Go の goroutine とチャネルについて話しましょう
- 1. チャネルを使用してタスクが終了するのを待ちます
- 2. スケジュールに選択を使用します
- 3. 概要
おすすめ関連記事: 「Go の同時プログラミングについて語る (1)」
1. チャネルを使用して、タスクが終了するまで待ちます
ユースケースは、最初の記事の 2 番目のセクションで書かれたコードのままですが、ここで必要な段落は 1 つだけです。
package mainimport ( "fmt" "time")func createWorker(id int) chan
ログイン後にコピー
ここに Kaka がオリジナルのソース コードを置きます。記事のリズムに従いたい場合は、それをエディターに入れて操作できます。
channelDemo 関数の最後にスリープが使用されていることがわかりますが、これはプログラム内でむやみに使用することはできません。
そういえば、ちょっとした話をさせてください。カカはインターネット上で睡眠を追加するコードを見つけました。
そこで、初心者のプログラマは、なぜこのスリープが追加されたのか理解できず、プロジェクト マネージャに尋ねました。プロジェクト マネージャは、上司がプログラムが遅いことに気づいたら、次のように言うと言いました。最適化を依頼すると、最適化するたびにこのスリープが削除されます。時間を短縮するだけです。私たちが何か良いことをしていると上司に感じてもらいましょう。
初心者は、理解できないコードにマークを付けてから、「プロジェクト マネージャーがここでゆっくり実行するように要求し、上司が最適化を要求したとき、コードは大幅に高速になりました。」
残念なことに、この文は上司に見られました。上司はコードを知りませんでしたが、テキストはまだ知っていました。そこで、プロジェクトマネージャーは立ち止まりました。
ということは、睡眠の大部分はテスト状態にあり、オンラインには絶対に表示されないということですね。このスリープをコード内で解決する必要があります。
那么大家在回忆一下,在这里为什么要加sleep呢?
发送到channel的数据都是在另一个goroutine中进行并发打印的,并发打印就会出现问题,因为根本不会知道什么时候才打印完毕。
所以说这个sleep就会为了应对这个不知道什么时候打印完的问题,给个1毫秒让进行打印。
这种做法是非常不好的,接下来看看使用一种新的方式来解决这个问题。
