

多くの友人がすでにマスター/スレーブ レプリケーションを構成していると思いますが、Redis のマスター/スレーブ レプリケーションのワークフローと一般的な問題については深く理解していません。今回、Kaka は 2 日間を費やして、Redis のマスター/スレーブ レプリケーションに関するすべてのナレッジ ポイントをまとめました。
#この記事を実装するために必要な環境 centos7.0 redis4.0
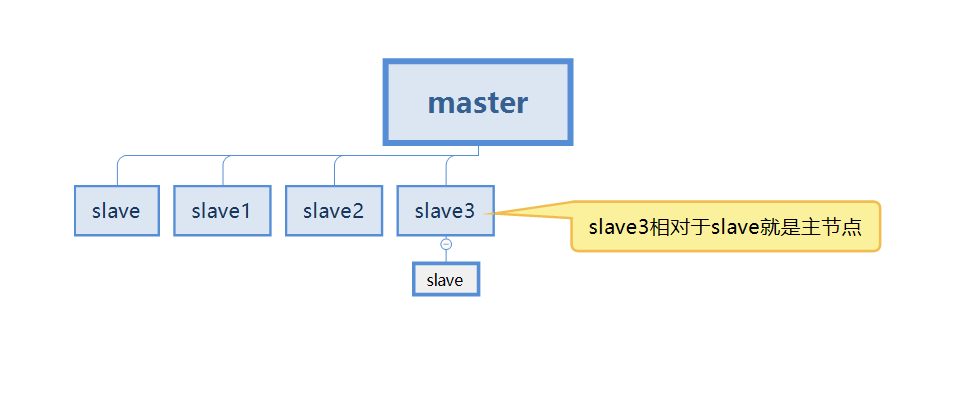
現在、スタンドアロン状態の Redis サーバーがあると仮定します。
この場合に発生する最初の問題はサーバーのダウンタイムであり、これはデータ損失に直接つながります。プロジェクトが人民元に関連している場合、その結果は想像できます。
マスターとスレーブをどのように接続するか?この時点で多くの質問があるはずです。データを同期するにはどうすればよいですか?マスターサーバーがダウンしたらどうなるでしょうか?心配しないで、少しずつ問題を解決してください。
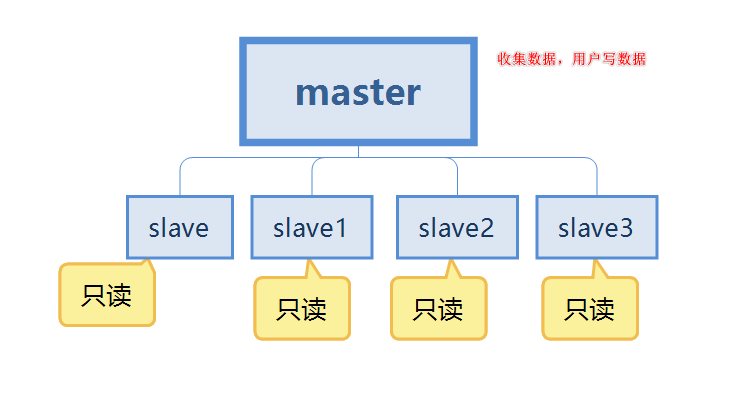
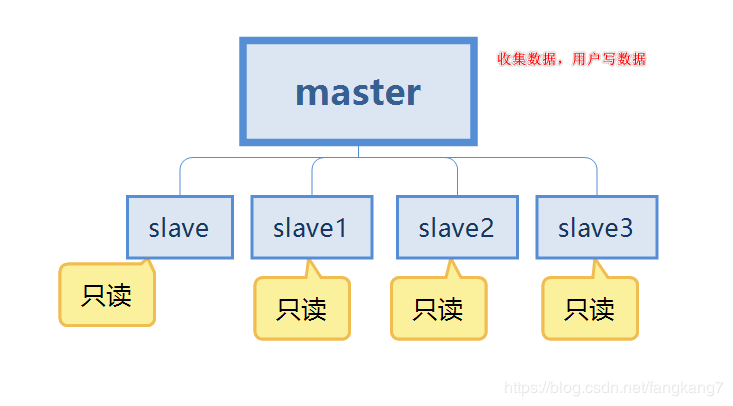
#Redis ストレージ パスは次のとおりです: usr/local/redis
ログ ファイルと構成ファイルは次の場所に保存されます。 usr/local /redis/data
最初に、redis6379.conf と redis6380.conf という 2 つの構成ファイルを構成します
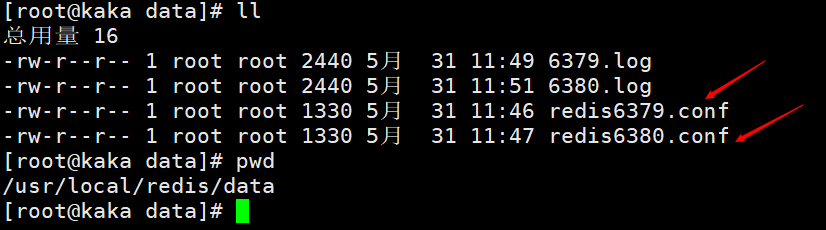
構成ファイルを変更します。主にポートを変更します。表示しやすいように、ログ ファイルと永続ファイルの名前はそれぞれのポートで識別されます。
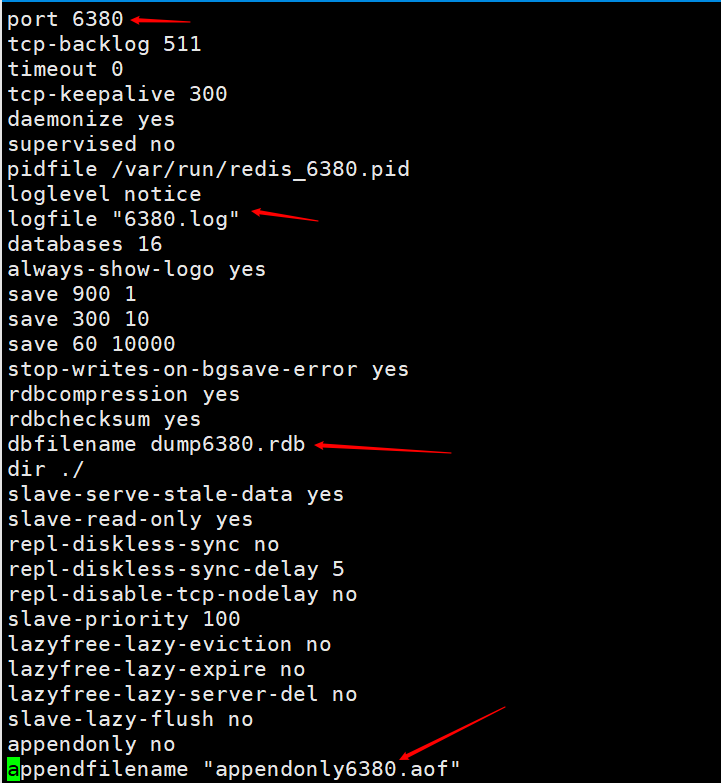
