


特定の種類の画像に特化した、無料でオープンソースの AI テキスト画像ジェネレーターがインターネット上で利用可能です。そこで、私たちは山を調べて、今すぐ試せる最高のオープンソース AI テキスト変換ジェネレーターを見つけました。
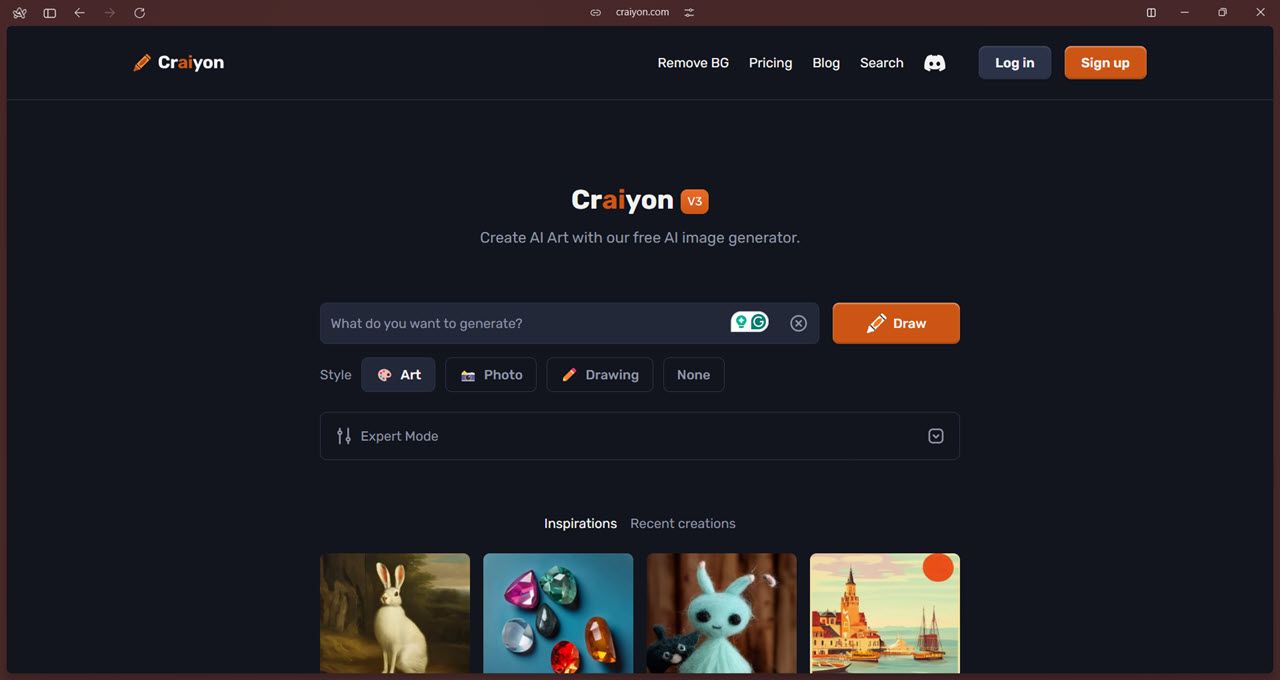
Craiyon は、最も簡単にアクセスできるオープンソース AI 画像ジェネレーターの 1 つです。これは DALL-E Mini をベースにしており、Github リポジトリを複製してモデルをコンピュータにローカルにインストールすることもできますが、Craiyon はその Web サイトを優先してこのアプローチを廃止したようです。
公式 Github リポジトリは 2022 年 6 月以降更新されていませんが、最新モデルは依然として Craiyon の公式サイトで無料で入手できます。 Android や iOS のアプリもありません。
機能の面では、AI 画像ジェネレーターに期待される通常のオプションがすべて表示されます。プロンプトを入力して画像を取得したら、アップスケール機能を使用して高解像度のコピーを取得できます。アート、写真、描画の 3 つのスタイルから選択できます。モデルに決定させたい場合は、「なし」オプションを選択することもできます。
さらに、「エキスパート モード」では、特定の項目を避けるようにモデルに指示する否定的な単語を含めることができます。また、ChatGPT を使用してユーザーが可能な限り最適かつ詳細なプロンプトを作成できるようにするプロンプト予測機能もあります。最後に、AI を活用した背景の削除機能は、画像から背景を切り取る時間と労力を節約するのに役立ちます。
これが Craiyon のすべての活動です。これは最も洗練された AI 画像生成モデルではありませんが、詳細や現実的なものを必要としない場合は、基本モデルとして十分に機能します。
モデルは無料で使用できますが、無料ユーザーは 1 分以内に一度に 9 枚の無料画像に制限されています。サポーターまたはプロフェッショナル レベル (価格はそれぞれ月額 5 ドルと 20 ドルで、毎年請求されます) に登録すると、広告や透かしが表示されなくなり、生成が高速化され、生成された画像を非公開にするオプションが利用できます。カスタム サブスクリプション層では、カスタム モデル、統合、専用サポート、プライベート サーバーも利用できます。
Stable Diffusion は、おそらく最も人気のあるオープンソースのテキストから画像への生成モデルの 1 つです。また、以下で説明する 3 つの画像ジェネレーターを含む他のモデルにも使用されます。 2022 年にリリースされ、それ以来多くの実装が行われてきました。
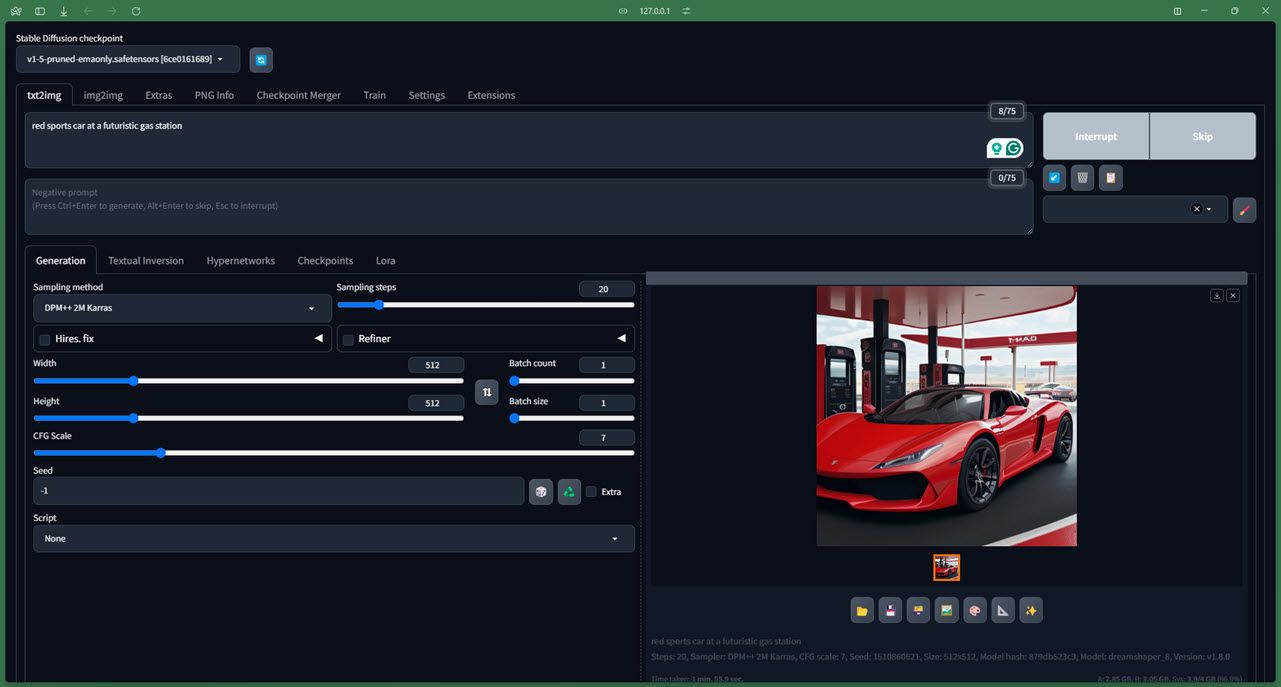
