ハイブリッド専門家は、外科分野でも専門知識を持っています。
現在の混合モダリティ基本モデルでは、特定のモダリティのエンコーダまたはデコーダを融合することが一般的なアーキテクチャ設計ですが、この方法には限界があります。異なるモダリティからの情報を統合できず、統合が困難です。出力には複数のモダリティのコンテンツが含まれます。 この制限を克服するために、Meta FAIR の Chameleon チームは、最近の論文「Chameleon: Mixed-modal Early-fusion Foundation models」で、次のトークンに基づくことができる新しい単一の Transformer アーキテクチャを提案しました。予測の目標は、個別の画像トークンとテキスト トークンで構成される混合モーダル シーケンスをモデル化し、異なるモダリティ間でのシームレスな推論と生成を可能にすることです。 
約 10 兆個の混合モーダル トークンに関する事前トレーニングを完了した後、Chameleon は広範囲の視覚および言語機能を実証し、さまざまなダウンストリーム タスクを適切に処理できるようになりました。 Chameleon のパフォーマンスは、混合モードの長文回答を生成するタスクにおいて特に優れており、Gemini 1.0 Pro や GPT-4V などの商用モデルをも上回ります。ただし、モデル トレーニングの初期段階でさまざまなモダリティが混在する Chameleon のようなモデルの場合、その機能を拡張するには大量のコンピューティング能力を投資する必要があります。 上記の問題に基づいて、Meta FAIR チームは配線されたスパース アーキテクチャに関する調査と探索を実施し、MoMa: モダリティを意識したエキスパート ハイブリッド アーキテクチャを提案しました。
- Paper title: MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
- Paper address: https://arxiv.org/pdf/2407.21770
Previously Research has shown that this type of architecture can effectively expand the capabilities of single-modal basic models and enhance the performance of multi-modal contrastive learning models. However, using it for early model training that integrates various modalities is still a topic with both opportunities and challenges, and few people have studied it. The team’s research is based on the insight that different modalities are inherently heterogeneous – text and image tokens have different information densities and redundancy patterns. While integrating these tokens into a unified fusion architecture, the team also proposed to further optimize the framework by integrating modules for specific modalities. The team calls this concept modality-aware sparsity, or MaS for short; it allows the model to better capture the characteristics of each modality while also using partial parameter sharing and attention mechanisms. Maintain strong cross-modal integration performance. Previous research such as VLMo, BEiT-3 and VL-MoE have adopted the mixed modality experts (MoME/mixture-of-modality-experts) method to train the visual-language encoder and masked language construction. Model, the research team from FAIR has further pushed the usable scope of MoE one step further. The new model proposed in this article is based on Chameleon's early fusion architecture, which is to represent images and text into one in a unified Transformer A series of discrete tokens. At its core, Chameleon is a Transformer-based model that applies a self-attention mechanism to a combined sequence of image and text tokens. This allows the model to capture complex correlations within and between modalities. The model is trained with the goal of next token prediction, generating text and image tokens in an autoregressive manner. In Chameleon, the image tokenization scheme uses a learning image tokenizer, which will encode a 512 × 512 image into 1024 discrete tokens based on a codebook of size 8192. For text segmentation, a BPE tokenizer with a vocabulary size of 65,536 will be used, which contains image tokens. This unified word segmentation method allows the model to seamlessly handle any sequence of intertwined image and text tokens. With this method, the new model inherits the advantages of unified representation, good flexibility, high scalability, and support for end-to-end learning. On this basis (Figure 1a), in order to further improve the efficiency and performance of the early fusion model, the team also introduced modality-aware sparsity technology. Width Scaling: Modality-Aware Hybrid Experts The team proposes a width-scaling method: integrating modality-aware module sparsity into forward modules, thereby scaling Standard Hybrid Expert (MoE) architecture. This method is based on the insight that tokens in different modes have different characteristics and information densities. By constructing different expert groups for each modality, the model can develop specialized processing paths while maintaining cross-modal information integration capabilities. Figure 1b illustrates the key components of this modality-aware expert mixture (MoMa). To put it simply, experts of each specific modality are first grouped, then hierarchical routing is implemented (divided into modality-aware routing and intra-modal routing), and finally experts are selected. Please refer to the original paper for the detailed process. In general, for an input token x, the formal definition of the MoMa module is: 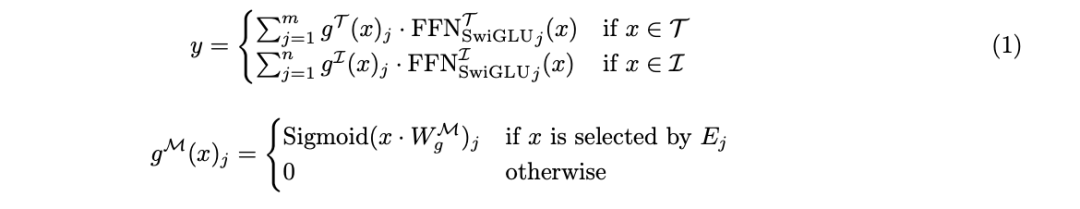
