AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事は HMI Lab によって完成されました。 HMI Lab北京大学の国立ビデオおよびビジュアルテクノロジー工学研究センターとマルチメディア情報処理国家重点実験室の2つの主要なプラットフォームに依存して、機械学習、マルチメディア情報処理の方向の研究に長年従事してきました。モーダル学習と身体化された知能。この研究の最初の著者は Liu Jiaming 博士で、彼の研究の方向性はマルチモーダルに具現化された大型モデルとオープンワールド向けの連続学習テクノロジーです。この著作の 2 人目の著者は Liu Mengzhen で、彼の研究方向は視覚基本モデルとロボット操作です。講師は、北京大学コンピューターサイエンス学部の研究者であり、博士課程の指導教員であり、若手リベラル学者であるチェン・シャンハン氏です。マルチモーダル大規模モデルと身体化知能の研究に従事し、一連の重要な研究結果を達成し、人工知能のトップジャーナルや会議に 80 以上の論文を発表し、Google に 9,700 回以上引用されています。世界トップの人工知能カンファレンスであるAAAIから最優秀論文賞を受賞し、世界最大の学術ソースコードリポジトリであるTrending Researchで1位にランクされました。 ロボットにエンドツーエンドの推論と操作機能を与えるために、この記事ではビジュアル エンコーダーを効率的な状態空間言語モデルと革新的に統合して、新しい RoboMamba マルチモーダル大規模モデルを構築し、視覚的に共通の機能を実現します。センスタスクと関連タスクに関するロボットの推論機能を統合し、高度なパフォーマンスを実現しました。同時に、この記事では、RoboMamba が強力な推論能力を備えている場合、非常に低いトレーニング コストで RoboMamba が複数の操作姿勢予測機能を習得できることがわかりました。

論文: RoboMamba: 効率的なロボット推論と操作のためのマルチモーダル状態空間モデル
論文リンク: https://arxiv.org/abs/2406.04339
プロジェクトホームページ: https:// sites.google.com/view/robomamba-web
Github: https://github.com/lmzpai/roboMamba

図 1. RoboMamba のロボット関連機能 (タスクを含む) 、即時ミッション計画、長距離ミッション計画、操縦性判断、操縦性生成、未来および過去の予測、エンドエフェクター姿勢予測など。 ロボット操作の基本的な目標は、モデルが視覚的なシーンを理解してアクションを実行できるようにすることです。既存のロボット マルチモーダル大規模モデル (MLLM) は一連の基本的なタスクを処理できますが、次の 2 つの側面で依然として課題に直面しています。1) 複雑なタスクを処理するための推論能力が不十分である。2) MLLM の微調整と推論の計算コストが比較的高い。高い。最近提案された状態空間モデル (SSM)、つまり Mamba は、線形推論の複雑さを備えていると同時に、シーケンス モデリングで有望な機能を実証しています。これに触発されて、私たちはエンドツーエンドのロボット MLLM、RoboMamba を立ち上げました。これは、Mamba モデルを使用して、効率的な微調整と推論機能を維持しながら、ロボットの推論とアクション機能を提供します。 具体的には、まずビジュアルエンコーダーをMambaと統合し、共同トレーニングを通じてビジュアルデータを言語埋め込みと調整し、モデルに視覚的常識とロボット関連の推論機能を与えます。 RoboMamba の操作ポーズ予測機能をさらに強化するために、単純なポリシー ヘッドのみを使用して効率的な微調整戦略を検討します。 RoboMamba が十分な推論能力を備えれば、非常に少ない微調整パラメーター (モデルの 0.1%) と微調整時間 (20 分) で複数の操作スキルを習得できることがわかりました。図 2 に示すように、実験では、RoboMamba は一般評価ベンチマークおよびロボット評価ベンチマークで優れた推論能力を実証しました。同時に、私たちのモデルは、既存のロボット MLLM よりも最大 7 倍速い推論速度で、シミュレーションや実世界の実験において優れた操作ポーズ予測機能を実証します。 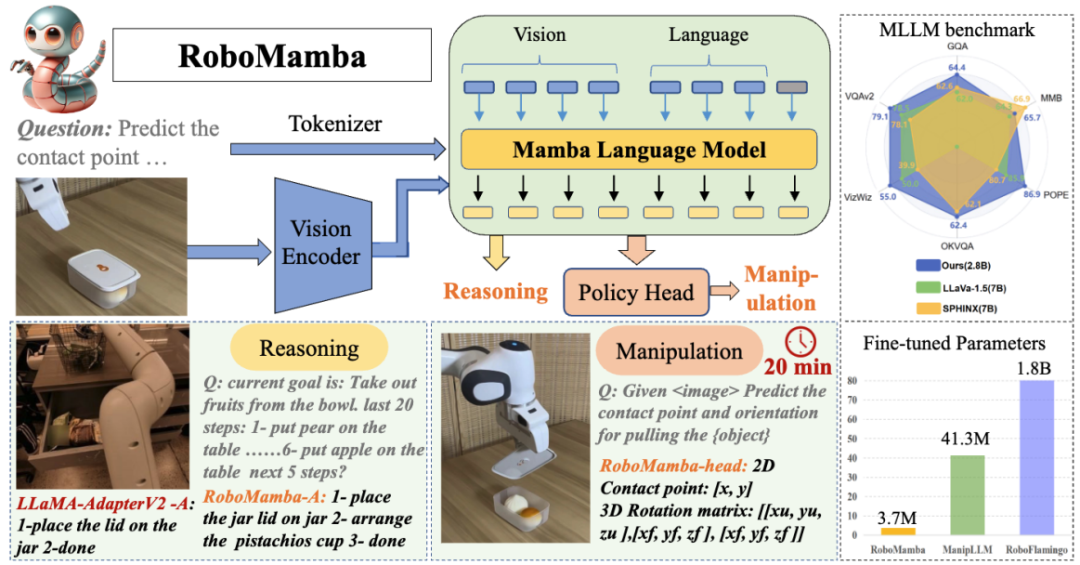