package mainimport ( "fmt")type worker struct { in chan int done chan bool}func createWorker(id int) worker { w := worker{ in: make(chan int), done: make(chan bool), } go doWorker(id, w.in, w.done) return w}func doWorker(id int, c chan int, done chan bool) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) done
ログイン後にコピー
ログイン後にコピー
将这些代码复制到你的本地,然后再来看一下都做了什么改动。
- まず、パラメーターの受け渡しの便宜のために、構造体ワーカー
- を作成し、以前のワーカー メソッドを doWorker
- に変更しました。このとき、 createWorkerメソッドの戻り値は、前のチャネルですが、作成された構造worker
- 以降、createWorkerメソッド内ですべてのチャネルが作成されます。そして、その構造体を使用してパラメータを doWorker に渡します。
- 最終的な戻り値は構造体です。
- 最後のステップは、channelDemo メソッドでデータを送信する 2 つのループでworkers[i] の値を受信することです。
##あなたは少しですか?混乱していますか?、これはどのようにして順番に行うことができますか? 並列の場合は、これら 10 個のワーカーを開いて、順番に印刷する必要があります。
この問題を今すぐ解決しましょう。タスクを送信して終了を待つ必要はありません。
最善の方法は、すべてを送信し、すべてが終了するのを待ってから終了することです。
package mainimport ( "fmt")type worker struct { in chan int done chan bool}func createWorker(id int) worker { w := worker{ in: make(chan int), done: make(chan bool), } go doWorker(id, w.in, w.done) return w}func doWorker(id int, c chan int, done chan bool) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) done
ログイン後にコピー
ログイン後にコピー
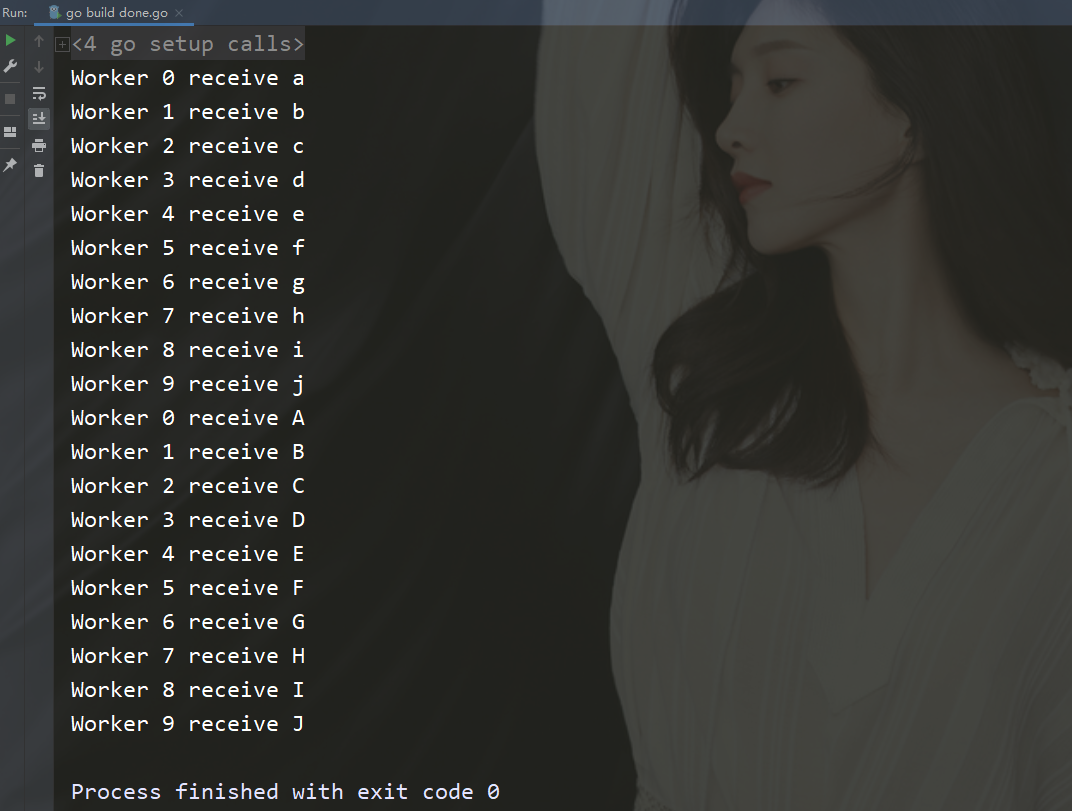
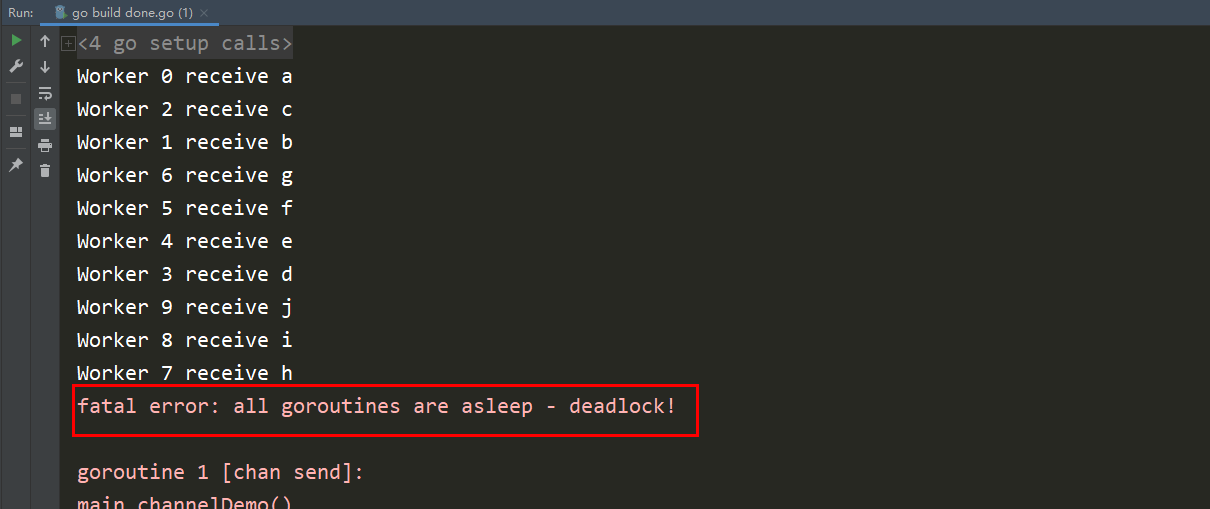
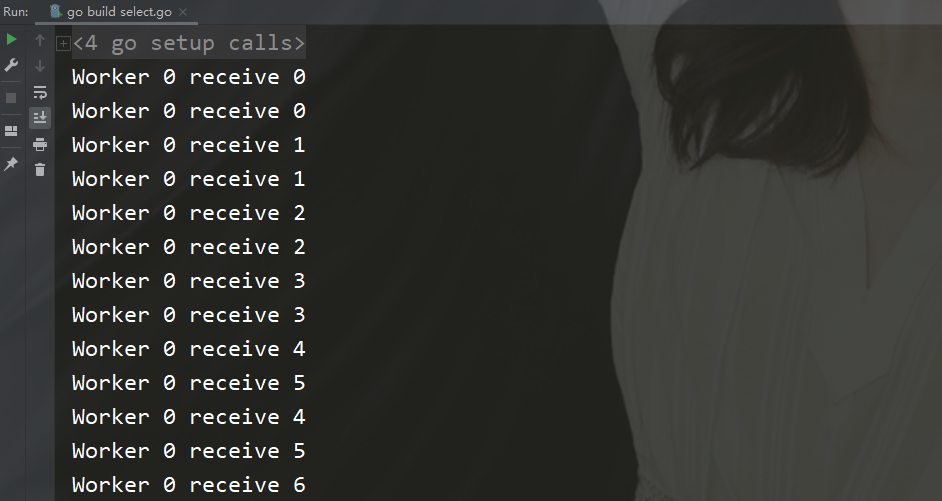
在这里再进行打印看一下结果,你会发现代码是有问题的。
为什么将小写的字母打印出来,而打印大写字母时发生了报错呢?