次に、2 つの Redis サービスを開きます。1 つはポート 6379 で、もう 1 つはポート 6380 です。コマンドredis-server redis6380.confを実行し、redis-cli -p 6380を使用して接続します。redis のデフォルトのポートは 6379 であるため、別の redis サーバーを起動して、直接redis-server redis6379.conf次に、redis-cliを使用して直接接続します。

現時点では、2 つの Redis サービス (1 つは 6380 用、もう 1 つは 6379 用) が正常に構成されました。これは単なるデモンストレーションです。実際の作業では、2 つの異なるサーバー上で構成する必要があります。
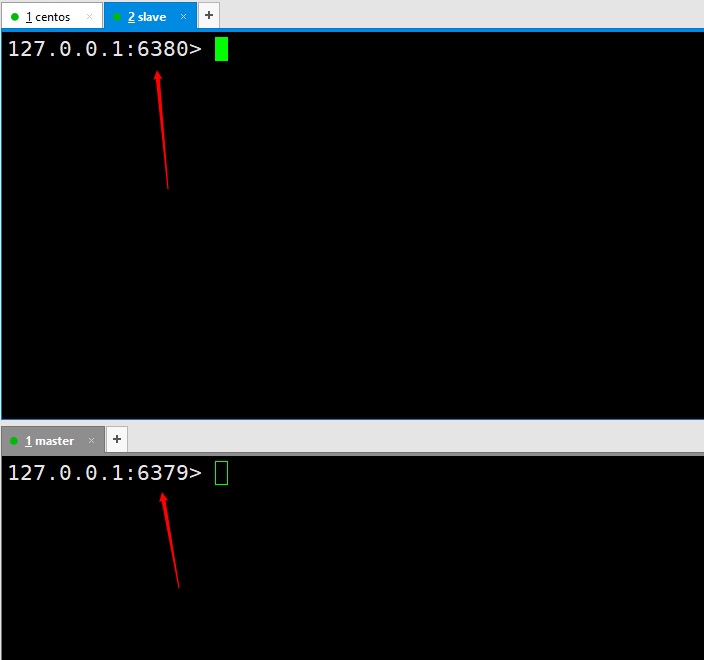
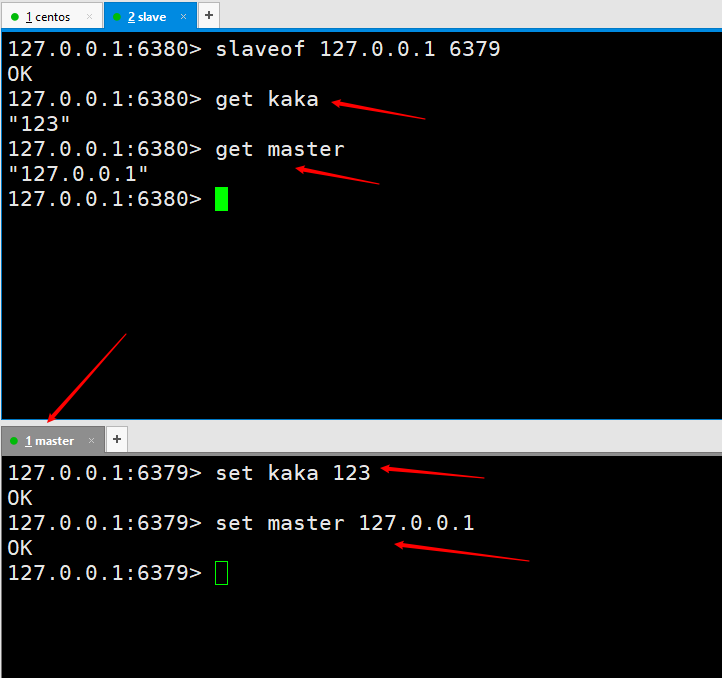
slaveof 127.0.0.1 6379としてコマンドを実行します。実行後、接続されたことを意味します。
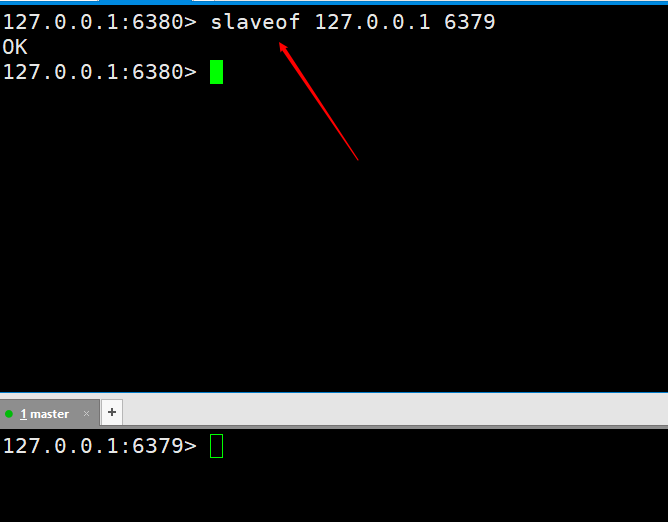
set kaka 123 と set master 127.0.0.1を実行すると、slave6380 ポートが正常に取得できます。これは、マスター/スレーブ レプリケーションが構成されたことを意味します。ただし、運用環境の実装で終わりではなく、その後、高可用性が達成されるまでマスター/スレーブ レプリケーションがさらに最適化されます。
# を有効にします
slaveof no oneを実行してマスター/スレーブ レプリケーションを切断する必要があります。
 #スレーブ ノードがマスター ノードから切断されたことはどこで確認できますか。マスター ノードのクライアントでコマンド ライン
#スレーブ ノードがマスター ノードから切断されたことはどこで確認できますか。マスター ノードのクライアントでコマンド ライン
を入力して、
を表示します。
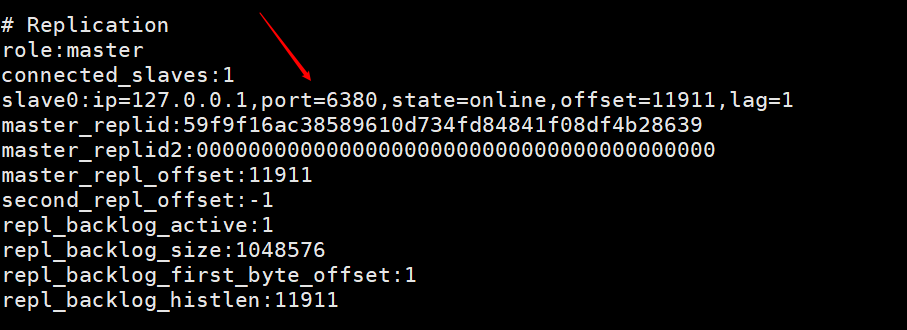
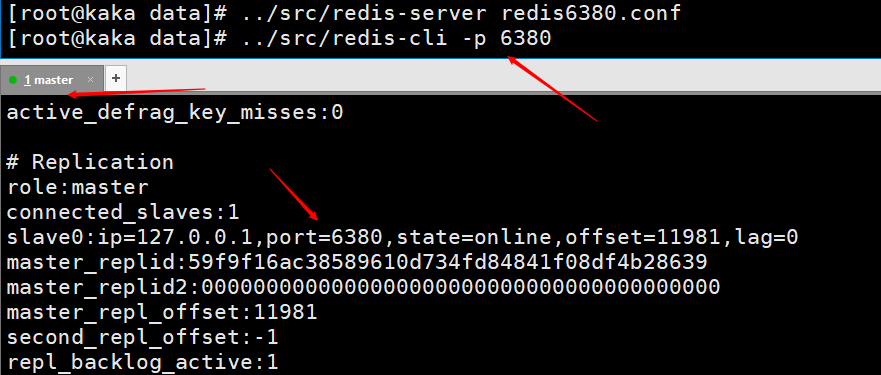