그림 2. 개요: Robomamba는 강력한 추론 및 작동 기능을 갖춘 효율적인 다중 모드 대형 로봇 모델입니다. RoboMamba-2.8B는 범용 MLLM 벤치마크에서 다른 7B MLLM과 함께 경쟁력 있는 추론 성능을 달성하는 동시에 로봇 작업에서 장거리 추론 기능을 보여줍니다. 그 후, RoboMamba가 조작 포즈를 예측할 수 있는 능력을 제공하기 위해 매우 효율적인 미세 조정 전략을 도입했으며, 간단한 전략 헤드를 미세 조정하는 데 20분 밖에 걸리지 않습니다. 이 기사의 주요 기여는 다음과 같이 요약됩니다.
- 우리는 시각적 인코더를 효율적인 Mamba 언어 모델과 혁신적으로 통합하여 새로운 엔드투엔드 다중 모달 대형을 구축합니다. 로봇에 관한 시각적 상식과 종합적인 추론 능력을 갖춘 로봇모델 로보맘바(RoboMamba).
- RoboMamba에 엔드 이펙터 조작 포즈 예측 기능을 탑재하기 위해 간단한 정책 헤드를 사용하여 효율적인 미세 조정 전략을 탐색했습니다. RoboMamba가 충분한 추론 능력에 도달하면 매우 저렴한 비용으로 조작 포즈 예측 기술을 마스터할 수 있다는 것을 발견했습니다.
- RoboMamba는 광범위한 실험에서 일반 및 로봇 추론 평가 벤치마크에서 좋은 성능을 발휘했으며 시뮬레이터와 실제 실험에서 인상적인 포즈 예측 결과를 보여주었습니다.
데이터의 확장으로 인해 LLM(대형 언어 모델) 연구 개발이 크게 촉진되어 자연어 처리(NLP) 진행에서 중요한 추론 및 일반화 기능이 입증되었습니다. 다중 모드 정보를 이해하기 위해 다중 모드 대형 언어 모델(MLLM)이 등장하여 LLM이 시각적 지침을 따르고 장면을 이해할 수 있는 능력을 제공했습니다. 범용 환경에서 MLLM의 강력한 기능에 영감을 받아 최근 연구는 MLLM을 로봇 작동 분야에 적용하는 것을 목표로 합니다. 일부 연구 노력을 통해 로봇은 자연어와 시각적 장면을 이해하고 자동으로 임무 계획을 생성할 수 있습니다. 다른 연구에서는 MLLM의 고유 기능을 활용하여 작동 자세를 예측할 수 있습니다. 로봇 작동에는 동적 환경에서 객체와 상호 작용하는 작업이 포함되므로 장면의 의미 정보를 이해하기 위한 인간과 같은 추론 능력과 강력한 조작 포즈 예측 기능이 필요합니다. 기존 로봇 기반 MLLM은 다양한 기본 작업을 처리할 수 있지만 여전히 두 가지 측면에서 과제에 직면해 있습니다. 1) 첫째, 로봇 시나리오에서 사전 훈련된 MLLM의 추론 능력이 부족한 것으로 나타났습니다. 그림 2에 표시된 것처럼 미세 조정된 로봇 MLLM이 복잡한 추론 작업에 직면할 때 이러한 단점은 문제를 야기합니다. 2) 둘째, 기존 MLLM 주의 메커니즘의 높은 계산 복잡성으로 인해 MLLM을 미세 조정하고 이를 사용하여 로봇 작동 동작을 생성하면 더 높은 계산 비용이 발생합니다. 추론 능력과 효율성의 균형을 맞추기 위해 NLP 분야에서는 여러 연구가 등장했습니다. 특히 Mamba는 선형 복잡성을 유지하면서 상황 인식 추론을 촉진하는 혁신적인 SSM(Selective State Space Model)을 도입했습니다. 이에 영감을 받아 우리는 "강력한 추론 능력뿐만 아니라 매우 경제적인 방법으로 로봇 작동 기술을 습득할 수 있는 효율적인 로봇 MLLM을 개발할 수 있을까요?"라는 질문을 했습니다. method문제 설명
-
로보 맘바는 이미지
와 언어 질문을 기반으로 언어를 생성합니다.