这个就要追溯到代码中了,因为我们代码本身就写的有问题。
还是回归到本文长谈的一个问题,那就是对于所有的channel有发送数据就必须有接收数据,如果没有接收数据就会报错。
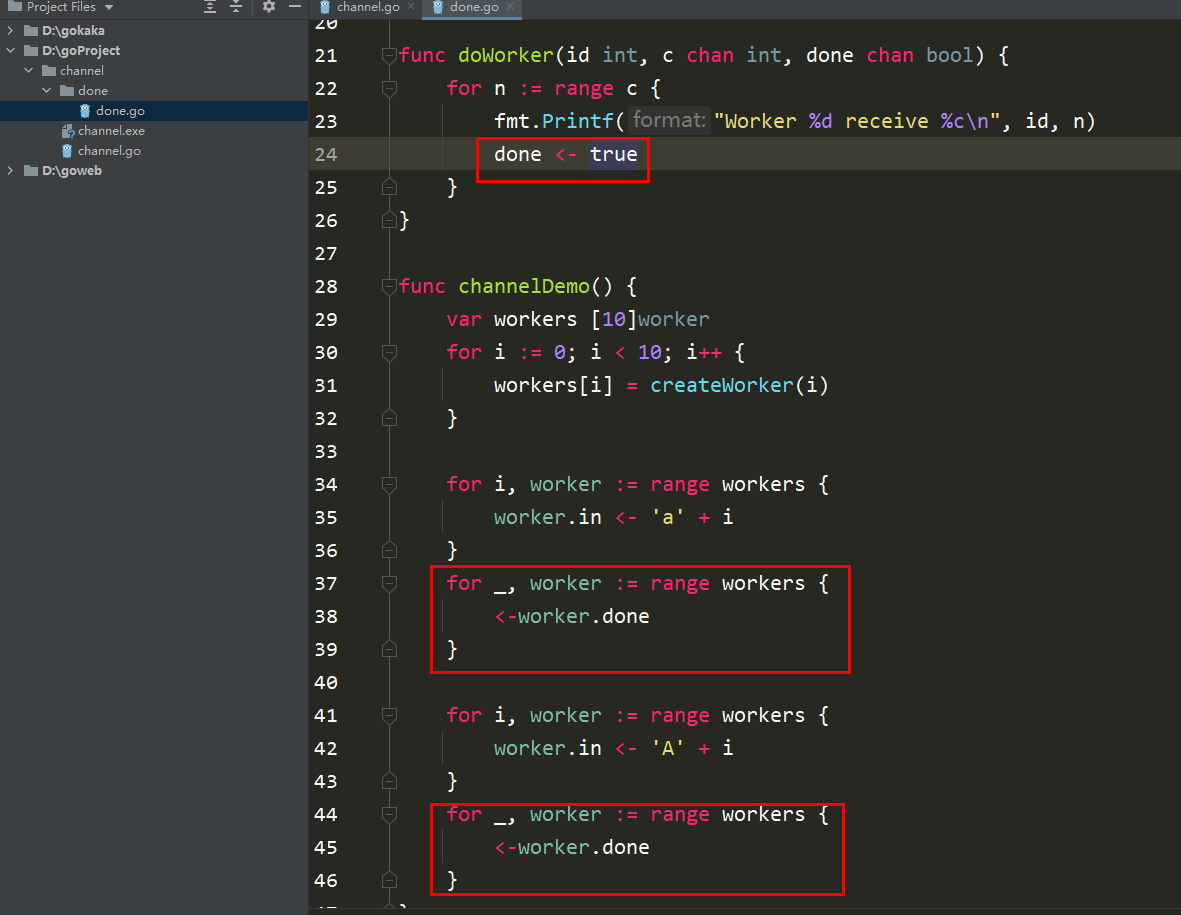
それでは、コード内で、ブロックはデータを送信するだけで、データを受信しないことがわかりますか?
問題は、チャネルに小文字を送信した後、doWorker メソッドに入り、完了することです。 true を送信しますが、done を受信するメソッドは後ろにあります。つまり、2 番目の大文字が送信されると、循環待機が送信されます。
この問題の解決も非常に簡単で、送信完了を同時に送信するだけです。
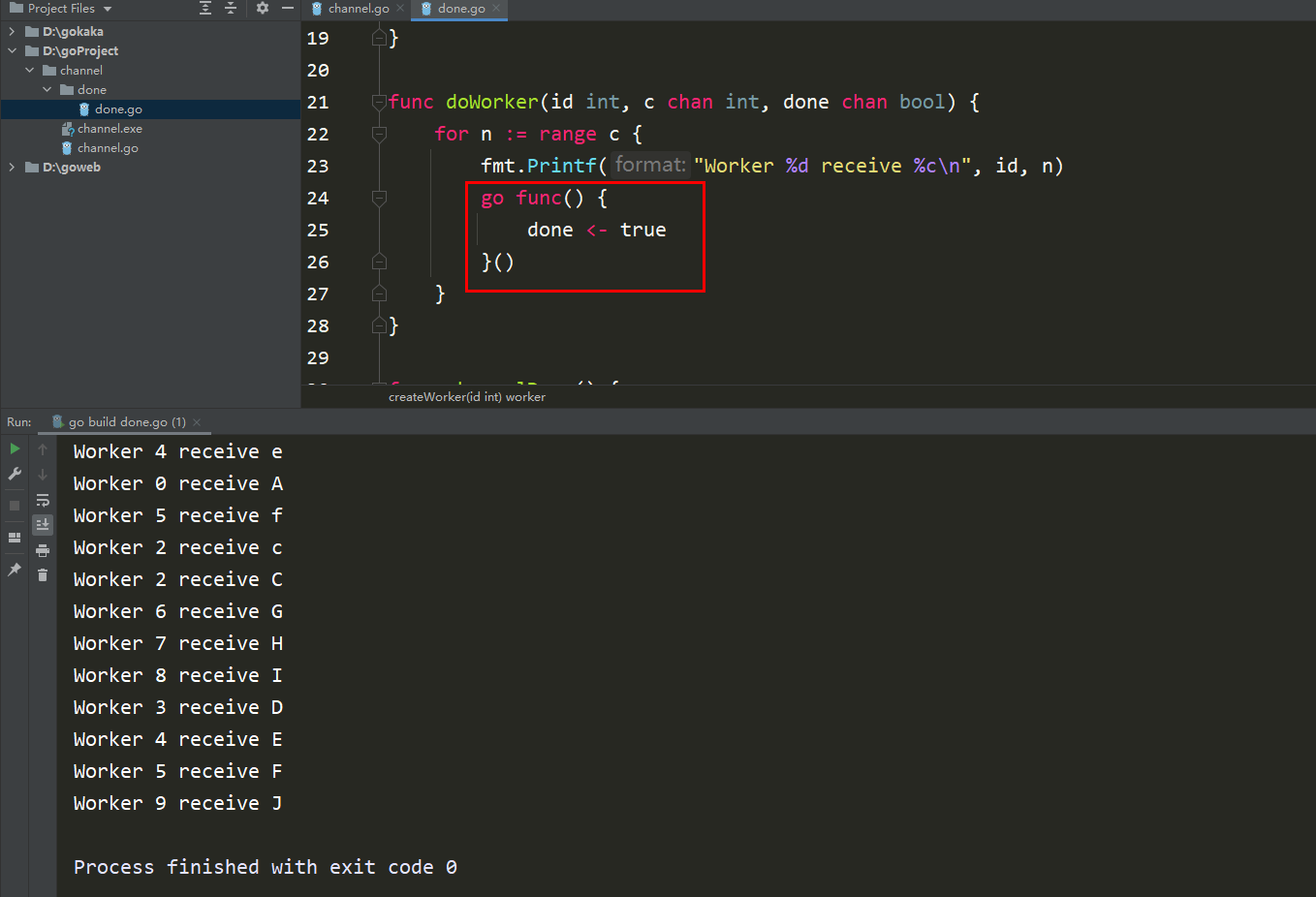
この記事で挙げたケースは通常のプロジェクトでは登場しないので、心配する必要はありません。
ここで挙げたケースは、チャネルの仕組みを皆さんにもっとよく知っていただくためのものです。
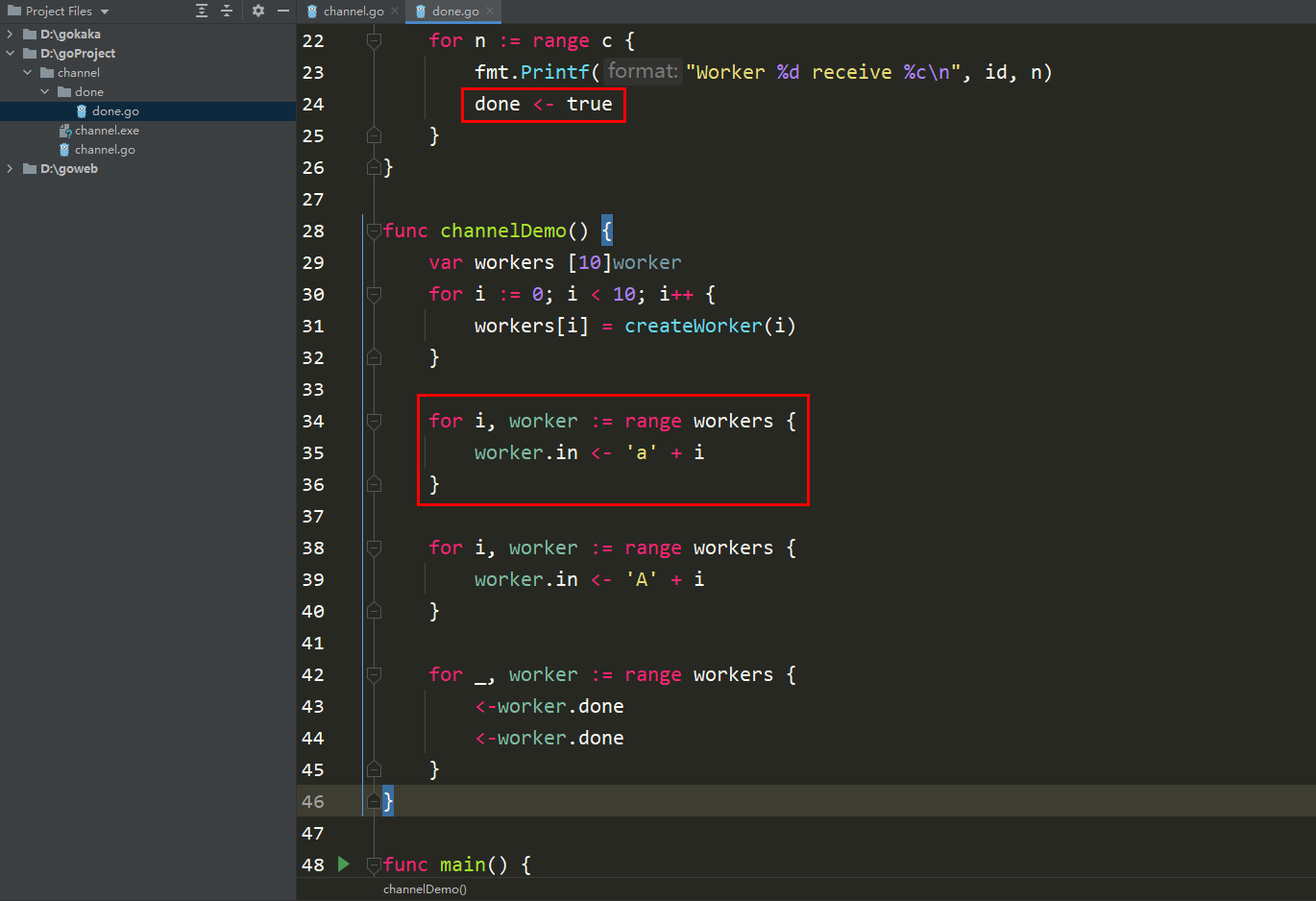
この解決策には別の解決策があります。コードを参照してください。
コードを以前の状態に戻し、送信された各レターの下で受信完了をループします。
このマルチタスク待機メソッドについては、これを実行できるライブラリが Go にあります。見てみましょう。
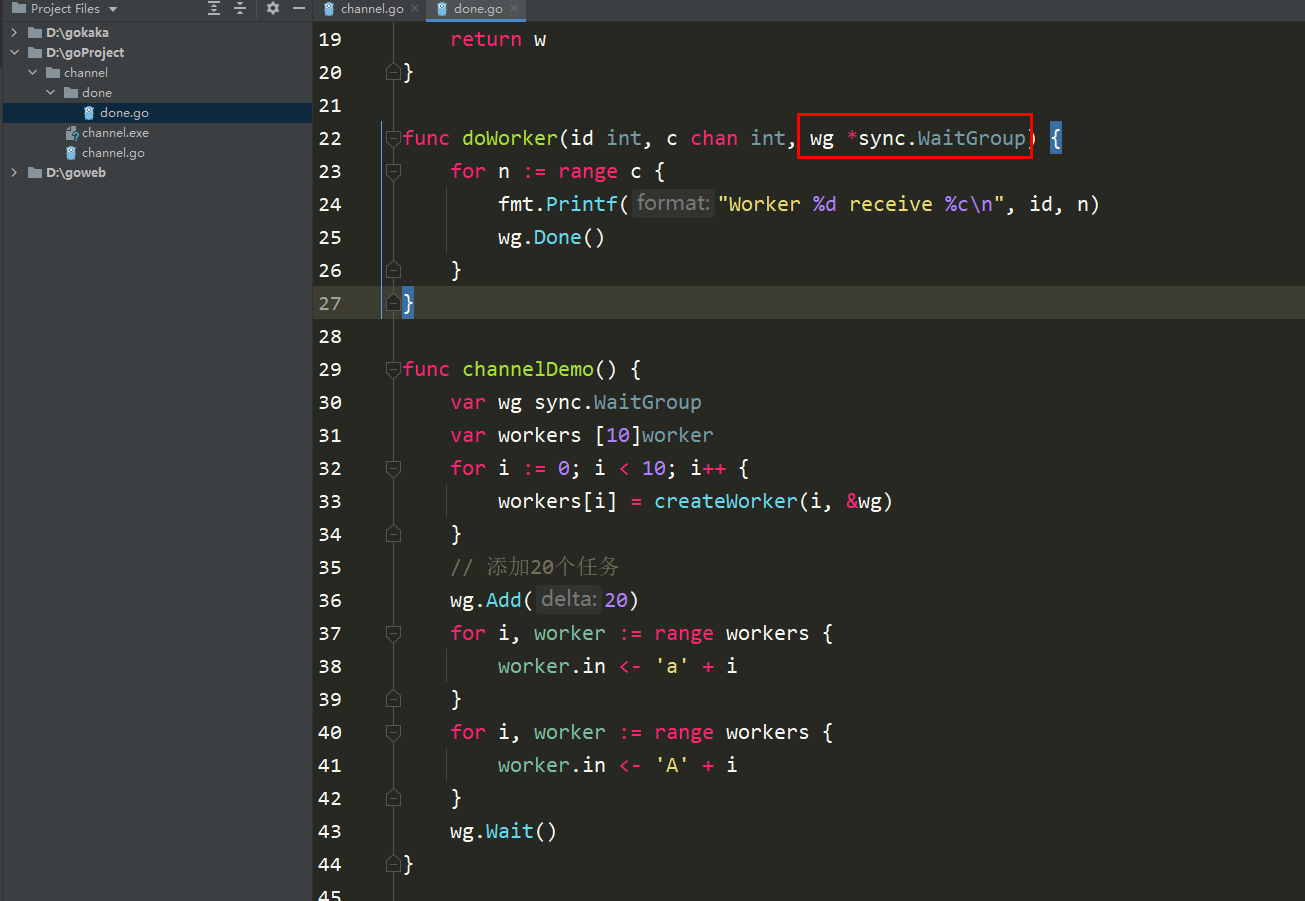
sync.WaitGroup の使い方を 1 つずつ紹介するつもりはありません。ソースコードの実装を見てください。