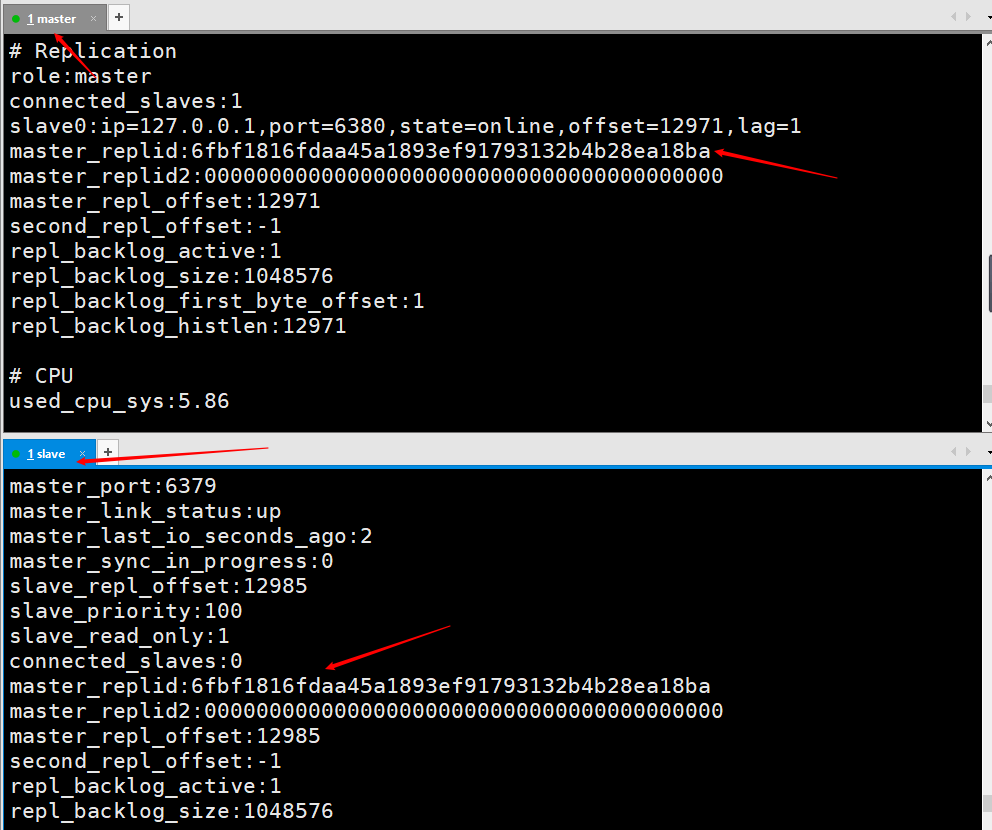
この図は、クライアント コマンド ラインを使用してスレーブ ノードを使用してマスター ノードに接続した後、マスター ノードのクライアントでinfoと入力して出力された情報を示しています。スレーブ0に関する情報。
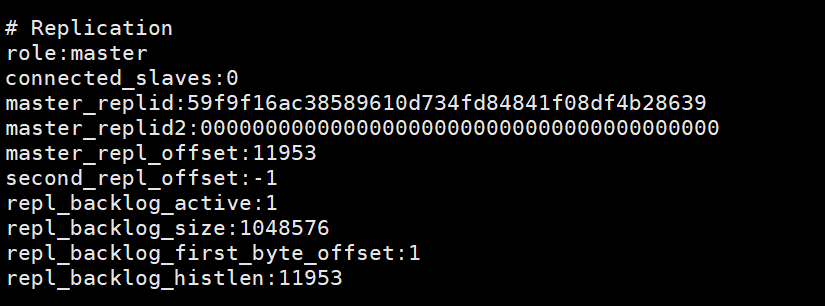
この画像は、スレーブ ノードがslaveof no oneinfoを実行した後、マスター ノードに印刷されます。 、スレーブ ノードがマスター ノードから切断されたことを示します。
redis-server redis6380.conf
##スレーブ ノードが再起動されると、マスター ノードでスレーブ ノードの接続情報を直接表示できます。
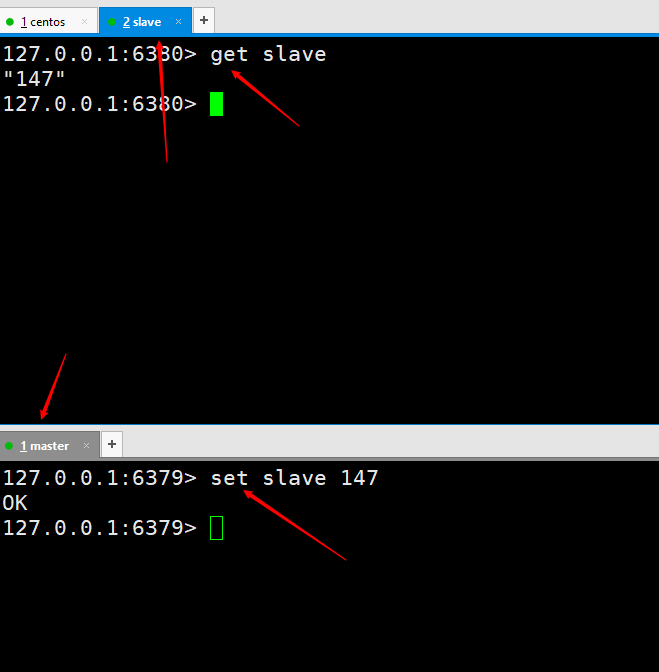
# テスト データ、マスター ノードによって書き込まれたものは、スレーブ ノードによって自動的に同期されます。
redis-server --slaveof host portを実行します。
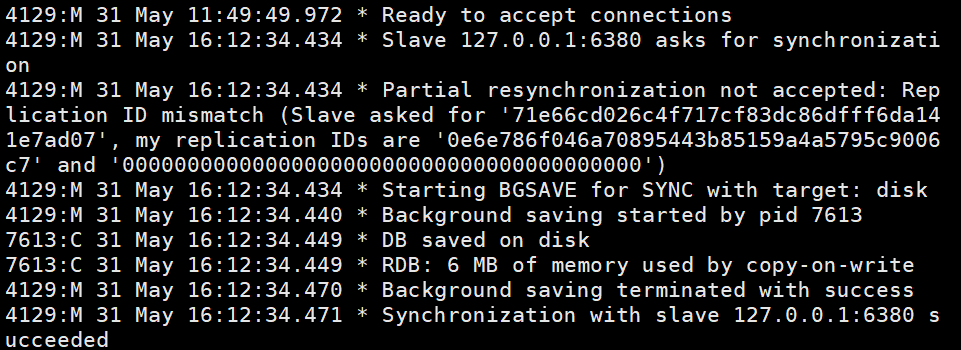
#これは、マスターノードとRDBスナップショットストレージの接続情報を含むスレーブノードの情報です。
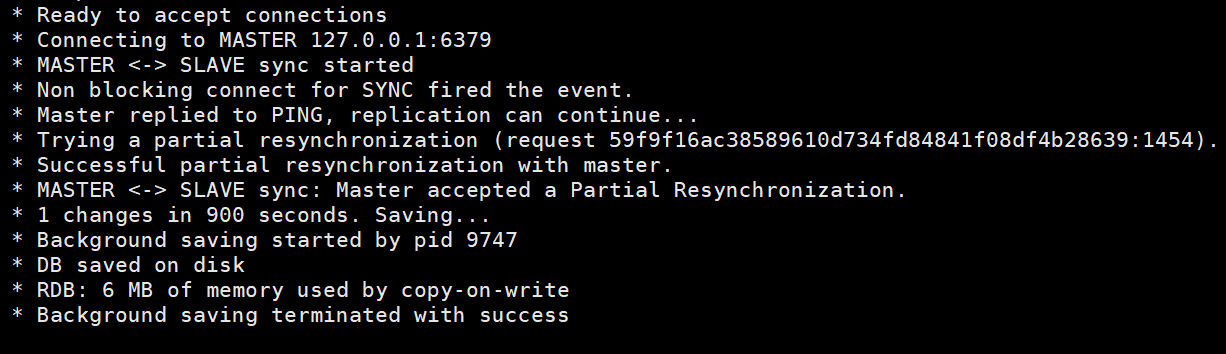
マスター/スレーブ レプリケーションの完全なワークフローは、次の 3 つの段階に分かれています。各セグメントには独自の内部ワークフローがあるため、3 つのプロセス プロセスについて説明します。
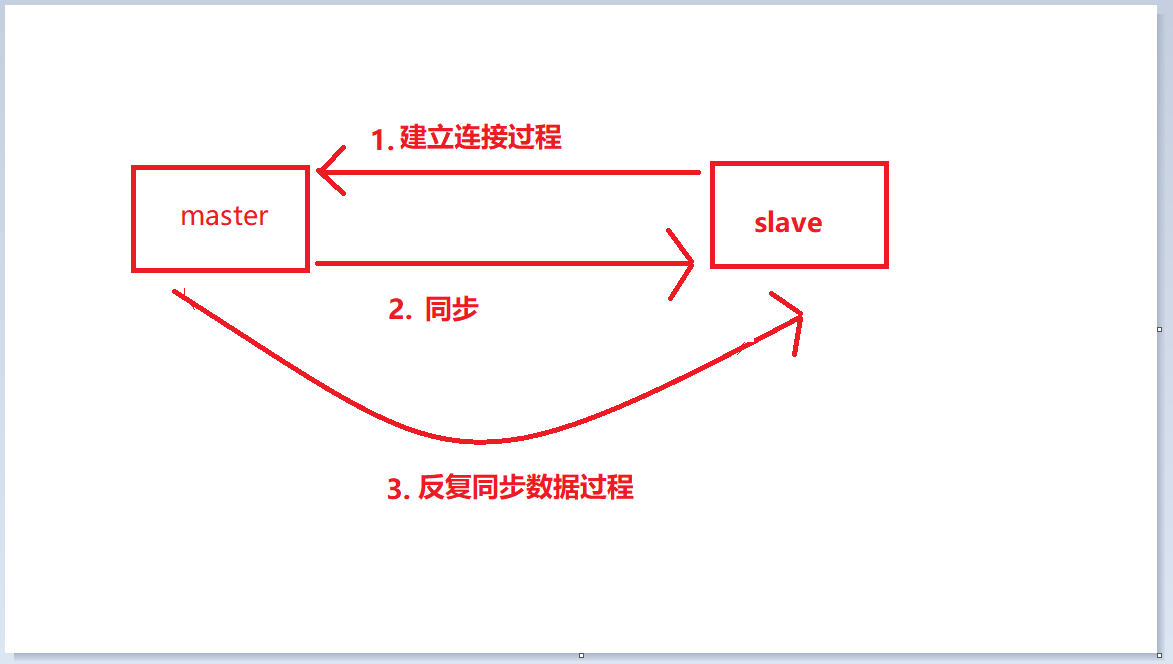
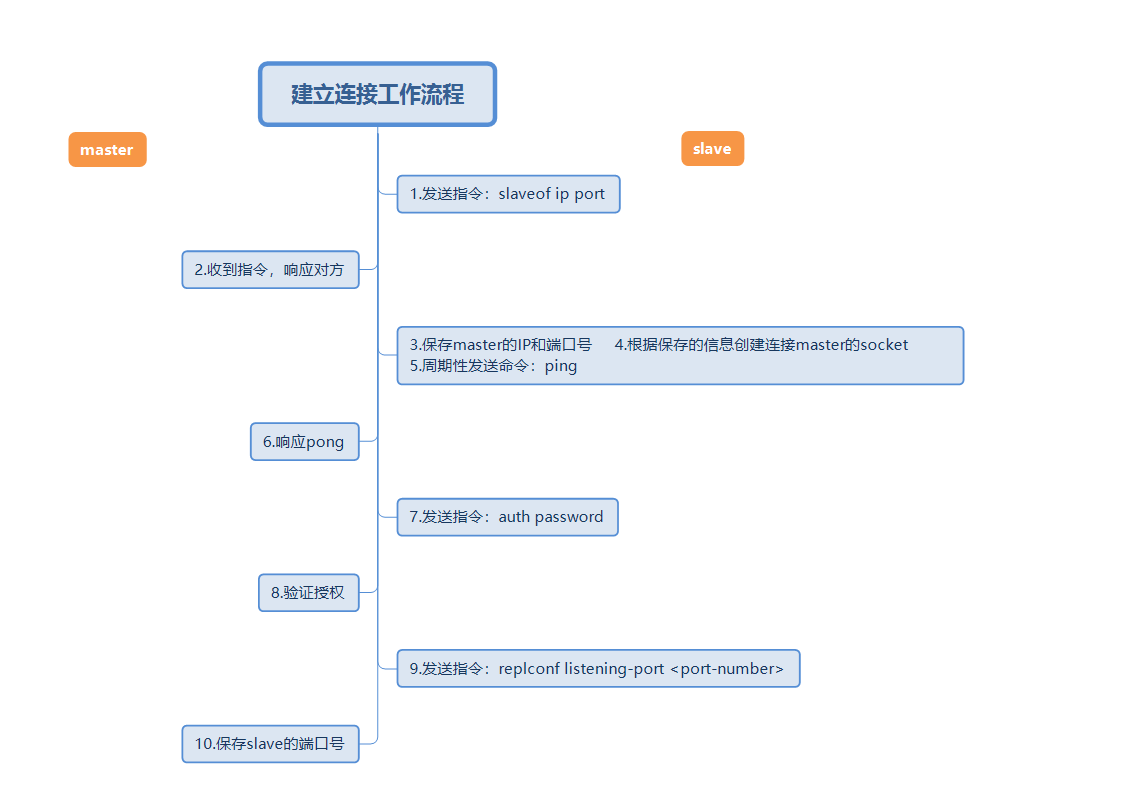
接続を確立するプロセス中に、スレーブ ノードはマスターのアドレスとポートを保存し、マスター ノード マスターはスレーブ ノード スレーブのポートを保存します。
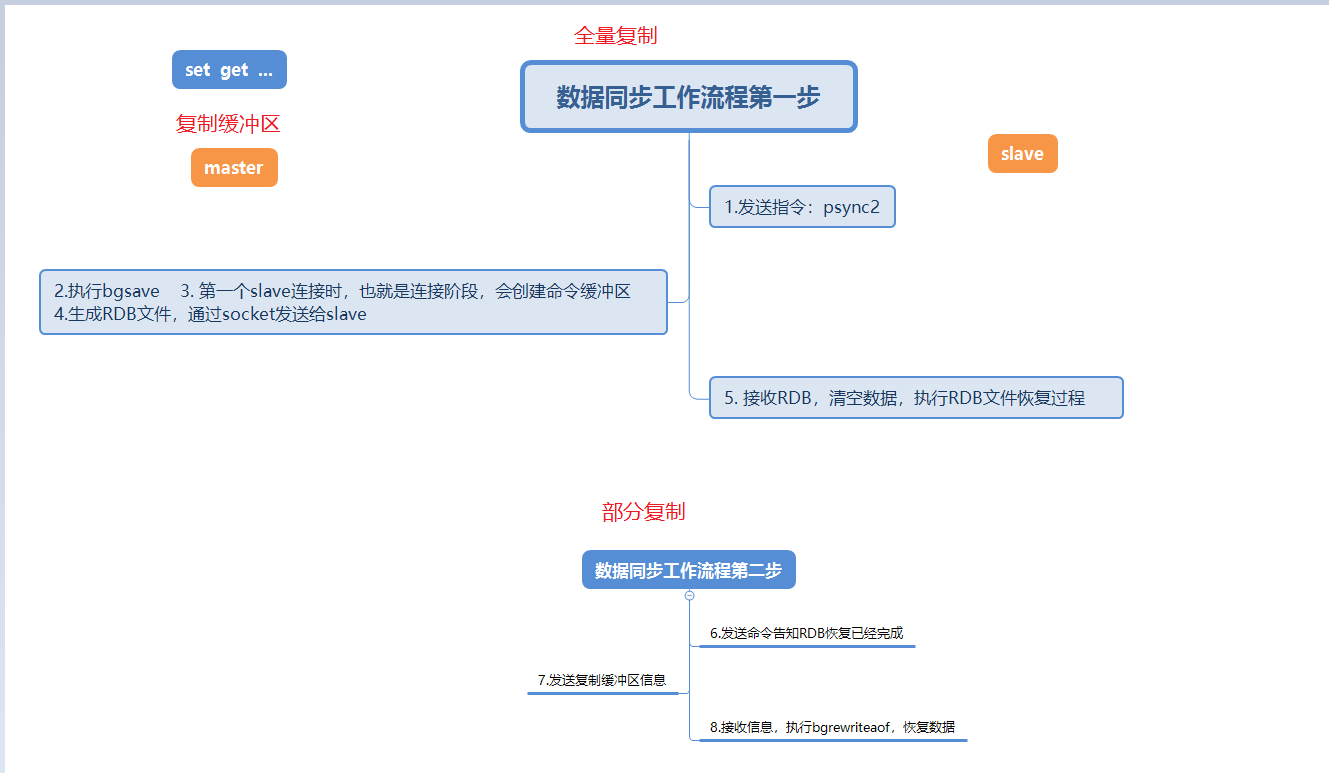
