10000 contenu connexe trouvé

L'application d'apprentissage automatique de Golang pour l'apprentissage par renforcement
Présentation de l'article:Introduction à l'application d'apprentissage automatique de Golang dans l'apprentissage par renforcement L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend un comportement optimal en interagissant avec l'environnement et en fonction des commentaires de récompense. Le langage Go possède des fonctionnalités telles que le parallélisme, la concurrence et la sécurité de la mémoire, ce qui lui confère un avantage dans l'apprentissage par renforcement. Cas pratique : Apprentissage par renforcement Go Dans ce tutoriel, nous utiliserons le langage Go et l'algorithme AlphaZero pour implémenter un modèle d'apprentissage par renforcement Go. Étape 1 : Installer les dépendances gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
commentaire 0
505

Problèmes de conception de récompense dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la conception des récompenses dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est une méthode d'apprentissage automatique dont l'objectif est d'apprendre à prendre des mesures qui maximisent les récompenses cumulatives grâce à l'interaction avec l'environnement. Dans l’apprentissage par renforcement, la récompense joue un rôle crucial. Elle constitue un signal dans le processus d’apprentissage de l’agent et sert à guider son comportement. Cependant, la conception des récompenses est un problème difficile, et une conception raisonnable des récompenses peut grandement affecter les performances des algorithmes d’apprentissage par renforcement. Dans l’apprentissage par renforcement, les récompenses peuvent être considérées comme l’agent contre l’environnement.
2023-10-08
commentaire 0
1436

Problèmes de sélection d'algorithmes dans l'apprentissage par renforcement
Présentation de l'article:Le problème de la sélection d'algorithmes dans l'apprentissage par renforcement nécessite des exemples de code spécifiques. L'apprentissage par renforcement est un domaine de l'apprentissage automatique qui apprend des stratégies optimales grâce à l'interaction entre l'agent et l'environnement. Dans l’apprentissage par renforcement, le choix d’un algorithme approprié est crucial pour l’effet d’apprentissage. Dans cet article, nous explorons les problèmes de sélection d’algorithmes dans l’apprentissage par renforcement et fournissons des exemples de code concrets. Il existe de nombreux algorithmes parmi lesquels choisir en apprentissage par renforcement, tels que Q-Learning, DeepQNetwork (DQN), Actor-Critic, etc. Choisissez le bon algorithme
2023-10-08
commentaire 0
1189

Comment créer un algorithme d'apprentissage par renforcement en utilisant PHP
Présentation de l'article:Comment créer un algorithme d'apprentissage par renforcement à l'aide de PHP Introduction : L'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions optimales en interagissant avec l'environnement. Dans cet article, nous présenterons comment créer des algorithmes d'apprentissage par renforcement à l'aide du langage de programmation PHP et fournirons des exemples de code pour aider les lecteurs à mieux comprendre. 1. Qu'est-ce qu'un algorithme d'apprentissage par renforcement ? L'algorithme d'apprentissage par renforcement est une méthode d'apprentissage automatique qui apprend à prendre des décisions en observant les commentaires de l'environnement. Contrairement à d’autres algorithmes d’apprentissage automatique, les algorithmes d’apprentissage par renforcement ne sont pas uniquement basés sur des données existantes.
2023-07-31
commentaire 0
701

Technologie d'apprentissage par renforcement profond en C++
Présentation de l'article:La technologie d'apprentissage par renforcement profond est une branche de l'intelligence artificielle qui a beaucoup retenu l'attention. Elle a remporté de nombreux concours internationaux et est également largement utilisée dans les assistants personnels, la conduite autonome, l'intelligence des jeux et d'autres domaines. Dans le processus de réalisation d’un apprentissage par renforcement profond, le C++, en tant que langage de programmation efficace et excellent, est particulièrement important lorsque les ressources matérielles sont limitées. L’apprentissage par renforcement profond, comme son nom l’indique, combine les technologies des deux domaines de l’apprentissage profond et de l’apprentissage par renforcement. Pour comprendre simplement, l'apprentissage profond fait référence à l'apprentissage de fonctionnalités à partir de données et à la prise de décisions en créant un réseau neuronal multicouche.
2023-08-21
commentaire 0
1122

