


この記事は、画像テキスト認識を実装するための Python コードを共有します。その内容は、困っている友人に役立つことを願っています
必要な画像を例に挙げます。認識するには

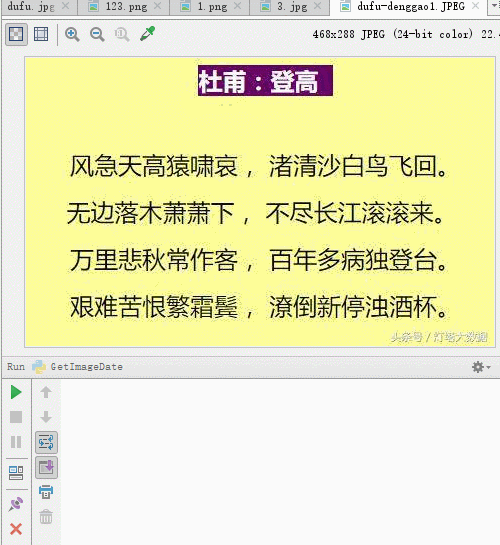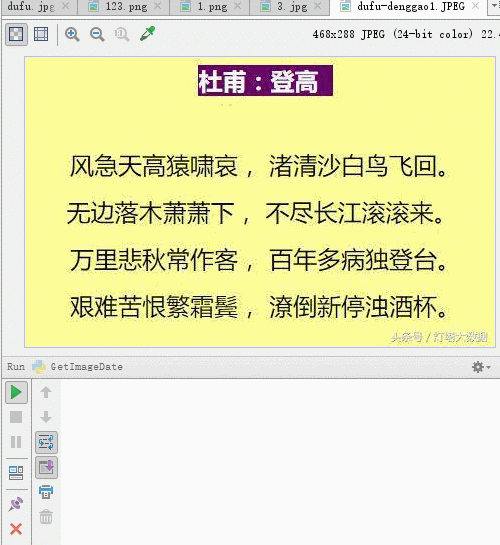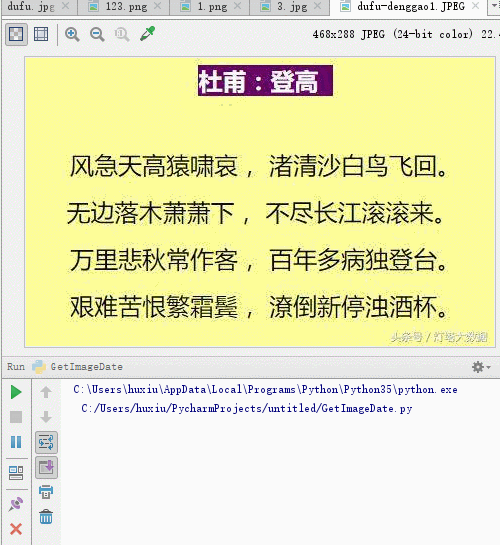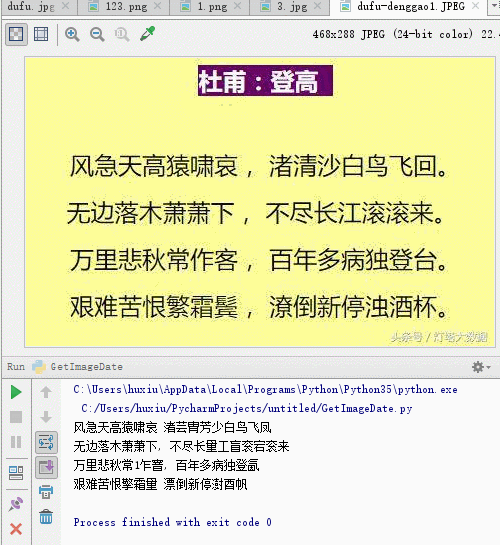 コードを実行した後の認識結果は、正しく認識されない単語がいくつかありますが、ほとんどの単語は認識できます。
コードを実行した後の認識結果は、正しく認識されない単語がいくつかありますが、ほとんどの単語は認識できます。
风急天高猿啸哀 渚芸胄芳少白鸟飞凤 无边落木萧萧下, 不尽长量工盲衮宕衮来 万里悲秋常1乍窨, 百年多病独登氤 艰难苦恨擎霜量 漂倒新停澍酉帆
- 1. コマンド ライン インストール
pip install PIL
pip install pytesseract
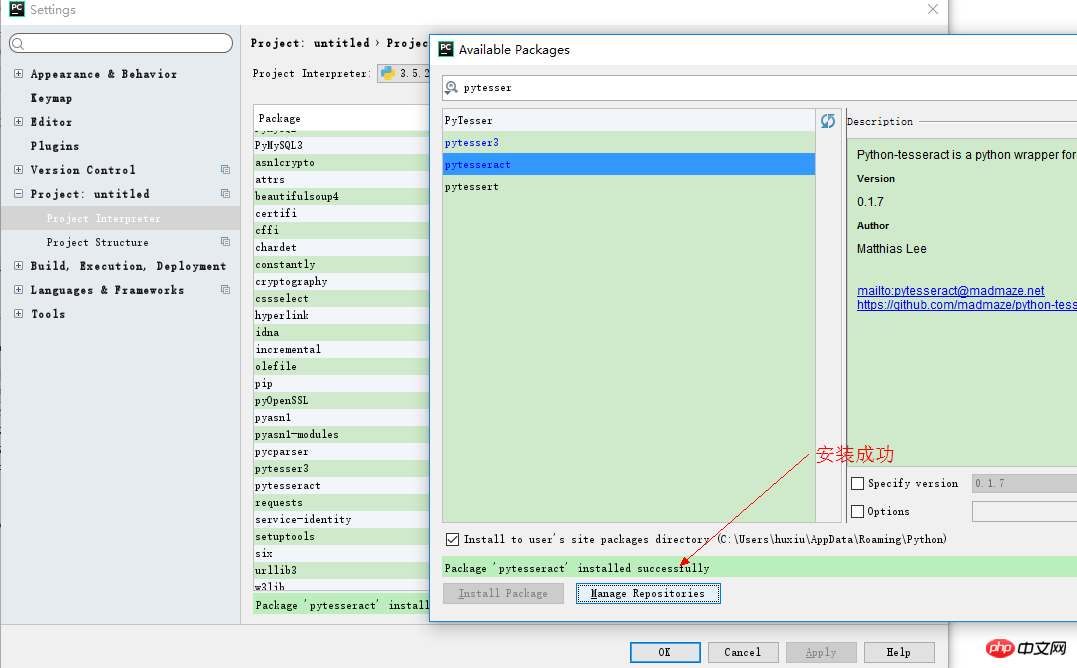
- 2. pycharm エディターを使用する場合は、pycharm を直接使用して迅速にインストールできます。