この図では、スレーブ ノードがマスター ノードに初めて接続するときのデータ同期プロセスを詳しく説明します。
マスター データベースが変更され、マスター サーバーとスレーブ サーバーのデータが不整合になった場合、マスターとスレーブのデータが同期されて一貫性が保たれます。このプロセスはコマンド伝播と呼ばれます。
#マスタは受信したデータ変更コマンドをスレーブに送信し、スレーブはコマンド受信後にコマンドを実行してマスタとスレーブのデータを整合させます。
コマンド伝播フェーズ中の部分レプリケーション

psync ? 1 pync runid offsetデータを要求するために対応するrunidを見つけます。ただし、ここでは、スレーブ ノードが初めて接続するとき、マスター ノードのrunid と offsetをまったく知らないと考えることができます。最初に送信されるコマンドはpsync ですか? 1は、マスターノードのすべてのデータが必要であることを意味します。psync runid offset2に戻って完全レプリケーションの実行を続行します。ここでの runid の不一致は、スレーブ ノードの再起動によってのみ発生する可能性があります。この問題は後で解決されます。オフセット (オフセット) の不一致は、レプリケーション バックログ バッファ オーバーフローによって発生します。 runid または offset チェックに合格し、スレーブ ノードのオフセットがマスター ノードのオフセットと同じである場合、そのオフセットは無視されます。 runid または offset チェックに合格し、スレーブ ノードのオフセットがオフセットと異なる場合、CONTINUE offset (このオフセットはマスター ノードに属します) が送信され、スレーブ ノードのオフセットからマスター ノードのオフセットへのデータが送信されます。レプリケーション バッファはソケット経由で送信されます。1 ~ 4 は完全コピー、5 ~ 8 は部分コピー