package mainimport ( "fmt" "sync")type worker struct { in chan int wg *sync.WaitGroup}func createWorker(id int, wg *sync.WaitGroup) worker { w := worker{ in: make(chan int), wg: wg, } go doWorker(id, w.in, wg) return w}func doWorker(id int, c chan int, wg *sync.WaitGroup) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) wg.Done() }}func channelDemo() { var wg sync.WaitGroup var workers [10]worker for i := 0; i
ログイン後にコピー
这份源码也是非常简单的,具体修改得东西咔咔简单介绍一下。
- 首先取消了
channelDemo这个方法中关于done的channel。
- 使用了
sync.WaitGroup,并且给createWorker方法传递sync.WaitGroup
- createWorker方法使用了 worker的结构体。
- 所以要先修改worker结构体,将之前的done改为wg *sync.WaitGroup即可
- 这样就可以直接用结构体的数据。
- 接着在doWorker方法中把最后一个参数done改为wg *sync.WaitGroup
- 将方法中的done改为wg.Done()
- 最后一步就是回到函数channelDemo中把任务数添加进去,然后在代码最后添加一个等待即可。
关于这块的内容先知道这么用即可,咔咔后期会慢慢的补充并且深入。
这块的代码看起来不是那么的完美的,接下来抽象一下。
这块代码有没有发现有点蹩脚,接下来我们使用函数式编程进行简单的处理。
package mainimport ( "fmt" "sync")type worker struct { in chan int done func()}func createWorker(id int, wg *sync.WaitGroup) worker { w := worker{ in: make(chan int), done: func() { wg.Done() }, } go doWorker(id, w) return w}func doWorker(id int, w worker) { for n := range w.in { fmt.Printf("Worker %d receive %c\n", id, n) w.done() }}func channelDemo() { var wg sync.WaitGroup var workers [10]worker for i := 0; i
ログイン後にコピー
这块代码看不明白就先放着,写的时间长了,你就会明白其中的含义了,学习东西不要钻牛角尖。
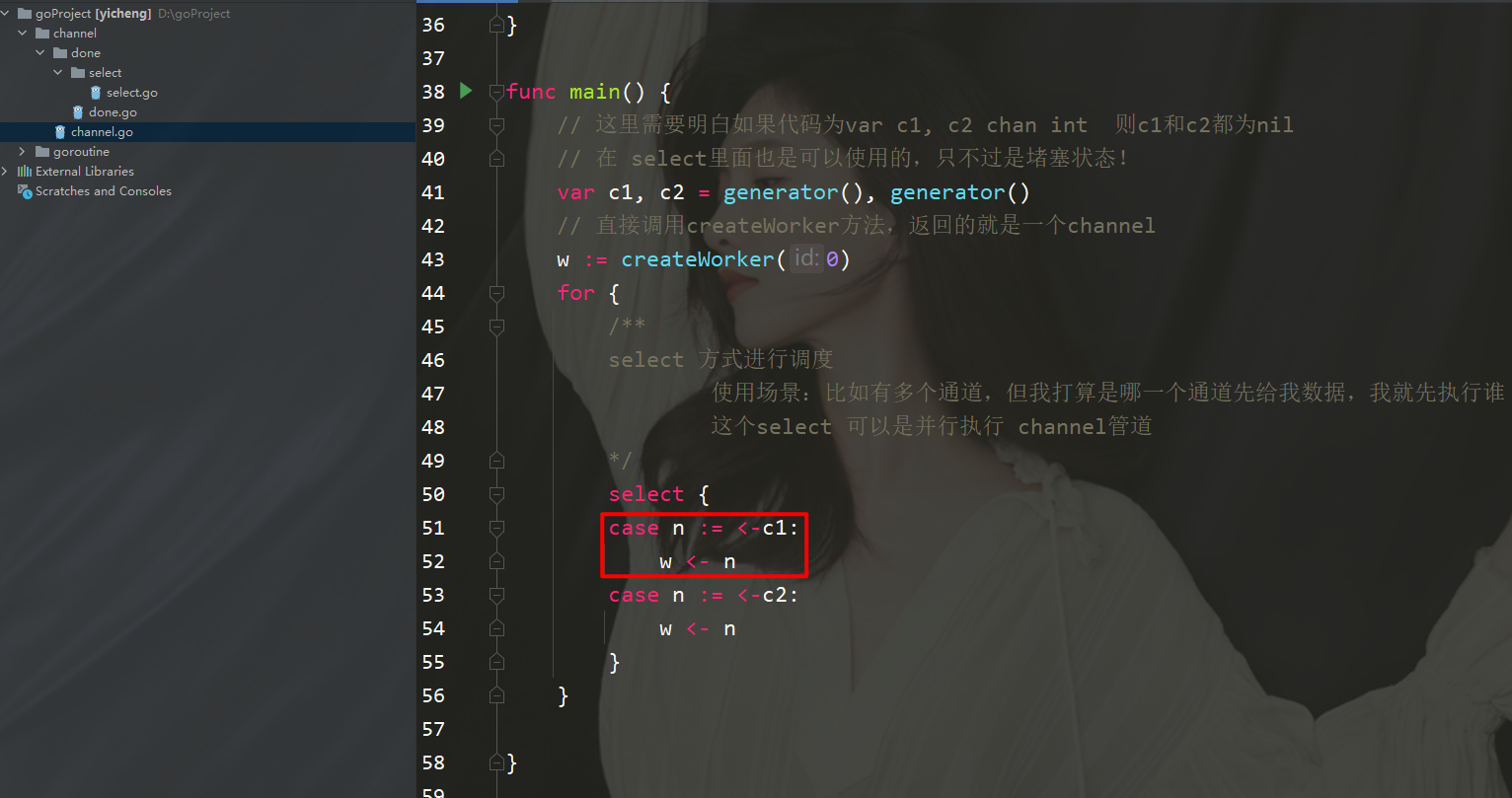
开头先给一个问题,假设现在有俩个channel,谁来的快先收谁应该怎么做?