Définition, classification et cadre algorithmique de l'apprentissage par renforcement
Présentation de l'article:L'apprentissage par renforcement (RL) est un algorithme d'apprentissage automatique entre l'apprentissage supervisé et l'apprentissage non supervisé. Il résout les problèmes par essais, erreurs et apprentissage. Pendant la formation, l'apprentissage par renforcement prend une série de décisions et est récompensé ou puni en fonction des actions effectuées. Le but est de maximiser la récompense totale. L'apprentissage par renforcement a la capacité d'apprendre de manière autonome et de s'adapter, et peut prendre des décisions optimisées dans des environnements dynamiques. Comparé à l'apprentissage supervisé traditionnel, l'apprentissage par renforcement est plus adapté aux problèmes sans étiquettes claires et peut donner de bons résultats dans les problèmes de prise de décision à long terme. À la base, l’apprentissage par renforcement consiste à appliquer des actions basées sur des actions effectuées par un agent, qui est récompensé en fonction de l’impact positif de ses actions sur un objectif global. Il existe deux principaux types d'algorithmes d'apprentissage par renforcement : les algorithmes d'apprentissage basés sur un modèle et ceux sans modèle.
2024-01-24
commentaire 0
690

Qu'est-ce que l'apprentissage par renforcement profond en Python ?
Présentation de l'article:Qu’est-ce que l’apprentissage par renforcement profond en Python ? L’apprentissage par renforcement profond (DRL) est devenu ces dernières années un axe de recherche clé dans le domaine de l’intelligence artificielle, en particulier dans des applications telles que les jeux, les robots et le traitement du langage naturel. Les bibliothèques d'apprentissage par renforcement et de deep learning basées sur le langage Python, comme TensorFlow, PyTorch, Keras, etc., nous permettent d'implémenter plus facilement les algorithmes DRL. Le fondement théorique de l’apprentissage par renforcement profond
2023-06-04
commentaire 0
1804

Problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement
Présentation de l'article:Problèmes de conception de fonctions de récompense dans l'apprentissage par renforcement Introduction L'apprentissage par renforcement est une méthode qui apprend des stratégies optimales grâce à l'interaction entre un agent et l'environnement. Dans l’apprentissage par renforcement, la conception de la fonction de récompense est cruciale pour l’effet d’apprentissage de l’agent. Cet article explorera les problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement et fournira des exemples de code spécifiques. Le rôle de la fonction de récompense et de la fonction de récompense cible constituent une partie importante de l'apprentissage par renforcement et sont utilisés pour évaluer la valeur de récompense obtenue par l'agent dans un certain état. Sa conception aide à guider l'agent pour maximiser la fatigue à long terme en choisissant les actions optimales.
2023-10-09
commentaire 0
1716

apprentissage par renforcement hiérarchique
Présentation de l'article:L'apprentissage par renforcement hiérarchique (HRL) est une méthode d'apprentissage par renforcement qui apprend les comportements et les décisions de haut niveau de manière hiérarchique. Différent des méthodes traditionnelles d'apprentissage par renforcement, HRL décompose la tâche en plusieurs sous-tâches, apprend une stratégie locale dans chaque sous-tâche, puis combine ces stratégies locales pour former une stratégie globale. Cette méthode d'apprentissage hiérarchique peut réduire les difficultés d'apprentissage causées par des environnements de grande dimension et des tâches complexes, et améliorer l'efficacité et les performances de l'apprentissage. Grâce à des stratégies hiérarchiques, HRL peut prendre des décisions à différents niveaux pour atteindre des comportements intelligents de niveau supérieur. Cette approche trouve des applications dans de nombreux domaines tels que le contrôle des robots, le gameplay et la conduite autonome.
2024-01-22
commentaire 0
1405

Quels sont les algorithmes d'apprentissage par renforcement en Python ?
Présentation de l'article:Avec le développement de la technologie de l'intelligence artificielle, l'apprentissage par renforcement, en tant que technologie importante de l'intelligence artificielle, a été largement utilisé dans de nombreux domaines, tels que les systèmes de contrôle, les jeux, etc. En tant que langage de programmation populaire, Python permet également la mise en œuvre de nombreux algorithmes d'apprentissage par renforcement. Cet article présentera les algorithmes d'apprentissage par renforcement couramment utilisés et leurs caractéristiques en Python. Q-learningQ-learning est un algorithme d'apprentissage par renforcement basé sur une fonction de valeur. Il guide les stratégies comportementales en apprenant une fonction de valeur, permettant à l'agent de choisir dans l'environnement.
2023-06-04
commentaire 0
1407