コマンド伝播段階では、マスターノードとスレーブノードは常に情報を交換する必要があります。メンテナンス用のハートビート メカニズムを切り替えて使用し、マスター ノードとスレーブ ノード間の接続をオンラインに保ちます。
#ハートビート フェーズに関する注意事項
データの安定性を確保するために、マスター ノードはドロップ数または遅延が大きすぎます。すべての情報の同期は拒否されます。min-slaves-to-write 2
min-slaves-max-lag 8
これ2 つのパラメーターは、スレーブ ノードが 2 つだけ残っていること、またはスレーブ ノードの遅延が 8 秒を超える場合、マスター ノードはマスター機能を強制的にオフにしてデータ同期を停止することを示します。
#それでは、マスター ノードがハングアップしたスレーブ ノードのデータと遅延時間を知っている場合はどうなるでしょうか。ハートビート メカニズムでは、スレーブは perlconf ack コマンドを毎秒送信します。このコマンドには、オフセット、スレーブ ノードの遅延時間、およびスレーブ ノードの数が含まれます。
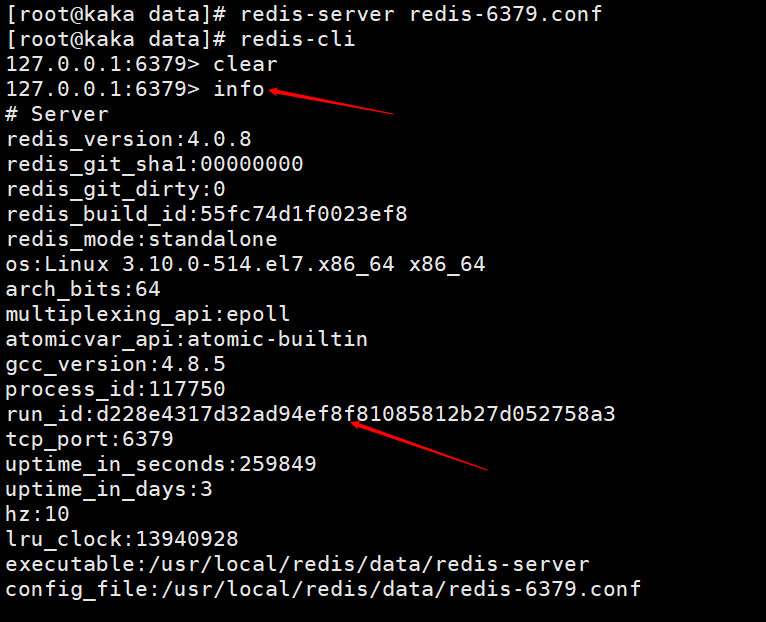
まず、この実行 ID が何であるかを見てみましょう。info コマンドを実行すると確認できます。上記の起動ログ情報を見ると、このこともわかります。
 #
#
Redis は起動時にランダム ID を自動的に生成します (ID は起動するたびに異なることに注意してください)。これは 40 個のランダムな 16 進文字列で構成され、Redis ノードを一意に識別するために使用されます。 。
マスター/スレーブ レプリケーションが最初に開始されると、マスターはその runid をスレーブに送信し、スレーブはマスターの id を保存します。info コマンドを使用できます。表示するには
切断して再接続すると、スレーブはこの ID をマスターに送信し、スレーブによって保存された runid がマスターの現在の runid と同じである場合、マスターは部分レプリケーションの使用を試みます (このブロックを正常にコピーできるかどうかのもう 1 つの要素はオフセットです)。スレーブによって保存された runid がマスターの現在の runid と異なる場合、完全コピーが直接実行されます。