정답은
,
로 표현됩니다.추론 답변에는 질문  에 대한 별도의 하위 작업
에 대한 별도의 하위 작업  이 포함되는 경우가 많습니다. 예를 들어, "테이블을 치우는 방법"과 같은 계획 문제에 직면하면 일반적으로 "1단계: 물건 집어들기" 및 "2단계: 상자에 물건 넣기"와 같은 단계가 포함됩니다. 행동 예측을 위해 효율적이고 간단한 정책 헤드 π를 활용하여 행동을 예측합니다
이 포함되는 경우가 많습니다. 예를 들어, "테이블을 치우는 방법"과 같은 계획 문제에 직면하면 일반적으로 "1단계: 물건 집어들기" 및 "2단계: 상자에 물건 넣기"와 같은 단계가 포함됩니다. 행동 예측을 위해 효율적이고 간단한 정책 헤드 π를 활용하여 행동을 예측합니다 . 이전 작업에 이어 6-DoF를 사용하여 Franka Emika Panda 로봇 팔의 엔드 이펙터 포즈를 표현했습니다. 6 자유도에는 3차원 좌표를 나타내는 엔드 이펙터 위치
. 이전 작업에 이어 6-DoF를 사용하여 Franka Emika Panda 로봇 팔의 엔드 이펙터 포즈를 표현했습니다. 6 자유도에는 3차원 좌표를 나타내는 엔드 이펙터 위치 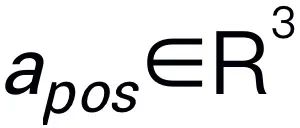 와 회전 행렬을 나타내는 방향
와 회전 행렬을 나타내는 방향  이 포함됩니다. 잡기 작업에 대한 훈련을 하는 경우 포즈 예측에 그리퍼 상태를 추가하여 7-DoF 제어를 활성화합니다.
이 기사에서는 Mamba를 대규모 언어 모델로 선택했습니다. Mamba는 수많은 Mamba 블록으로 구성되어 있으며, 가장 중요한 구성 요소는 SSM입니다. SSM은 숨겨진 상태
이 포함됩니다. 잡기 작업에 대한 훈련을 하는 경우 포즈 예측에 그리퍼 상태를 추가하여 7-DoF 제어를 활성화합니다.
이 기사에서는 Mamba를 대규모 언어 모델로 선택했습니다. Mamba는 수많은 Mamba 블록으로 구성되어 있으며, 가장 중요한 구성 요소는 SSM입니다. SSM은 숨겨진 상태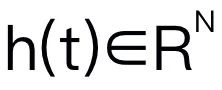 를 통해 1D 입력 시퀀스
를 통해 1D 입력 시퀀스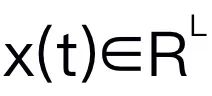 를 1D 출력 시퀀스
를 1D 출력 시퀀스 로 투영하는 연속 시스템을 기반으로 설계되었습니다. SSM은 상태 행렬
로 투영하는 연속 시스템을 기반으로 설계되었습니다. SSM은 상태 행렬 , 입력 행렬
, 입력 행렬 , 출력 행렬
, 출력 행렬 이라는 세 가지 주요 매개변수로 구성됩니다. SSM은 다음과 같이 표현될 수 있습니다.
이라는 세 가지 주요 매개변수로 구성됩니다. SSM은 다음과 같이 표현될 수 있습니다. 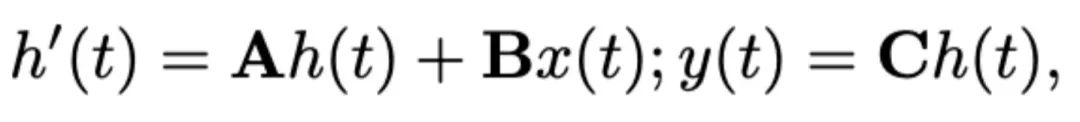
최근 SSM(예: Mamba)은 시간 척도 매개변수 Δ를 사용하여 이산 연속 시스템으로 구성됩니다. 이 매개변수는 연속 매개변수 A와 B를 이산 매개변수  및
및  로 변환합니다. 이산화는 다음과 같이 정의되는 0차 보존 방법을 채택합니다.
