


XML ファイルを解析するには、次のように xml.etree.ElementTree モジュールを使用します。 ElementTree モジュールは、この目的を達成するために 2 つのクラスを提供します:
ElementTree は XML ファイル全体 (ツリー構造) を表します
Element はツリー内の要素 (ノード) を表します
以下を操作しますXML ファイル: migapp.xml

次のように ElementTree モジュールをインポートできます: import xml.etree.ElementTree as ET
または、解析パーサーのみをインポートできます: from xml.etree.ElementTree import parse
まず、XML ファイルを開く必要があります。ローカル ファイルの場合は、open 関数を使用します。インターネット ファイルの場合は、urlopen:
f = open( ' migapp.xml ' , ' rt ' , encoding= ' utf-) を使用します。 8 ' )
次に XML を解析します。
1tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)
1.4
指定されたすべての要素を繰り返し解析します 
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict1.5
いくつかの便利なメソッド 
print(root[1][1].tag) print(root[1][1].text)
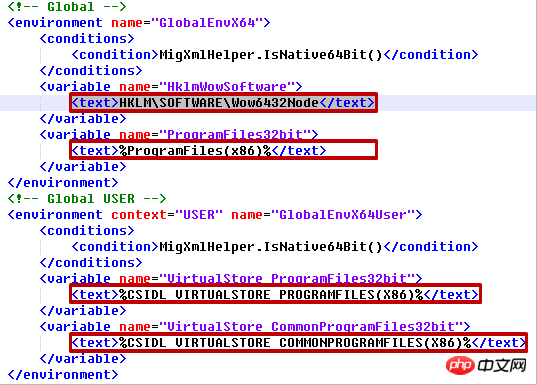
2 XMLファイルを変更する
属性サイズを追加する必要があるとします。各テキスト要素に ="50" を入力し、そのテキストを "Benxin Tuzi" に変更し、サブ要素 date="2016/01/16"
for element in root.iter('environment'):
print(element.attrib)migapp.xml の部分:

Output.xml 対応する部分:

ImportError: No module names 'xml.etree '; 'xml' はパッケージではありません
 分析:
分析:
これは、インポート時に、最初に現在のパス内で xml.py モジュールが存在することが判明し、xml.py が検索されるためです。私たちが自分で書いたものは、もちろんパッケージではありません注:
xml を削除すると、py はまだ正常に解釈できません。これは、xml.pyc も現在のパスに生成され、このファイルの優先順位が xml よりも高いためです。 py なので、インタプリタはまだ最初に xml.pyc でそれを検索するため、このファイルも削除する必要があり、問題は正常に解決されました。 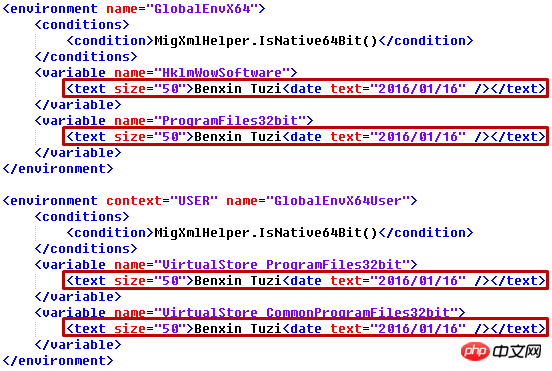
以上がPython による XML ファイルの解析例 (画像)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