コピー バッファ バックログは先入れ先出しキューです。ユーザーストレージ データを収集するためのマスターコマンドレコード。コピーバッファのデフォルトのストレージ容量は 1M です。
設定ファイルのrepl-backlog-size 1mbを変更してバッファ サイズを制御できます。この比率は独自のサーバーに応じて変更できます。ここでは約 30% が予約されています。
コピー バッファには正確に何が格納されているのでしょうか?
コマンドをset name kakaとして実行すると、永続化ファイルを表示して
を表示できます。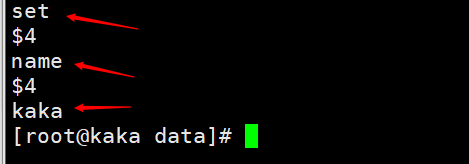
この場合、コピー バックログ バッファーは、バイトごとに区切られた永続データが保存されたものであり、各バイトには独自のオフセットがあります。このオフセットはコピー オフセット (オフセット) でもあります。

#では、なぜコピー バッファーのバックログによって全量コピーが発生する可能性があると言われるのでしょうか。それ###############
コマンド伝播フェーズでは、マスター ノードは収集したデータをレプリケーション バッファに保存し、それをスレーブ ノードに送信します。ここで問題が発生し、マスターノード上のデータ量が瞬間的に非常に多くなり、レプリケーションバッファのメモリを超えると、一部のデータが圧迫され、マスターノードとスレーブ間でデータの不整合が発生します。ノード。完全なコピーを作成するには。バッファサイズが適切に設定されていない場合、スレーブノードは常にフルコピー、データクリア、フルコピーを繰り返す無限ループを引き起こす可能性があります。
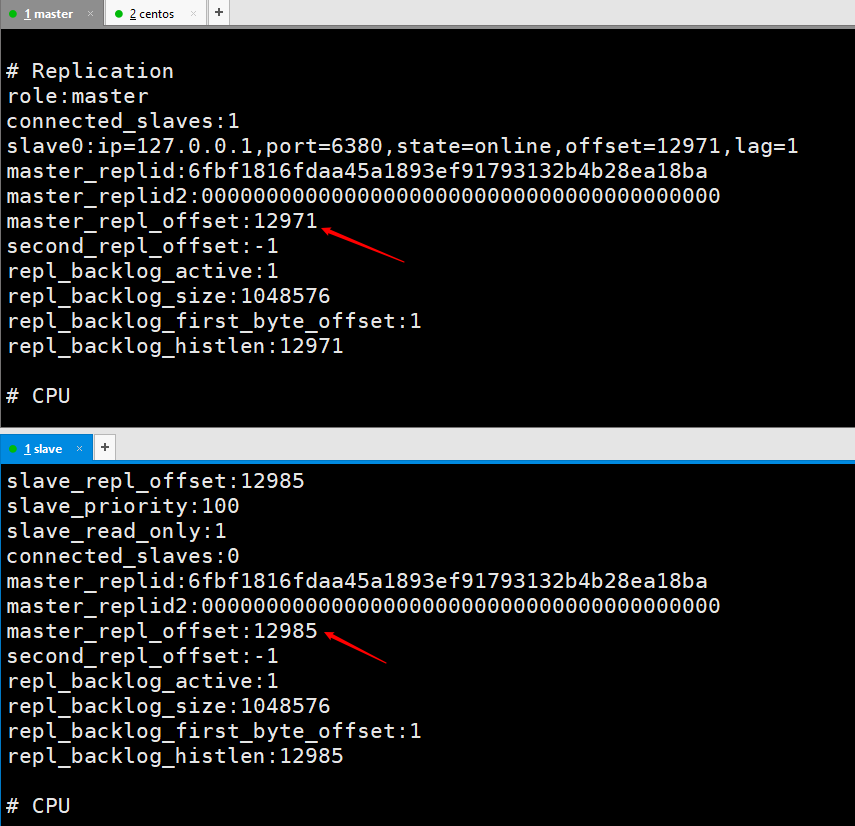
マスターノードのレプリケーションオフセットは、スレーブノードにレコードを 1 回送信し、スレーブノードはレコードを 1 回受信します。