Apprentissage automatique : les 19 meilleurs projets d'apprentissage par renforcement (RL) sur Github
Présentation de l'article:L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique dans laquelle les agents apprennent par essais et erreurs. Les algorithmes d’apprentissage par renforcement sont utilisés dans de nombreux domaines, tels que les jeux, la robotique et la finance. L'objectif de RL est de découvrir une stratégie qui maximise les rendements attendus à long terme. Les algorithmes d’apprentissage par renforcement sont généralement divisés en deux catégories : basés sur un modèle et sans modèle. Les algorithmes basés sur des modèles utilisent des modèles environnementaux pour planifier des voies d'action optimales. Cette approche repose sur une modélisation précise de l'environnement, puis sur l'utilisation du modèle pour prédire les résultats de différentes actions. En revanche, les algorithmes sans modèle apprennent directement des interactions avec l’environnement et ne nécessitent pas de modélisation explicite de l’environnement. Cette méthode est plus adaptée aux situations où le modèle d’environnement est difficile à obtenir ou imprécis. En comparaison réelle, les algorithmes d’apprentissage par renforcement sans modèle ne
2024-03-19
commentaire 0
919

Comment utiliser le langage Go pour mener des recherches sur l'apprentissage par renforcement profond ?
Présentation de l'article:L'apprentissage par renforcement profond (DeepReinforcementLearning) est une technologie avancée qui combine l'apprentissage en profondeur et l'apprentissage par renforcement. Elle est largement utilisée dans la reconnaissance vocale, la reconnaissance d'images, le traitement du langage naturel et d'autres domaines. En tant que langage de programmation rapide, efficace et fiable, le langage Go peut apporter une aide à la recherche sur l’apprentissage par renforcement profond. Cet article expliquera comment utiliser le langage Go pour mener des recherches sur l'apprentissage par renforcement profond. 1. Installez le langage Go et les bibliothèques associées et commencez à utiliser le langage Go pour un apprentissage par renforcement en profondeur.
2023-06-10
commentaire 0
1200
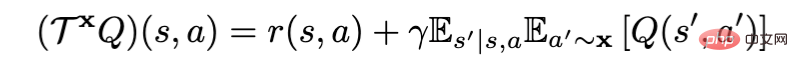
Un nouveau paradigme pour l'apprentissage par renforcement hors ligne ! JD.com et l'Université Tsinghua proposent un algorithme d'apprentissage découplé
Présentation de l'article:L'algorithme d'apprentissage par renforcement hors ligne (Offline RL) est l'une des sous-directions les plus populaires de l'apprentissage par renforcement. L'apprentissage par renforcement hors ligne n'interagit pas avec l'environnement et vise à apprendre les politiques cibles à partir de données précédemment enregistrées. L'apprentissage par renforcement hors ligne est particulièrement intéressant par rapport à l'apprentissage par renforcement en ligne (Online RL) dans les domaines où la collecte de données est coûteuse ou dangereuse, mais où il peut y avoir une grande quantité de données (par exemple, robotique, contrôle industriel, conduite autonome). Lors de l'utilisation de l'opérateur d'évaluation de politique Bellman pour l'évaluation de politique, l'algorithme d'apprentissage par renforcement hors ligne actuel peut être divisé en basé sur RL (x = π) et basé sur l'imitation (x = μ) en fonction de la différence de X, où π est la cible. stratégie , μ est la stratégie comportementale
2023-04-11
commentaire 0
996

Transformers+world model, peut-il sauver l'apprentissage par renforcement profond ?
Présentation de l'article:Beaucoup de gens savent qu'AlphaGo, qui a vaincu Li Sedol, Ke Jie et d'autres grands joueurs d'échecs internationaux, a eu un total de trois itérations. Il s'agissait de l'AlphaGo Lee de première génération qui a vaincu Li Sedol, de l'AlphaGo Master de deuxième génération qui a vaincu Ke Jie. , et l'AlphaGo Master de deuxième génération qui a vaincu les deux premiers. La troisième génération d'AlphaGo Zero. La raison pour laquelle les compétences d’AlphaGo aux échecs peuvent augmenter de génération en génération est en fait due à une tendance évidente dans la technologie de l’IA, à savoir la proportion croissante d’apprentissage par renforcement. Ces dernières années, l'apprentissage par renforcement a connu une autre « évolution ». Les gens appellent l'apprentissage par renforcement « évolué » l'apprentissage par renforcement profond. Cependant, l’efficacité des échantillons d’agents d’apprentissage par renforcement profond est faible, ce qui limite considérablement leur application dans des problèmes pratiques. récent
2023-05-04
commentaire 0
1175

Une méthode pour optimiser l'AB à l'aide de l'apprentissage par renforcement du gradient politique
Présentation de l'article:Les tests AB sont une technique largement utilisée dans les expériences en ligne. Son objectif principal est de comparer deux ou plusieurs versions d'une page ou d'une application afin de déterminer quelle version atteint les meilleurs objectifs commerciaux. Ces objectifs peuvent être des taux de clics, des taux de conversion, etc. En revanche, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui utilise l’apprentissage par essais et erreurs pour optimiser les stratégies de prise de décision. L'apprentissage par renforcement par gradient de politiques est une méthode spéciale d'apprentissage par renforcement qui vise à maximiser les récompenses cumulatives en apprenant des politiques optimales. Les deux ont des applications différentes dans l’optimisation des objectifs commerciaux. Dans les tests AB, nous considérons les différentes versions de page comme différentes actions, et les objectifs commerciaux peuvent être considérés comme des indicateurs importants de signaux de récompense. Afin d'atteindre le maximum d'objectifs commerciaux, nous devons concevoir une stratégie capable de choisir
2024-01-24
commentaire 0
986