로 변환합니다. 이산화는 다음과 같이 정의되는 0차 보존 방법을 채택합니다. 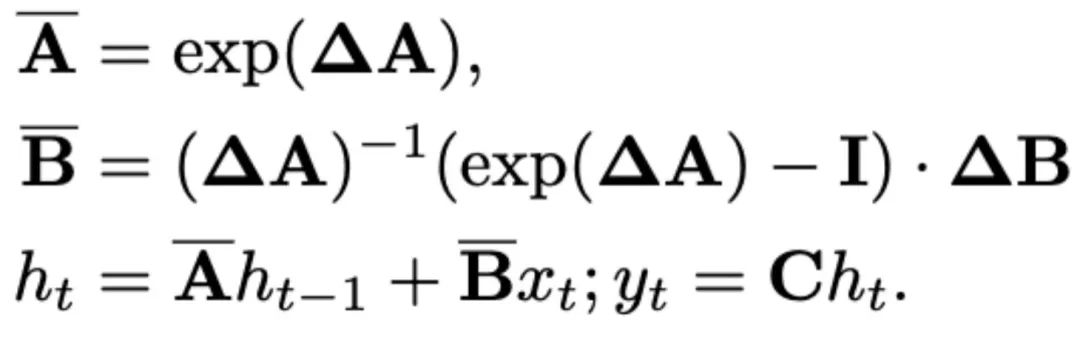
Mamba は、各 Mamba ブロックで SSM 操作を形成するために選択的スキャン メカニズム (S6) を導入しています。コンテンツを意識した推論を改善するために、SSM パラメーターが  に更新されました。 Mamba ブロックの詳細を以下の図 3 に示します。
に更新されました。 Mamba ブロックの詳細を以下の図 3 に示します。 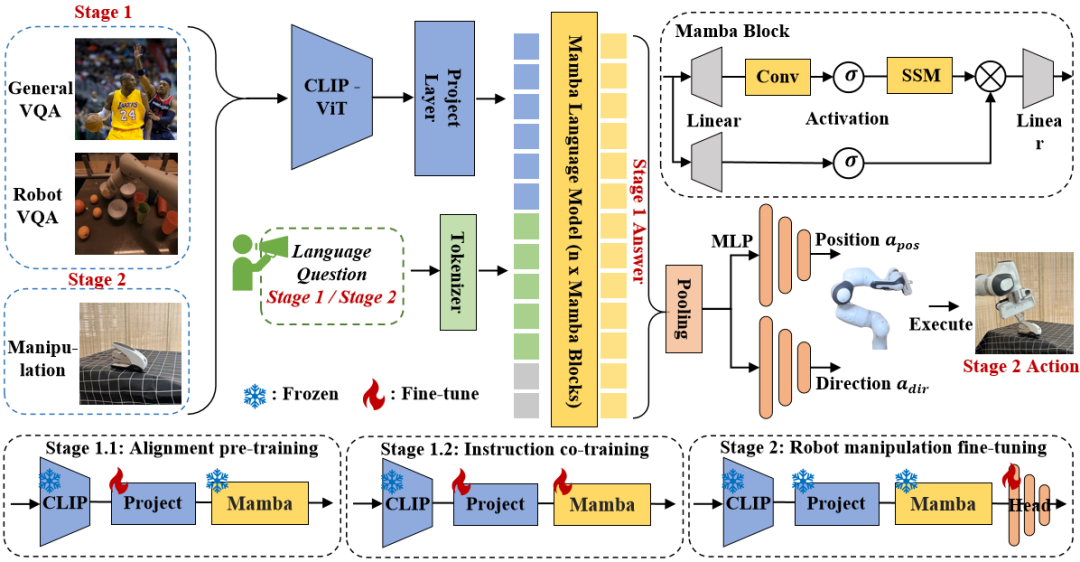
図 3. RoboMamba 全体のフレームワーク。 RoboMamba は、ビジュアル エンコーダーと投影レイヤーを介して画像を Mamba の言語埋め込み空間に投影し、その後テキスト トークンと連結されて Mamba モデルに供給されます。エンドエフェクターの位置と方向を予測するために、単純な MLP ポリシー ヘッドを導入し、プーリング操作を使用して、入力としての言語出力トークンからグローバル トークンを生成します。 RoboMamba のトレーニング戦略。 モデルのトレーニングでは、トレーニング プロセスを 2 つの段階に分けます。ステージ 1 では、RoboMamba に常識推論機能とロボット関連推論機能を装備するための、調整された事前トレーニング (ステージ 1.1) と指示共同トレーニング (ステージ 1.2) を導入します。ステージ 2 では、RoboMamba に低レベルの操作スキルを効率的に与えるためのロボット操作の微調整を提案します。 RoboMamba に視覚的な推論と操作機能を装備するために、事前トレーニングされた大規模言語モデル (LLM) とビジョン モデルから始まる効率的な MLLM アーキテクチャを構築しました。上の図 3 に示すように、CLIP ビジュアル エンコーダーを使用して入力画像 I から視覚特徴 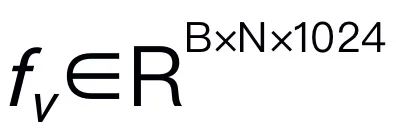 を抽出します。ここで、B と N はそれぞれバッチ サイズとトークンの数を表します。最近の MLLM とは異なり、画像特徴抽出に複数のバックボーン ネットワーク (つまり、DINOv2、CLIP-ConvNeXt、CLIP-ViT) を使用するビジュアル エンコーダ アンサンブル技術は採用していません。統合により追加の計算コストが発生し、現実世界でのロボット MLLM の実用性に重大な影響を与えます。したがって、高品質のデータと適切なトレーニング戦略を組み合わせると、シンプルで単純なモデル設計でも強力な推論機能を実現できることを実証します。 LLM に視覚的な特徴を理解させるために、多層パーセプトロン (MLP) を使用して視覚的なエンコーダーを LLM に接続します。このシンプルなクロスモーダル コネクタを使用して、RoboMamba は視覚情報を言語埋め込み空間
を抽出します。ここで、B と N はそれぞれバッチ サイズとトークンの数を表します。最近の MLLM とは異なり、画像特徴抽出に複数のバックボーン ネットワーク (つまり、DINOv2、CLIP-ConvNeXt、CLIP-ViT) を使用するビジュアル エンコーダ アンサンブル技術は採用していません。統合により追加の計算コストが発生し、現実世界でのロボット MLLM の実用性に重大な影響を与えます。したがって、高品質のデータと適切なトレーニング戦略を組み合わせると、シンプルで単純なモデル設計でも強力な推論機能を実現できることを実証します。 LLM に視覚的な特徴を理解させるために、多層パーセプトロン (MLP) を使用して視覚的なエンコーダーを LLM に接続します。このシンプルなクロスモーダル コネクタを使用して、RoboMamba は視覚情報を言語埋め込み空間 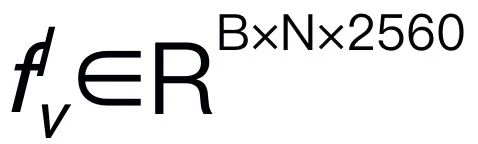 に変換できます。 ロボットは人間の指示に迅速に応答する必要があるため、ロボット工学の分野ではモデルの効率が非常に重要であることに注意してください。したがって、コンテキストを認識した推論機能と線形計算の複雑さにより、大規模言語モデルとして Mamba を選択します。テキストのプロンプトは、事前トレーニングされたトークナイザーを使用して埋め込みスペース