は、情報を同期し、マスター ノードとスレーブ ノードの違いを比較し、スレーブが切断されたときにデータ使用量を復元するために使用されます。
#この値は、コピー バッファー バックログからのオフセットです。
##1. マスター ノードの再起動の問題 (内部最適化)
マスター ノードが再起動すると、runid の値が変更され、すべてのスレーブ ノードで完全なレプリケーションが実行されます。
この問題を考慮する必要はありません。システムがどのように最適化されるかを知る必要があるだけです。
マスター/スレーブ レプリケーションが確立された後、マスター ノードはマスター レプリッド変数を作成します。生成された戦略は runid と同じで、長さは 41 です。ビットと 40 ビットの runid 長を持ち、スレーブ ノードに送信されます。
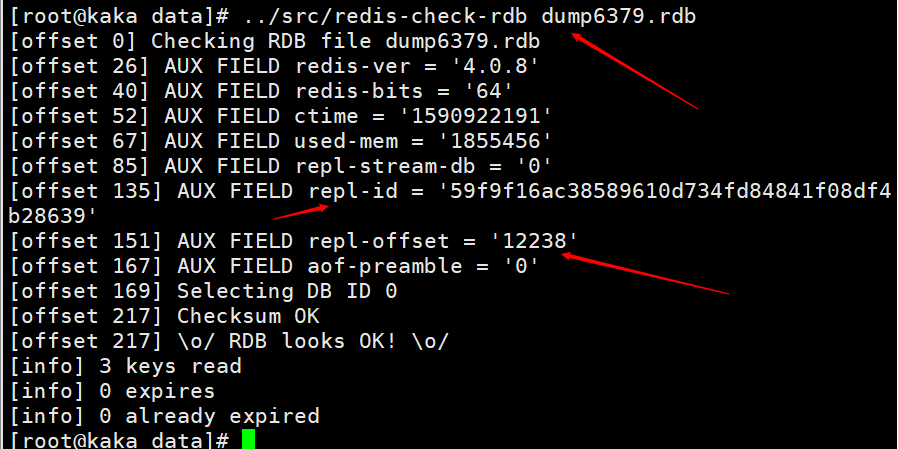
マスターノードで shutdown save コマンドを実行すると、RDB 永続化が実行され、runid と offset が RDB ファイルに保存されます。コマンド redis-check-rdb を使用して、この情報を表示できます。
解決策: レプリケーション バックログ バッファーのサイズを変更します: repl-backlog-size
セットアップの推奨事項: マスター ノードをテストします。スレーブノードの接続時間、1秒あたりにマスターノードが生成するコマンドの平均総数を取得します write_size_per_second
コピーバッファスペースの設定 = 2マスター-スレーブ接続時間マスター 1 秒あたりにノードによって生成されるデータの合計量
メインノードのCPUが原因 占有率が高すぎるか、スレーブノードが頻繁に接続されています。この状況の結果、バッファ、帯域幅、接続などを含む (ただしこれらに限定されない)、マスター ノードのさまざまなリソースが大幅に占有されます。
マスター ノードのリソースが大幅に占有されるのはなぜですか?
#ハートビート メカニズムでは、スレーブ ノードはコマンド replconf ack コマンドをマスター ノードに毎秒送信します。