After MoMa calculation, the team further used residual connection and Swin Transformer normalization. Previous researchers have also explored introducing sparsity into the depth dimension. Their approach was either to randomly discard certain layers or to use available Learning router. Specifically, as shown in the figure below, the team’s approach is to integrate MoD in each MoD layer before hybrid expert (MoE) routing, thereby ensuring that the entire batch of data is Can use MoD. In the inference phase, we cannot directly use MoE's expert selection routing or MoD's layer selection routing because top-k (select the top k) are performed in a batch of data ) selection destroys causation. In order to ensure the causal relationship of reasoning, inspired by the above-mentioned MoD paper, the research team introduced an auxiliary router (auxiliary router), whose role is to predict that the token will be selected by a certain expert or layer based only on the hidden representation of the token. possibility. There is a unique difficulty for a MoE architecture trained from scratch in terms of optimizing the representation space and routing mechanism. The team discovered that the MoE router is responsible for dividing the representation space for each expert. However, in the early stages of model training, this representation space is not optimal, which will lead to the routing function obtained by training being sub-optimal. In order to overcome this limitation, they proposed an upgrading method based on the paper "Sparse upcycling: Training mixture-of-experts from dense checkpoints" by Komatsuzaki et al. 
Specifically, first train an architecture with one FFN expert per modality. After some preset steps, the model is upgraded and transformed. The specific method is: convert the FFN of each specific modality into an expert-selected MoE module, and initialize each expert to the first stage of training. experts. This will reset the learning rate scheduler while retaining the data loader state of the previous stage to ensure that the refreshed data can be used in the second stage of training. To promote experts to be more specialized, the team also used Gumbel noise to enhance the MoE routing function, allowing the new router to sample experts in a differentiable manner. This upgrading method coupled with Gumbel-Sigmoid technology can overcome the limitations of the learned routers, thereby improving the performance of the newly proposed modality-aware sparse architecture. To promote MoMa’s distributed training, the team adopted Fully Sharded Data Parallel (FSDP/Fully Sharded Data Parallel). However, compared with conventional MoE, this method has some unique efficiency challenges, including load balancing issues and efficiency issues of expert execution. For the load balancing problem, the team developed a balanced data mixing method that keeps the text-to-image data ratio on each GPU consistent with the expert ratio. Regarding the efficiency of expert execution, the team has explored some strategies that can help improve the execution efficiency of experts in different modalities:
- Limit experts in each modality to be homogeneous experts , and prohibit routing text tokens to image experts and vice versa;
- Use block sparsity to improve execution efficiency;
- When the number of modalities is limited, run different modalities in sequence experts.
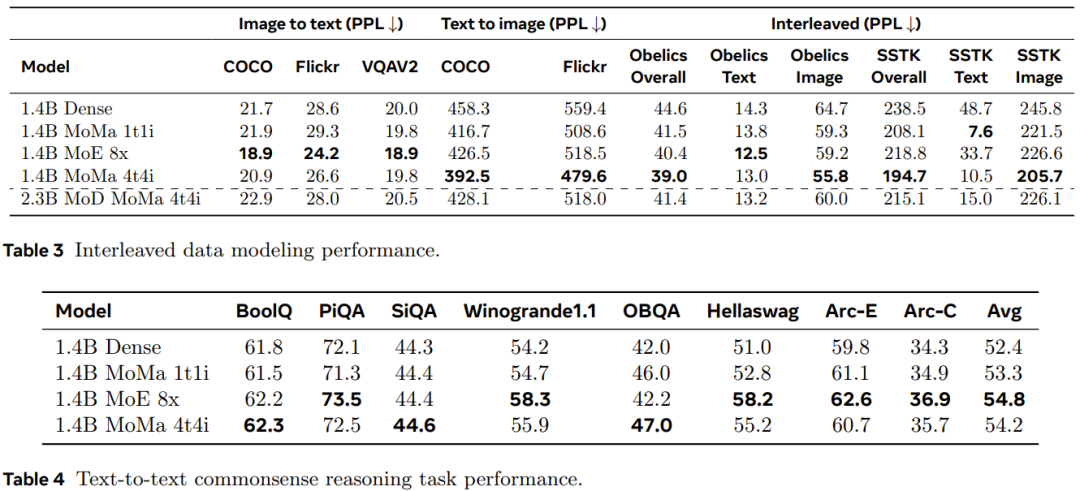
Since each GPU in the experiment processed enough tokens, hardware utilization is not a big problem even if multiple batched matrix multiplications are used. Therefore, the team believes that the sequential execution method is a better choice for the current scale of experimental environment. In order to further improve throughput, the team also adopted some other optimization techniques. This includes general optimization operations such as reducing gradient communication volume and automated GPU core fusion. The research team also implemented graph optimization through torch.compile. Additionally, they have developed some optimization techniques for MoMa, including reusing modal token indexes across different layers to most efficiently synchronize devices between CPU and GPU. The pre-training dataset and pre-processing process used in the experiment are the same as Chameleon. To evaluate scaling performance, they trained the model using more than 1 trillion tokens. Table 1 gives the detailed configuration of dense and sparse models. Scaling performance at different computing levelsThe team analyzed the scaling performance of different models at different computing levels. These computing levels (FLOPs) are equivalent