に変換できます。 ロボットは人間の指示に迅速に応答する必要があるため、ロボット工学の分野ではモデルの効率が非常に重要であることに注意してください。したがって、コンテキストを認識した推論機能と線形計算の複雑さにより、大規模言語モデルとして Mamba を選択します。テキストのプロンプトは、事前トレーニングされたトークナイザーを使用して埋め込みスペース 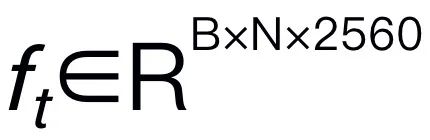 にエンコードされ、ビジュアル トークンと連結 (cat) されて Mamba に供給されます。私たちは Mamba の強力なシーケンス モデリングを活用してマルチモーダルな情報を理解し、効果的なトレーニング戦略を使用して視覚的な推論能力を開発します (次のセクションで説明します)。次に、出力トークン (
にエンコードされ、ビジュアル トークンと連結 (cat) されて Mamba に供給されます。私たちは Mamba の強力なシーケンス モデリングを活用してマルチモーダルな情報を理解し、効果的なトレーニング戦略を使用して視覚的な推論能力を開発します (次のセクションで説明します)。次に、出力トークン ( ) がデコード (det) されて、自然言語応答
) がデコード (det) されて、自然言語応答 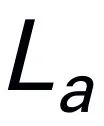 が生成されます。モデルの前進プロセスは次のように表現できます:
が生成されます。モデルの前進プロセスは次のように表現できます: 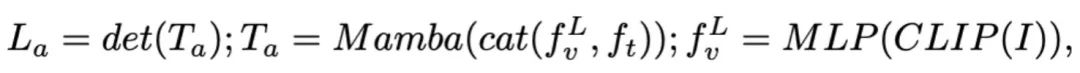
3.RoboMamba の一般的な視覚とロボット推論能力のトレーニング RoboMamba アーキテクチャを構築した後の次の目標は、一般的な視覚推論とロボット関連の推論能力を学習するためにモデルをトレーニングすることです。図 3 に示すように、ステージ 1 のトレーニングを、アライメント事前トレーニング (ステージ 1.1) と指導同時トレーニング (ステージ 1.2) の 2 つのサブステップに分割します。具体的には、これまでの MLLM トレーニング方法とは異なり、RoboMamba が一般的なビジョンとロボット工学のシナリオを理解できるようにすることを目指しています。ロボット工学の分野には多くの複雑で斬新なタスクが含まれるため、RoboMamba にはより強力な汎用化機能が必要です。したがって、ステージ 1.2 では、高レベルのロボット データ (ミッション計画など) と一般的な指示データを組み合わせる共同トレーニング戦略を採用しました。共同トレーニングにより、ロボット ポリシーがより一般化されるだけでなく、ロボット データの複雑な推論タスクにより、一般的なシナリオの推論能力も強化されることがわかりました。トレーニングの詳細は次のとおりです: - ステージ 1.1: アライメントの事前トレーニング。
クロスモーダルアライメントには、LLaVA フィルター処理された 558k 画像とテキストのペアのデータセットを採用します。図 3 に示すように、CLIP エンコーダーと Mamba 言語モデルのパラメーターをフリーズし、投影レイヤーのみを更新します。このようにして、画像の特徴を事前にトレーニングされた Mamba の単語埋め込みと一致させることができます。 - ステージ 1.2: 一緒にトレーニングするコマンド。
この段階では、まず、以前の MLLM の作業に従って、一般的な視覚的指示データを収集します。私たちは、幻覚に従う視覚的指示を学習するために 655,000 個の LLaVA ハイブリッド命令データセットと幻覚を軽減するための 400,000 個の LRV 命令データセットを使用します。ロボット MLLM は想像上のシナリオではなく実際のシナリオに基づいてミッション プランを生成する必要があるため、幻覚の軽減がロボット シナリオで重要な役割を果たすことに注意することが重要です。たとえば、既存の MLLM は、「電子レンジを開けて」に対して「ステップ 1: ハンドルを見つけてください」と形式的に答えることができますが、多くの電子レンジにはハンドルがありません。次に、800K RoboVQA データセットを組み合わせて、長距離ミッションの計画、操縦性の判断、操縦性の生成、未来と過去の予測などの高度なロボット スキルを学習します。