モデルがどのように機能するかについての過度に技術的な詳細については割愛します (公式 Github リポジトリをチェックしてください) が、このモデルは完全な初心者でも簡単にインストールでき、少なくとも 4GB のメモリを搭載した専用 GPU。 Stable Diffusion にはオンラインでアクセスすることもできます。Mac 上で Stable Diffusion を実行したい場合も対応します。
安定した拡散に使用できるチェックポイント (バージョンと考えてください) がいくつかあります。私たちはバージョン 1.5 をテストしましたが、バージョン 2.1 も現在開発中であり、より正確です。

モデルの実行もかなり簡単です。 AUTOMATIC1111 Stable Diffusion Web ユーザー インターフェイスを使用してテストしたところ、すべてのコントロールとパラメーターが正常に機能しました。また、モデルがトレーニングされた LAION-5B データベースのおかげで、非常に NSFW 耐性があります (ただし、完璧ではありません、念のため)。生成時間自体はハードウェアによって異なりますが、基本的なプロンプトを使用した場合でも、画像が詳細でリアルなものになることが期待できます。
DreamShaper は、安定拡散に基づいた画像生成モデルです。これは、MidJourney のオープンソースの代替として意図されており、生成された画像のフォトリアリズムに焦点を当てていますが、いくつかの調整でアニメや絵画スタイルも同様に処理できます。
このモデルは Stable Diffusion よりも優れた機能を備えており、ユーザーは、大幅な改善から NSFW 制限の緩和に至るまで、最終出力をより自由に設定できます。モデルの実行も簡単で、ダウンロード可能な事前トレーニング済みバージョンをオンラインでローカル アクセスできるほか、Sinkin.ai、RandomSeed、Mage.space (基本サブスクリプションが必要) などの多数の Web サイトでモデルを実行できます。 GPUの高速化。
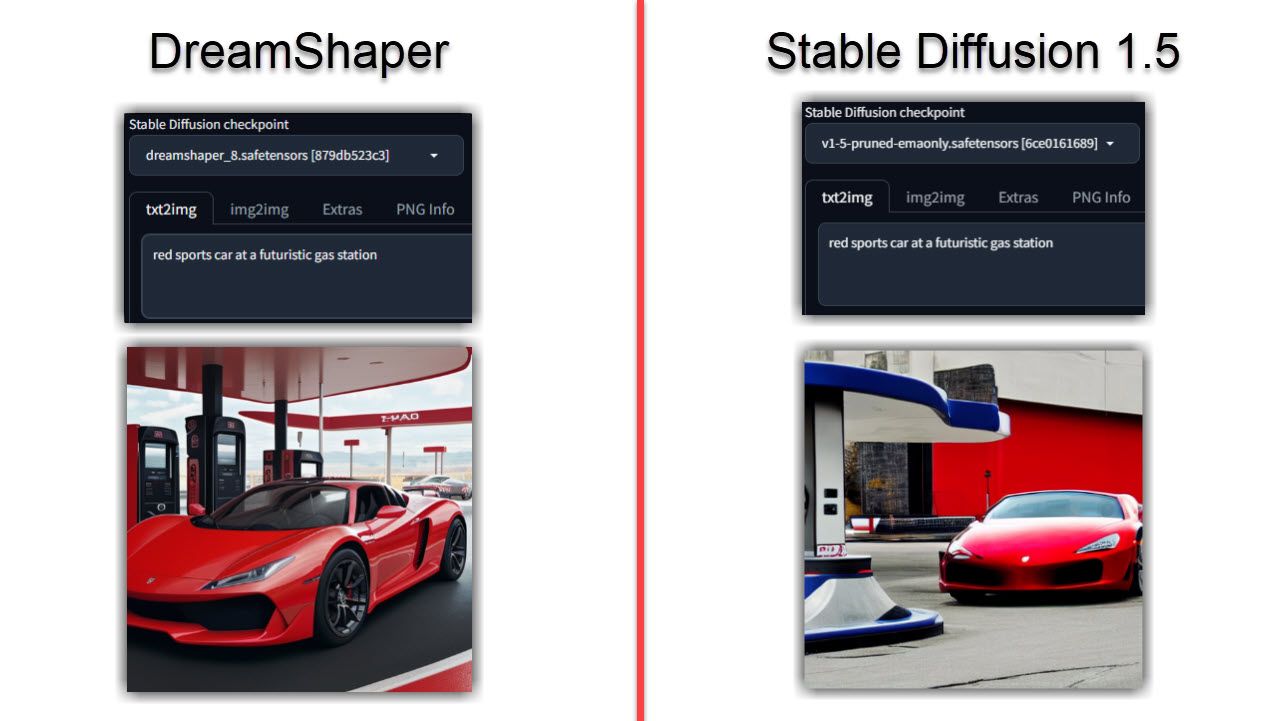
もうおわかりかと思いますが、DreamShaper によって生成された画像は、安定した拡散に比べてよりリアルに見える傾向があります。両方のモデルで同じプロンプトを実行した場合でも、DreamShaper モデルの方がより現実的で、詳細で、照明がより適切になる可能性があります。
これはポートレートやキャラクターに特に当てはまり、同じプロンプトと比較して安定した拡散には欠けていることがわかりました。画像がリアルになりすぎる場合は、AI によって生成された画像を識別する 4 つの方法をご紹介します。