to three sizes of dense models: 90M, 435M and 1.4B. Experimental results show that a sparse model can match the pre-training loss of a dense model with equivalent FLOPs using only 1/η of the total FLOPs (η represents the pre-training acceleration factor). Introducing modality-specific expert grouping can improve the pre-training efficiency of models of different sizes, which is especially beneficial for image modalities. As shown in Figure 3, the moe_1t1i configuration using 1 image expert and 1 text expert significantly outperforms the corresponding dense model. Expanding the number of experts in each modal group can further improve model performance. Hybrid Depth with Experts The team observed that the convergence speed of the training loss is improved when using MoE and MoD and their combined form. As shown in Figure 4, adding MoD (mod_moe_1t1i) to the moe_1t1i architecture significantly improves model performance across different model sizes. In addition, mod_moe_1t1i can match or even exceed moe_4t4i in different model sizes and modes, which shows that introducing sparsity in the depth dimension can also effectively improve training efficiency. On the other hand, you can also see that the benefits of stacking MoD and MoE will gradually decrease. Expanding the number of expertsTo study the impact of expanding the number of experts, the team conducted further ablation experiments. They explored two scenarios: assigning an equal number of experts to each modality (balanced) and assigning a different number of experts to each modality (imbalanced). The results are shown in Figure 5. For the balanced setting, it can be seen from Figure 5a that as the number of experts increases, the training loss will significantly decrease. But text and image losses exhibit different scaling patterns. This suggests that the inherent characteristics of each modality lead to different sparse modeling behaviors. For the unbalanced setting, Figure 5b compares three different configurations with equivalent total number of experts (8). It can be seen that the more experts there are in a modality, the better the model generally performs on that modality. Upgrade and transformationThe team has naturally verified the effect of the aforementioned upgrade and transformation. Figure 6 compares the training curves of different model variants. The results show that upgrading can indeed further improve model training: when the first stage has 10k steps, upgrading can bring 1.2 times the FLOPs benefit; and when the number of steps is 20k, there are also 1.16x FLOPs return. In addition, it can be observed that as training progresses, the performance gap between the upgraded model and the model trained from scratch will continue to increase. Sparse models often do not bring immediate performance gains because sparse models increase dynamics and associated data balancing issues. To quantify the impact of the newly proposed method on training efficiency, the team compared the training throughput of different architectures in experiments with usually controlled variables. The results are shown in Table 2. It can be seen that compared to the dense model, the modal-based sparse performance achieves a better quality-throughput trade-off, and can show reasonable scalability as the number of experts grows. On the other hand, although the MoD variants achieve the best absolute losses, they also tend to be more computationally expensive due to additional dynamics and imbalances. Inference time performanceThe team also evaluated the model’s performance on retained language modeling data and downstream tasks. The results are shown in Tables 3 and 4. As shown in Table 3, by using multiple image experts, the 1.4B MoMa 1t1i model outperforms the corresponding dense model in most metrics, except for the image-to-text conditional perplexity metric on COCO and Flickr exception. Further scaling the number of experts also improves performance, with 1.4B MoE 8x achieving the best image-to-text performance. In addition, as shown in Table 4, the 1.4B MoE 8x model is also very good at text-to-text tasks. 1.4B MoMa 4t4i performs best on all conditional image perplexity metrics, while its text perplexity on most benchmarks is also very close to 1.4B MoE 8x. Overall, the 1.4B MoMa 4t4i model has the best modeling results on mixed text and image modalities. For more details, please read the original paper. 以上がハイブリッド エキスパートはより積極的であり、複数のモダリティを認識し、状況に応じて行動することができます。メタはモダリティを認識したエキスパート ハイブリッドを提案します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