package mainimport ( "fmt" "math/rand" "time")func generator() chan int { out := make(chan int) go func() { i := 0 for { // 随机睡眠1500毫秒以内 time.Sleep( time.Duration(rand.Intn(1500)) * time.Millisecond) // 往out这个channel发送i值 out
ログイン後にコピー
以上就是代码实现,代码注释也写的非常的清晰明了,就不过多的做解释了。
主要用法还是对channel的使用,在带上了一个新的概念select,可以在多个通道,那个通道先发送数据,就先执行谁,并且这个select也是可以并行执行channel管道。
在上文写的createWorker和worker俩个方法还记得吧!接下来就不在select里边直接打印了。
就使用之前写的俩个方法融合在一起,咔咔已将将源码写好了,接下来看一下实现。
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan
ログイン後にコピー
ログイン後にコピー
看到Go の同時プログラミングについて話しましょう (2)得知也是没有问题的。
这段代码虽然运行没有任何问题,但是这样有什么缺点呢?
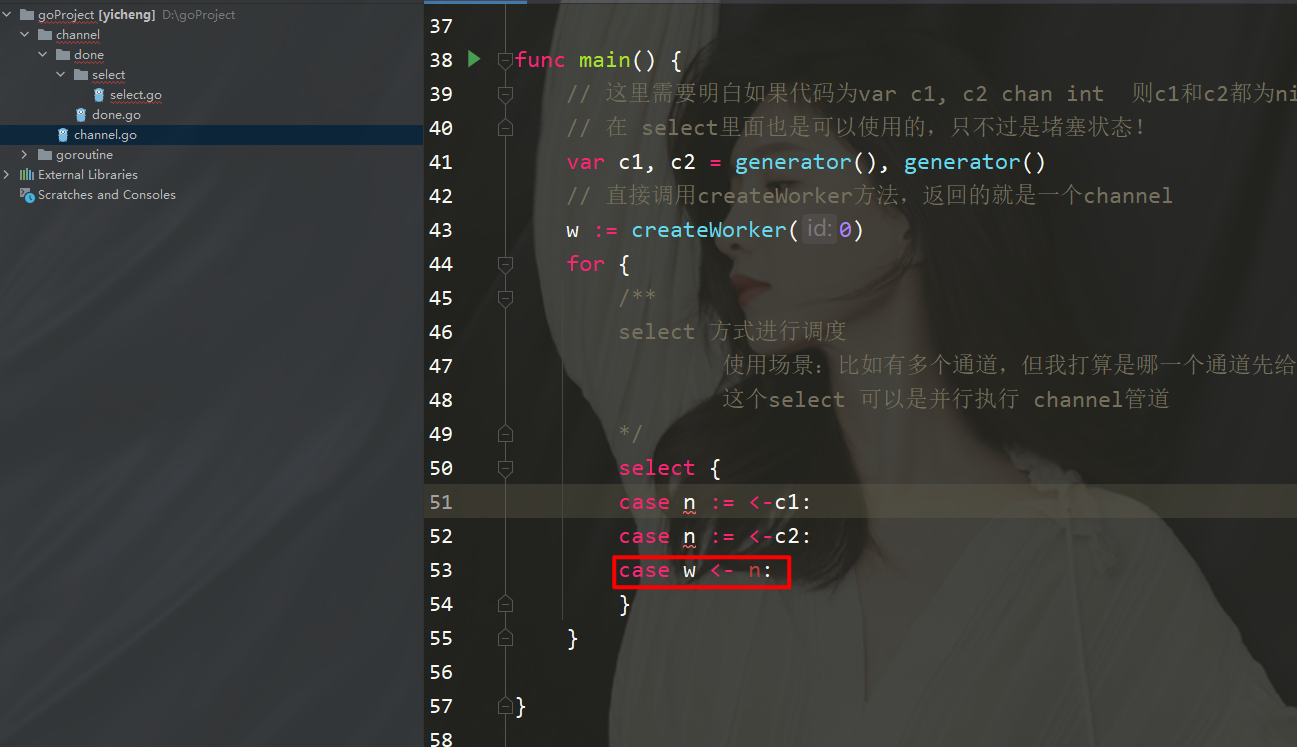
可以看下这段代码n := 这里先收了一个值,然后在下边代码w 又会阻塞住,这个是不好的。
这种模式是在select中既可以收数据,也可以发数据,目前这个程序是编译不过的,请看修改后的源码。
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan
ログイン後にコピー
ログイン後にコピー
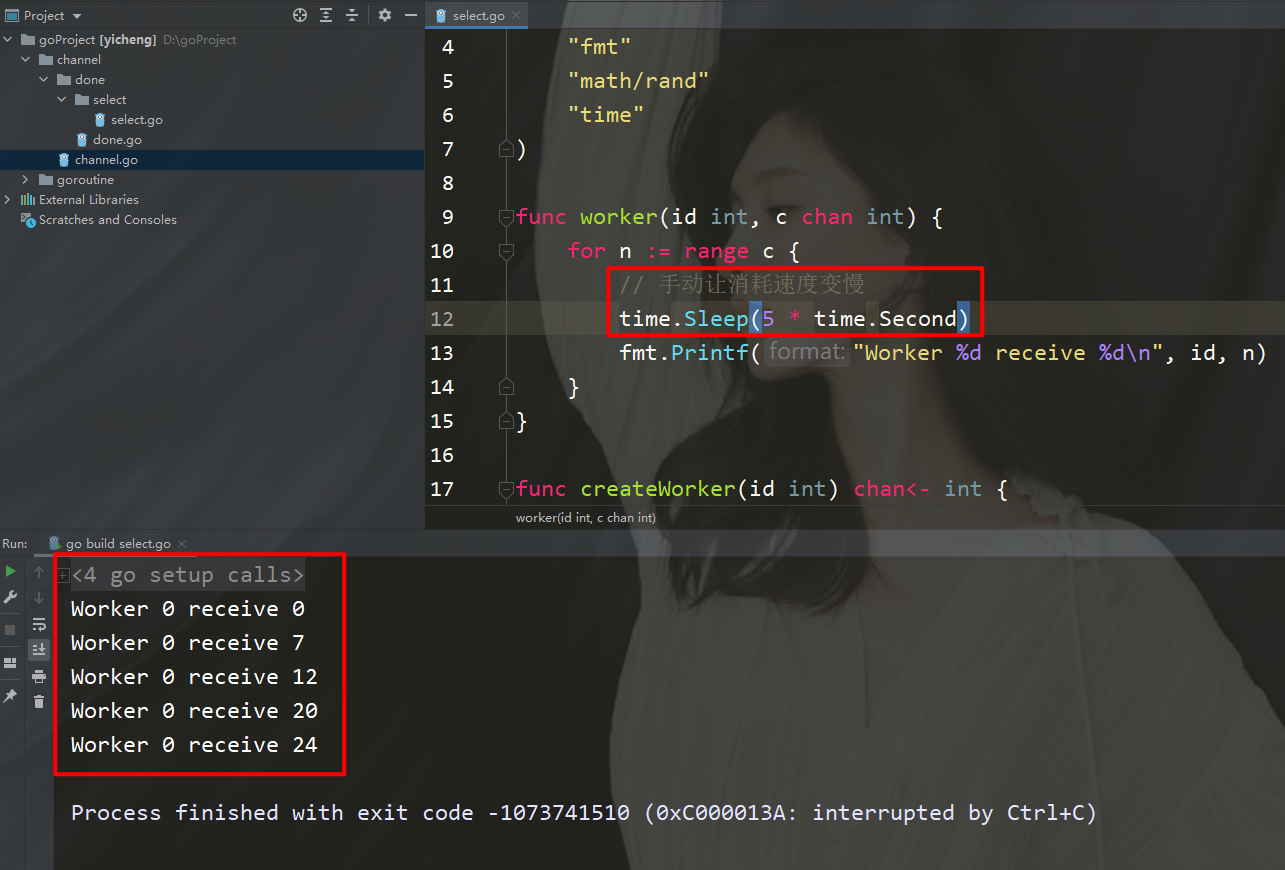
这个模式还是有缺点的,因为n收c1和c2的速度跟消耗的速度是不一样的。
假设c1的生成速度特别快,一下子生成了1,2,3。那么最后输出的数据有可能就只有3,而1和2就无法输出了。
这个场景也是非常好模拟的,只需要在打印的位置加上一点延迟时间即可。
此时你会看到Go の同時プログラミングについて話しましょう (2)为0、7、12、20…中间很多的数字都没来得急打印。
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(5 * time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
ログイン後にコピー
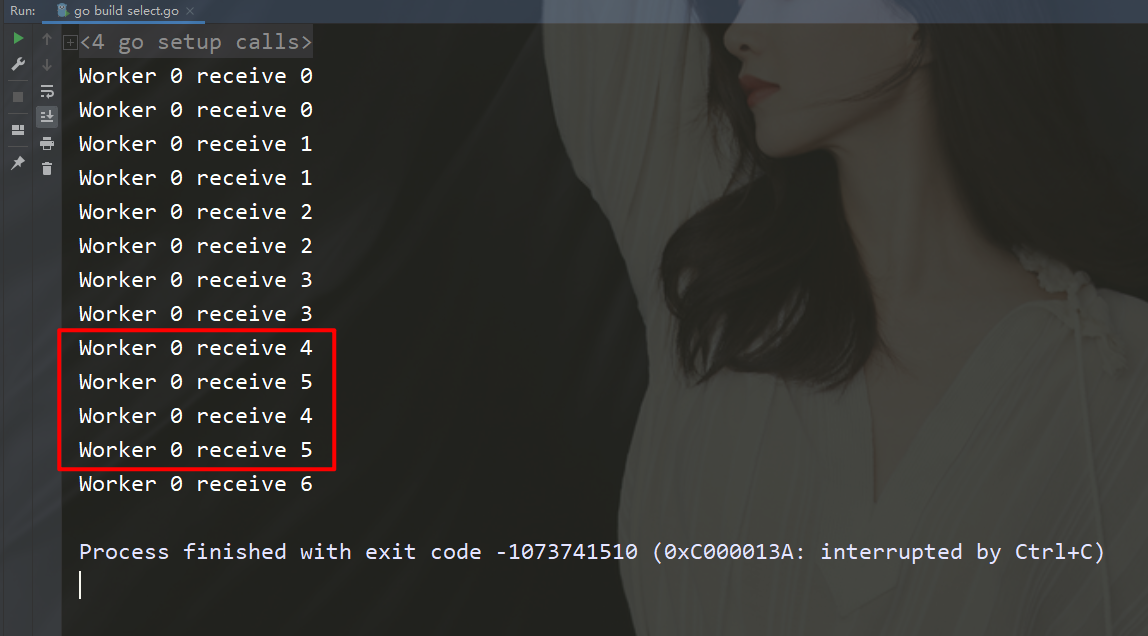
此时在来看Go の同時プログラミングについて話しましょう (2)。
Go の同時プログラミングについて話しましょう (2)没有漏掉数据,并且也是无序的,这样就非常好了。
上面的这个程序是退出不了的,我们想让它10s后就直接退出怎么做呢?
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
ログイン後にコピー
ログイン後にコピー
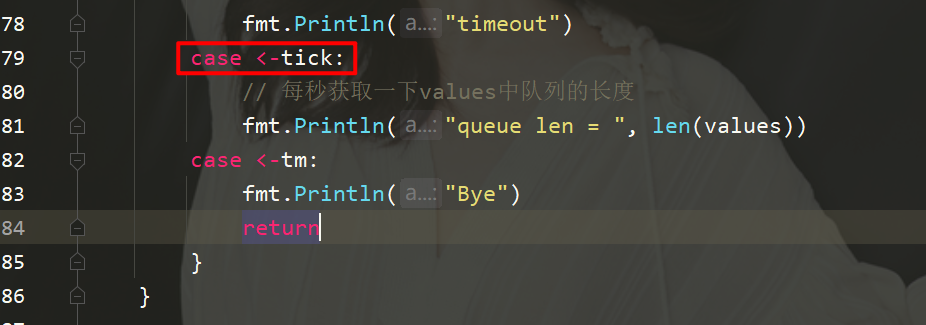
这里就是源码的实现,可以看到直接在select中是可以收到tm的值的,也就说如果到了10s,就会执行打印bye的操作。
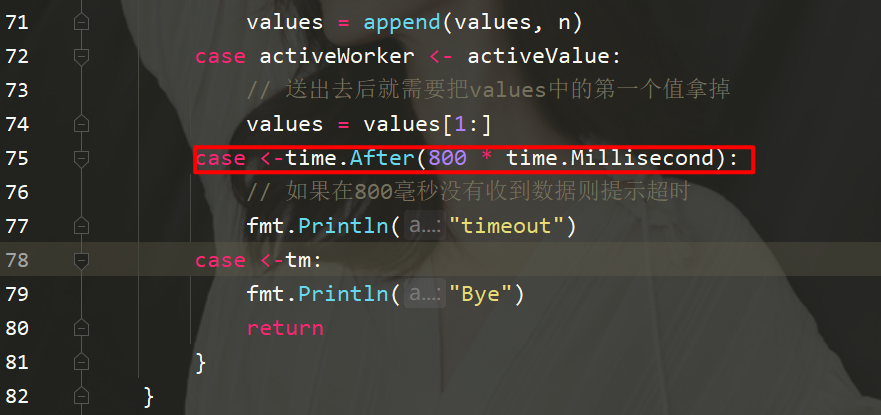