モデルを実行するために巨大な PC も必要ありません。 4GB VRAM を搭載した私の GTX 1650Ti は、このモデルを完璧に実行しました。生成時間は少し長くなりましたが、実際の出力には影響しないようでした。ただし、Stable Diffusion XL モデルに基づく DreamShaper XL を実行するには、より多くの VRAM を備えた GPU が必要になる場合があります。
Invoke AI は、Stable Diffusion に基づいた別の AI ベースの画像生成モデルであり、Stable Diffusion XL に基づいた XL バージョンがあります。また、独自の Web およびコマンド ライン ユーザー インターフェイスも備えているため、Stable Diffusion Web UI などで苦労する必要はありません。
このモデルは、ユーザーがカスタマイズされたワークフローを使用して知的財産に基づいてビジュアルを作成できるようにすることに重点を置いています。 InvokeAI は、カスタム モデルのトレーニングや知的財産の操作に最適なオープンソース AI 画像生成モデルの 1 つです。
その公式 Github リポジトリには 2 つのインストール方法がリストされています。InvokeAI のインストーラーを介してインストールするか、ターミナルと Python に慣れていて、モデルとともにインストールされるパッケージをさらに制御する必要がある場合は PyPI を使用します。
ただし、追加の制御にはいくつかの制限があり、特にハードウェア要件が厳しくなります。 InvokeAI は、少なくとも 4 GB のメモリを備えた専用 GPU を推奨します。XL バリアントの実行には 6 ~ 8 GB のメモリが推奨されます。 VRAM 要件は、AMD GPU と Nvidia GPU の両方に適用されます。また、モデル、その依存関係、および Python 用に、少なくとも 12 GB の RAM と 12 GB の空きディスク領域も必要です。

ドキュメントでは、ビデオ メモリが不足しているため Nvidia の GTX 10 シリーズおよび 16 シリーズ GPU を推奨していませんが、提供されたインストーラーは問題なく動作しました。使用頻度はさまざまですが、ローエンド GPU を使用している場合は、プロンプトが画像に変換されるのを確認するまでに長い時間がかかることが予想されます。最後に、Windows を使用している場合は、現在 AMD GPU がサポートされていないため、Nvidia GPU のみを使用できます。