スレーブ ノードは低速なクエリを実行し、大量の CPU を占有しました。
マスター ノードはレプリケーション タイミング関数 replicationCron を 1 秒ごとに呼び出しましたが、スレーブ ノードは長時間応答しませんでした。 。 ###############解決:############
スレーブ ノードのタイムアウト リリースを設定します
パラメータを設定します: repl-timeout
このパラメータのデフォルトは 60 秒です。 60 秒後、スレーブを解放します。
ネットワーク要因により、複数のスレーブ ノードのデータが不整合になります。この要因を回避する方法はありません。
この問題には 2 つの解決策があります:
最初のデータは、高度な設定を使用して構成する必要があります。一貫性 Redis サーバーは読み取りと書き込みの両方に 1 つのサーバーを使用します。この方法は少量のデータに限定されており、データの一貫性が高い必要があります。
2 番目はマスター/スレーブ ノードのオフセットを監視し、スレーブ ノードの遅延が大きすぎる場合、クライアントのスレーブ ノードへのアクセスは一時的にブロックされます。パラメータをslave-serve-stale-data yes|noに設定します。このパラメータが設定されると、info smileof などのいくつかのコマンドにのみ応答できるようになります。
この記事では主にマスター/スレーブ レプリケーションとは何か、マスターの 3 つの主要な側面について説明します。 -slave replication: ステージ、ワークフロー、および部分レプリケーションの 3 つのコア コンポーネント。コマンド伝播フェーズ中のハートビート メカニズム。最後に、マスター/スレーブ レプリケーションに関する一般的な問題について説明します。
以上がRedis のマスター/スレーブ レプリケーションの動作原理と一般的な問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