図 3 に示すように、共同トレーニング中に、CLIP エンコーダーのパラメーターをフリーズし、1.8 メートルのマージされたデータセット上の投影レイヤーと Mamba を微調整します。 Mamba 言語モデルからのすべての出力は、クロスエントロピー損失を使用して監視されます。 4. RoboMamba の操作能力の微調整トレーニング このセクションでは、RoboMamba の強力な推論機能に基づいて、ロボット操作の微調整戦略を紹介します。これは、図 3 のトレーニング ステージ 2 と呼ばれます。 。既存の MLLM ベースのロボット操作方法では、操作の微調整段階で投影層と LLM 全体を更新する必要があります。このパラダイムはモデルにアクション ポーズの予測機能を与えることができますが、MLLM の固有の機能も破壊し、大量のトレーニング リソースを必要とします。これらの課題に対処するために、図 3 に示すような効率的な微調整戦略を提案します。 RoboMamba のすべてのパラメーターを凍結し、Mamba の出力トークンをモデル化する単純なポリシー ヘッドを導入します。ポリシー ヘッドには、エンド エフェクターの位置と方向をそれぞれ学習する 2 つの MLP が含まれており、モデル パラメーター全体の合計 0.1% を占めます。以前の研究 where2act によると、位置と方向の損失公式は次のとおりです: 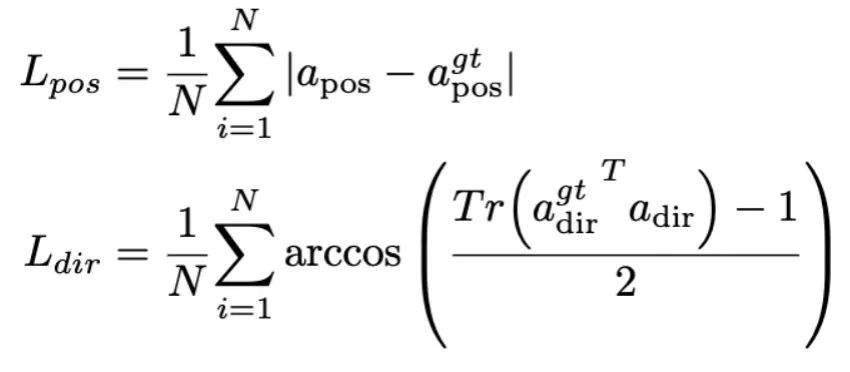 ここで、N はトレーニング サンプルの数を表し、Tr (A) は行列 A のトレースを表します。 RoboMamba は、画像内の接触ピクセルの 2D 位置 (x、y) のみを予測し、深度情報を使用してそれを 3D 空間に変換します。この微調整戦略を評価するために、SAPIEN シミュレーションを使用して 10,000 のエンドエフェクターのポーズ予測のデータセットを生成しました。 運用の微調整の結果、RoboMamba が十分な推論能力を備えていれば、非常に効率的な微調整を通じて姿勢予測スキルを獲得できることがわかりました。最小限の微調整パラメーター (7MB) と効率的なモデル設計により、わずか 20 分で新しい操作スキルの学習を達成できます。この発見は、運用スキルを学習する際の推論能力の重要性を強調し、MLLM 本来の推論能力に影響を与えることなく、MLLM に運用能力を効率的に与えることができるという新しい視点を提案しています。最後に、RoboMamba は、常識およびロボット関連の推論に言語応答を使用し、アクション ポーズの予測にポリシー ヘッドを使用できます。 1. 一般的な推論能力の評価 (MLLM ベンチマーク) 推論能力を評価するために、VQAv2 を含むいくつかの一般的なベンチマークを使用しました。 OKVQA、GQA、OCRVQA 、VizWiz、POPE、MME、MMBench、MM-Vet。さらに、タスク計画、プロンプトタスク計画、長距離タスク計画、操縦性判断、性的生成、過去の記述および操縦性などのロボットタスクをカバーする、RoboVQA の 18k 検証データセット上で RoboMamba のロボット関連の推論機能も直接評価しました。未来予測など。表 1. 複数のベンチマークにおける Robomamba と既存の MLLMS の比較。
ここで、N はトレーニング サンプルの数を表し、Tr (A) は行列 A のトレースを表します。 RoboMamba は、画像内の接触ピクセルの 2D 位置 (x、y) のみを予測し、深度情報を使用してそれを 3D 空間に変換します。この微調整戦略を評価するために、SAPIEN シミュレーションを使用して 10,000 のエンドエフェクターのポーズ予測のデータセットを生成しました。 運用の微調整の結果、RoboMamba が十分な推論能力を備えていれば、非常に効率的な微調整を通じて姿勢予測スキルを獲得できることがわかりました。最小限の微調整パラメーター (7MB) と効率的なモデル設計により、わずか 20 分で新しい操作スキルの学習を達成できます。この発見は、運用スキルを学習する際の推論能力の重要性を強調し、MLLM 本来の推論能力に影響を与えることなく、MLLM に運用能力を効率的に与えることができるという新しい視点を提案しています。