画像生成部分では、モデルはフォトリアリズムよりも芸術的なスタイルに傾く傾向があります。もちろん、特に製品デザイン、建築、小売スペースで作業している場合は、データセット上でモデルをトレーニングし、フォトリアリスティックな画像が含まれる場合でも、希望に近い画像を生成させることができます。ただし、覚えておくべき重要な点は、InvokeAI は主に画像生成エンジンであるということです。つまり、最良の結果を得るには、独自のモデル (Web インターフェイスで提供されるモデル マネージャーを介して簡単に見つかります) をデフォルトとして使用する必要がある可能性があります。モデルは安定拡散自体と非常によく似ています。
Openjourney は、やはり Stable Diffusion に基づいた、無料のオープンソース AI 画像生成モデルです。このモデルがなぜ Openjourney と呼ばれているのか疑問に思っている場合は、このモデルが Midjourney 画像でトレーニングされており、生成される画像でそのスタイルを模倣できるためです。
Openjourney の背後にある会社である PromptHero を使用すると、Stable Diffusion (バージョン 1.5 および 2)、DreamShaper、Realistic Vision などの他のモデルと並行してモデルをテストできます。サインアップすると、25 の無料クレジット (生成される画像ごとに 1 クレジット) を取得できます。その後、プロ サブスクリプション層に登録する必要があります。これは月額 9 ドルで、他の限定機能を備えた毎月 300 クレジットにアクセスできます。

ただし、ローカルで無料で実行したい場合は、HuggingFace からモデル ファイルをダウンロードし、Stable Diffusion Web UI を使用して実行できます。 Openjourney は、HuggingFace 上で Stable Diffusion に次いで 2 番目にダウンロード数の多い AI 画像生成モデルでもあります。
Openjourney の Web サイトにはモデルをローカルで実行するための具体的なハードウェア要件が記載されていませんが、Stable Diffusion と同様のハードウェア要件が期待できます。これは、モデルとその依存関係を保存するために、4 GB VRAM、16 GB RAM、およびコンピューター上に約 12 ~ 15 GB の空き領域を備えた専用 GPU を意味します。

Openjourney によって生成された画像は、特に指定がない限り、フォトリアリズムとアートの間でバランスが保たれる傾向があります。オールラウンドなモデルを探していて、サブスクリプションを支払わずに Midjourney のルック アンド フィールを好む場合は、Openjourney が最良の選択肢の 1 つです。
以上がベスト 5 のオープンソース AI 画像ジェネレーターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



