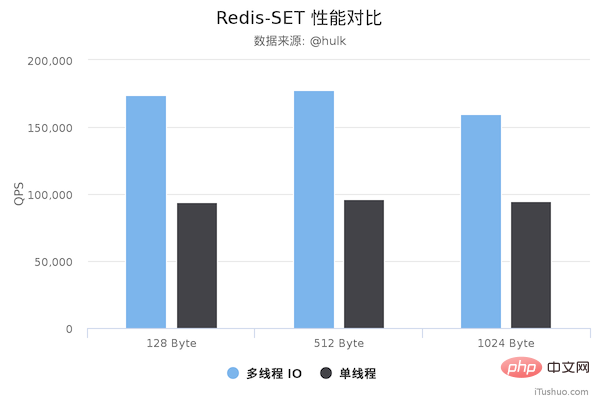
图片来源于网络
从上面可以看到 GET/SET 命令在多线程版本中性能相比单线程几乎翻了一倍。另外,这些数据只是为了简单验证多线程 I/O 是否真正带来性能优化,并没有针对具体的场景进行压测,数据仅供参考。本次性能测试基于 unstble 分支,不排除后续发布的正式版本的性能会更好。
最后
可见单线程有单线程的好处,多线程有多线程的优势,只有充分理解其中的本质原理,才能灵活运用于生产实践当中。
以上がRedis6.0 でマルチスレッドが導入されるのはなぜですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