最後に、RoboMamba は、常識およびロボット関連の推論に言語応答を使用し、アクション ポーズの予測にポリシー ヘッドを使用できます。 1. 一般的な推論能力の評価 (MLLM ベンチマーク) 推論能力を評価するために、VQAv2 を含むいくつかの一般的なベンチマークを使用しました。 OKVQA、GQA、OCRVQA 、VizWiz、POPE、MME、MMBench、MM-Vet。さらに、タスク計画、プロンプトタスク計画、長距離タスク計画、操縦性判断、性的生成、過去の記述および操縦性などのロボットタスクをカバーする、RoboVQA の 18k 検証データセット上で RoboMamba のロボット関連の推論機能も直接評価しました。未来予測など。表 1. 複数のベンチマークにおける Robomamba と既存の MLLMS の比較。 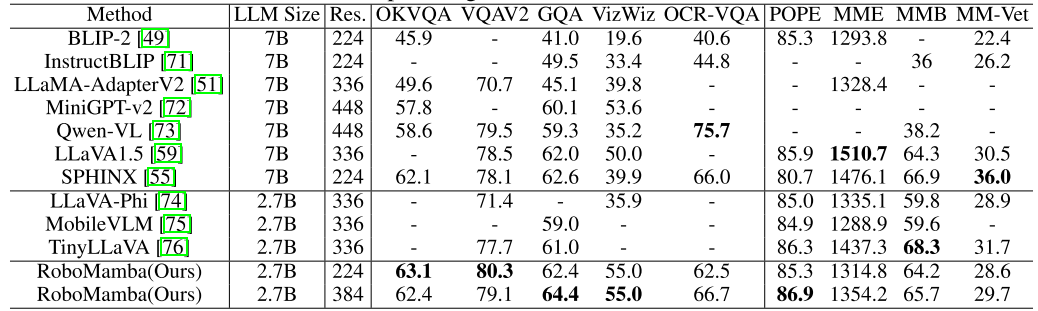 表 1 に示すように、一般的な VQA および最近の MLLM ベンチマークで RoboMamba を以前の最先端 (SOTA) MLLM と比較します。まず、RoboMamba は 2.7B 言語モデルのみを使用して、すべての VQA ベンチマークで満足のいく結果を達成していることがわかります。結果は、単純な構造設計が有効であることを示しています。調整された事前トレーニングと命令の共同トレーニングにより、MLLM の推論機能が大幅に向上します。たとえば、GQA ベンチマークにおける RoboMamba の空間認識パフォーマンスは、協調トレーニング段階での大量のロボット データの導入により向上しています。一方で、私たちは最近提案された MLLM ベンチマークでも RoboMamba をテストしました。以前の MLLM と比較すると、私たちのモデルはすべてのベンチマークで競争力のある結果を達成していることがわかります。 RoboMamba の一部のパフォーマンスは最先端の 7B MLLM (LLaVA1.5 や SPHINX など) よりもまだ低いですが、ロボット モデルの効率のバランスをとるために、より小型で高速な Mamba-2.7B を優先します。将来的には、リソースに制約のないシナリオ向けに RoboMamba-7B を開発する予定です。
表 1 に示すように、一般的な VQA および最近の MLLM ベンチマークで RoboMamba を以前の最先端 (SOTA) MLLM と比較します。まず、RoboMamba は 2.7B 言語モデルのみを使用して、すべての VQA ベンチマークで満足のいく結果を達成していることがわかります。結果は、単純な構造設計が有効であることを示しています。調整された事前トレーニングと命令の共同トレーニングにより、MLLM の推論機能が大幅に向上します。たとえば、GQA ベンチマークにおける RoboMamba の空間認識パフォーマンスは、協調トレーニング段階での大量のロボット データの導入により向上しています。一方で、私たちは最近提案された MLLM ベンチマークでも RoboMamba をテストしました。以前の MLLM と比較すると、私たちのモデルはすべてのベンチマークで競争力のある結果を達成していることがわかります。 RoboMamba の一部のパフォーマンスは最先端の 7B MLLM (LLaVA1.5 や SPHINX など) よりもまだ低いですが、ロボット モデルの効率のバランスをとるために、より小型で高速な Mamba-2.7B を優先します。将来的には、リソースに制約のないシナリオ向けに RoboMamba-7B を開発する予定です。 2. ロボット推論能力評価(RoboVQAベンチマーク)
また、RoboMambaのロボット関連推論能力を総合的に比較するため、RoboVQA検証セット上でLLaMA-AdapterV2を用いてベンチマークを実施しました。 LLaMA-AdapterV2 が現在の SOTA ロボット MLLM (ManipLLM) のベース モデルであるため、ベースラインとして LLaMA-AdapterV2 を選択します。公平な比較のために、LLaMA-AdapterV2 の事前トレーニング済みパラメーターをロードし、公式の命令微調整メソッドを使用して、2 エポックの RoboVQA トレーニング セット上で微調整しました。図 4a) に示すように、RoboMamba は BLEU-1 から BLEU-4 までの間で優れたパフォーマンスを実現します。結果は、私たちのモデルが高度なロボット関連の推論機能を備えていることを示し、トレーニング戦略の有効性を裏付けています。より高い精度に加えて、私たちのモデルは、LLaMA-AdapterV2 や ManipLLM よりも最大 7 倍速い推論速度を達成します。これは、Mamba 言語モデルのコンテンツを意識した推論機能と効率によるものと考えられます。図 4. RoboVQA でのロボット関連の推論の比較。  3. ロボット操作能力評価 (SAPIEN)