Comprendre l'apprentissage par renforcement et ses scénarios d'application
Présentation de l'article:La meilleure façon de dresser un chien est d’utiliser un système de récompense pour le récompenser pour son bon comportement et le punir pour son mauvais comportement. La même stratégie peut être utilisée pour l’apprentissage automatique, appelé apprentissage par renforcement. L'apprentissage par renforcement est une branche de l'apprentissage automatique qui entraîne des modèles grâce à la prise de décision pour trouver la meilleure solution à un problème. Pour améliorer la précision du modèle, des récompenses positives peuvent être utilisées pour encourager l’algorithme à se rapprocher de la bonne réponse, tandis que des récompenses négatives peuvent être attribuées pour punir les écarts par rapport à l’objectif. Il vous suffit de clarifier les objectifs, puis de modéliser les données. Le modèle commencera à interagir avec les données et proposera lui-même des solutions sans intervention manuelle. Exemple d'apprentissage par renforcement Prenons l'exemple du dressage de chiens. Nous fournissons des récompenses telles que des biscuits pour chien pour inciter le chien à effectuer diverses actions. Le chien recherche des récompenses selon une certaine stratégie, il suit donc les ordres et apprend de nouvelles actions, comme mendier.
2024-01-22
commentaire 0
1397

Comment effectuer un apprentissage par renforcement profond et une analyse du comportement des utilisateurs en PHP ?
Présentation de l'article:Avec le développement continu de la technologie du deep learning, l’intelligence artificielle est de plus en plus utilisée dans diverses industries. Parmi les différents langages de programmation, PHP, en tant que langage côté serveur populaire, peut également utiliser la technologie d'apprentissage par renforcement profond pour l'analyse du comportement des utilisateurs. L'apprentissage profond est une technologie d'apprentissage automatique qui découvre des modèles et des régularités en s'entraînant sur de grandes quantités de données. L'apprentissage par renforcement profond est une méthode qui combine l'apprentissage en profondeur et l'apprentissage par renforcement et est utilisée pour résoudre des problèmes de prise de décision complexes. Pour mettre en œuvre l'apprentissage par renforcement profond en PHP, vous devez utiliser les bibliothèques et boîtes PHP pertinentes.
2023-05-26
commentaire 0
993

Une autre révolution dans l'apprentissage par renforcement ! DeepMind propose une « distillation d'algorithmes » : un transformateur d'apprentissage par renforcement pré-entraîné explorable
Présentation de l'article:Transformer peut être considéré comme l'architecture de réseau neuronal la plus puissante pour les tâches de modélisation de séquence actuelles, et le modèle Transformer pré-entraîné peut utiliser des invites comme conditions ou un apprentissage en contexte pour s'adapter à différentes tâches en aval. La capacité de généralisation des modèles Transformer pré-entraînés à grande échelle a été vérifiée dans plusieurs domaines, tels que la complétion de texte, la compréhension du langage, la génération d'images, etc. Depuis l’année dernière, des travaux pertinents ont prouvé qu’en traitant l’apprentissage par renforcement hors ligne (RL hors ligne) comme un problème de prédiction de séquence, le modèle peut apprendre des politiques à partir de données hors ligne. Mais les approches actuelles soit apprennent les politiques à partir de données qui ne contiennent pas d'apprentissage
2023-04-12
commentaire 0
1839

Existe-t-il une version informatique de Xueqiangguo ?
Présentation de l'article:Xueqiangguo a une version informatique, qui est une version Web PC. Xuexueqiangguo est une plate-forme d'apprentissage en charge du Département de propagande du Comité central du Parti communiste chinois. Elle se compose de deux terminaux : les utilisateurs de PC et de PC mobiles peuvent se connecter au site Web ou effectuer des recherches et naviguer dans les moteurs de recherche, et les utilisateurs mobiles peuvent le télécharger et l'utiliser gratuitement via divers magasins d'applications mobiles. La version PC de Xuexueqiangguo compte plus de 180 colonnes de premier niveau réparties en 17 sections, dont « Apprendre de nouvelles idées », « Culture d'apprentissage » et « Perspective mondiale ».
2023-03-02
commentaire 0
27377