したがって、別の要件があります。つまり、データが 800 ミリ秒以内に受信されなかった場合は、他のことができるということです。
1 つの例から推測するというアイデアを使用して、この問題をどのように行うべきかを考えることができます。
#実はとても簡単で、ケースにタイマーをセットするだけです。
これについて述べたので、使用法を追加します
Go の同時プログラミングについて話しましょう (2) := time.Tick(time.Second)
は大文字と小文字の区別にも使用されます。
这样就可以每秒来显示一下values队列有多少数据。
这块的内容就结束了,最终给大家发一下源码,感兴趣的可以在自己的编辑器上试试看。
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
ログイン後にコピー
ログイン後にコピー
本文主要就是对于goroutine和channel的大量练习。
文中的案例,有可能会一时半会理解不了,是没有关系的,不用钻牛角尖的。
囲碁の大海を長く泳いでいると、自然と見えてくるものもある。
次の記事では、実用的な go 並行クローラー プロジェクトについて説明します。
#学習への粘り強さ、執筆への粘り強さ、そして共有への粘り強さは、カカがキャリア以来常に貫いてきた信念です。巨大なインターネット上の Kaka の記事が少しでもお役に立てれば幸いです。カカです、また会いましょう。
以上がGo の同時プログラミングについて話しましょう (2)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