3. ロボット操作能力評価 (SAPIEN)
RoboMamba の操作能力を評価するために、UMPNet、Flowbot3D、RoboFlamingo、ManipLLM の 4 つのベースラインとモデルを比較しました。比較する前に、すべてのベースラインを再現し、収集したデータセットでトレーニングします。 UMPNet の場合、オブジェクトの表面に垂直な方向の予測された接触点に対して操作を実行します。 Flowbot3D は、点群上の動きの方向を予測し、最大の流れを相互作用点として選択し、流れの方向を使用してエンド エフェクターの方向を表します。 RoboFlamingo と ManipLLM は、OpenFlamingo と LLaMA-AdapterV2 の事前トレーニング パラメーターをそれぞれ読み込み、それぞれの微調整およびモデル更新戦略に従います。表 2 に示すように、以前の SOTA ManipLLM と比較して、当社の RoboMamba は、可視カテゴリで 7.0% の改善、非可視カテゴリで 2.0% の改善を達成しました。効率の点では、RoboFlamingo はモデル パラメーターの 35.5% (1.8B) を更新し、ManipLLM はモデル パラメーターの 0.5% を含む LLM (41.3M) のアダプターを更新しますが、微調整されたポリシー ヘッド (370 万) はモデル パラメーターの 0.1 のみを考慮します。 %。 RoboMamba は、以前の MLLM ベースのメソッドよりも 10 倍少ないパラメータを更新しながら、7 倍高速に推論します。結果は、私たちの RoboMamba が強力な推論能力を備えているだけでなく、低コストの方法で操作能力も獲得できることを示しています。 table表2.ロボマンバと他のベースラインの成功率の比較
図 4 に示すように、さまざまなロボットの下流タスクにおける RoboMamba の推論結果を視覚化します。タスク計画の面では、LLaMA-AdapterV2 と比較して、RoboMamba はその強力な推論機能により、より正確で長期的な計画能力を実証しました。公平な比較のために、RoboVQA データセットのベースライン LLaMA-AdapterV2 も微調整しました。操作ポーズの予測では、フランカ エミカ ロボット アームを使用してさまざまな家庭用物体と対話しました。図の右下隅に示すように、接触点を表す赤い点と方向を表すエンド エフェクターを使用して、RoboMamba によって予測された 3D ポーズを 2D 画像に投影します。

以上が北京大学が新しいマルチモーダルロボットモデルを発表!一般シナリオおよびロボットシナリオに対する効率的な推論と操作の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 이 포함되는 경우가 많습니다. 예를 들어, "테이블을 치우는 방법"과 같은 계획 문제에 직면하면 일반적으로 "1단계: 물건 집어들기" 및 "2단계: 상자에 물건 넣기"와 같은 단계가 포함됩니다. 행동 예측을 위해 효율적이고 간단한 정책 헤드 π를 활용하여 행동을 예측합니다
이 포함되는 경우가 많습니다. 예를 들어, "테이블을 치우는 방법"과 같은 계획 문제에 직면하면 일반적으로 "1단계: 물건 집어들기" 및 "2단계: 상자에 물건 넣기"와 같은 단계가 포함됩니다. 행동 예측을 위해 효율적이고 간단한 정책 헤드 π를 활용하여 행동을 예측합니다















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