pycharm の設定ページで次の手順に従ってください
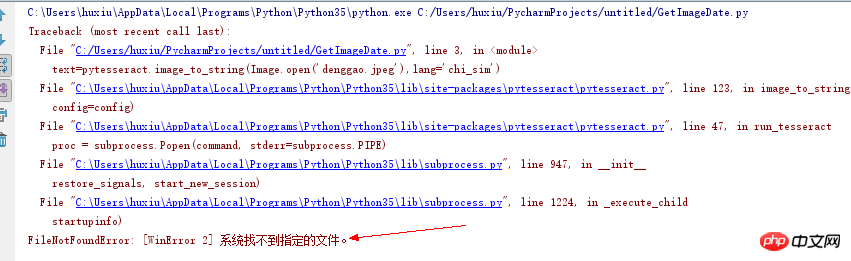
from PIL import Image import pytesseract text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text)
tesseract-ocr インストール パッケージと中国語パッケージ
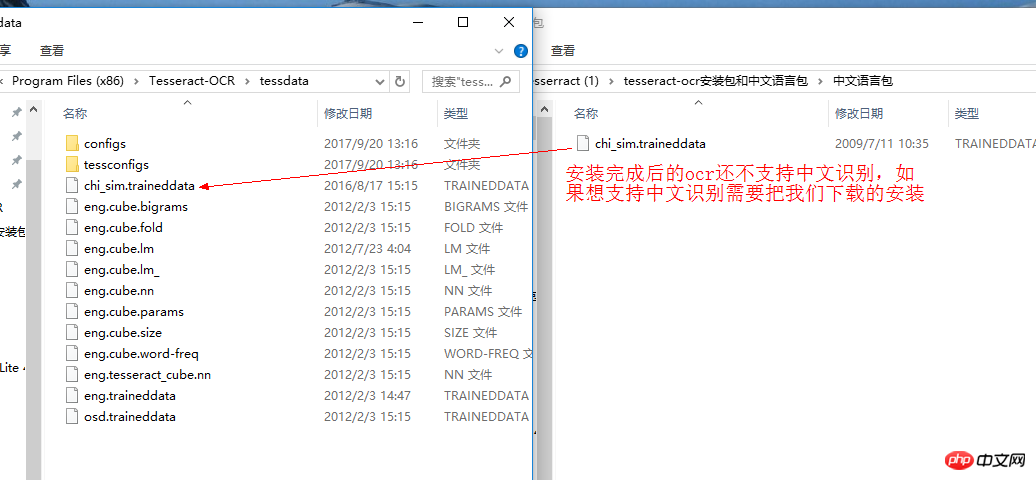
C:UsershuxiuAppDataLocalProgramsPythonPython35Libsite-packagespytesseractでpytesseract.pyを見つけて開き、次の操作を実行します
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY #tesseract_cmd = 'tesseract' tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
以上がPython コードは画像テキスト認識を実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



