


Le principal problème sur lequel se concentre ce document de discussion est l'application de la technologie de détection de cibles 3D dans le processus de conduite autonome. Bien que le développement de la technologie des caméras de vision environnementale fournisse des informations sémantiques haute résolution pour la détection d'objets 3D, cette méthode est limitée par des problèmes tels que l'incapacité de capturer avec précision les informations de profondeur et les mauvaises performances par mauvais temps ou dans des conditions de faible luminosité. En réponse à ce problème, la discussion a proposé une nouvelle méthode de détection de cible 3D multimode, RCBEVDet, qui combine des caméras à vision panoramique et des capteurs radar économiques à ondes millimétriques. Cette méthode fournit des informations sémantiques plus riches et une solution à des problèmes tels que de mauvaises performances par mauvais temps ou dans des conditions de faible luminosité en utilisant de manière exhaustive les informations provenant de plusieurs capteurs. En réponse à ce problème, la discussion a proposé une nouvelle méthode de détection de cible 3D multimode, RCBEVDet, qui combine des caméras à vision panoramique et des capteurs radar économiques à ondes millimétriques. En utilisant de manière exhaustive les informations provenant de capteurs multimodes, RCBEVDet est capable de fournir des informations sémantiques haute résolution et de présenter de bonnes performances dans des conditions météorologiques extrêmes ou de faible luminosité. Le cœur de cette méthode pour améliorer le
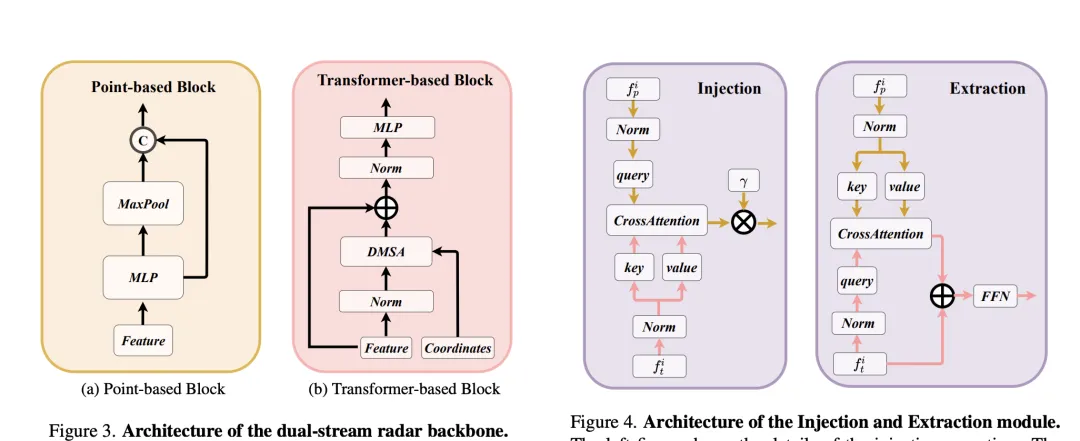
RCBEVDet automatique réside dans deux conceptions clés : RadarBEVNet et Cross-Attention+Multi-layer Fusion Module (CAMF). RadarBEVNet est conçu pour extraire efficacement les caractéristiques radar et comprend un encodeur BEV (Bird's Eye View) compatible RCS (Radar Cross Section) de réseau fédérateur de radar à double flux. Une telle conception utilise des codeurs basés sur des nuages de points et des transformateurs pour traiter les points radar, mettre à jour les caractéristiques des points radar de manière interactive et utiliser les caractéristiques RCS spécifiques au radar comme informations préalables sur la taille de la cible afin d'optimiser la distribution des caractéristiques ponctuelles dans l'espace BEV. Le module CAMF résout le problème d'erreur d'azimut des points radar grâce à un mécanisme d'attention croisée multimodal, réalisant un alignement dynamique des cartes de caractéristiques BEV du radar et des caméras et une fusion adaptative de caractéristiques multimodales grâce à la fusion de canaux et spatiale. Dans la mise en œuvre, la distribution des caractéristiques ponctuelles dans l'espace BEV est optimisée par mise à jour interactive des caractéristiques ponctuelles du radar et par utilisation des caractéristiques RCS spécifiques au radar comme informations préalables sur la taille de la cible. Le module CAMF résout le problème d'erreur d'azimut des points radar grâce à un mécanisme d'attention croisée multimodal, réalisant un alignement dynamique des cartes de caractéristiques BEV du radar et des caméras et une fusion adaptative de caractéristiques multimodales grâce à la fusion de canaux et spatiale.
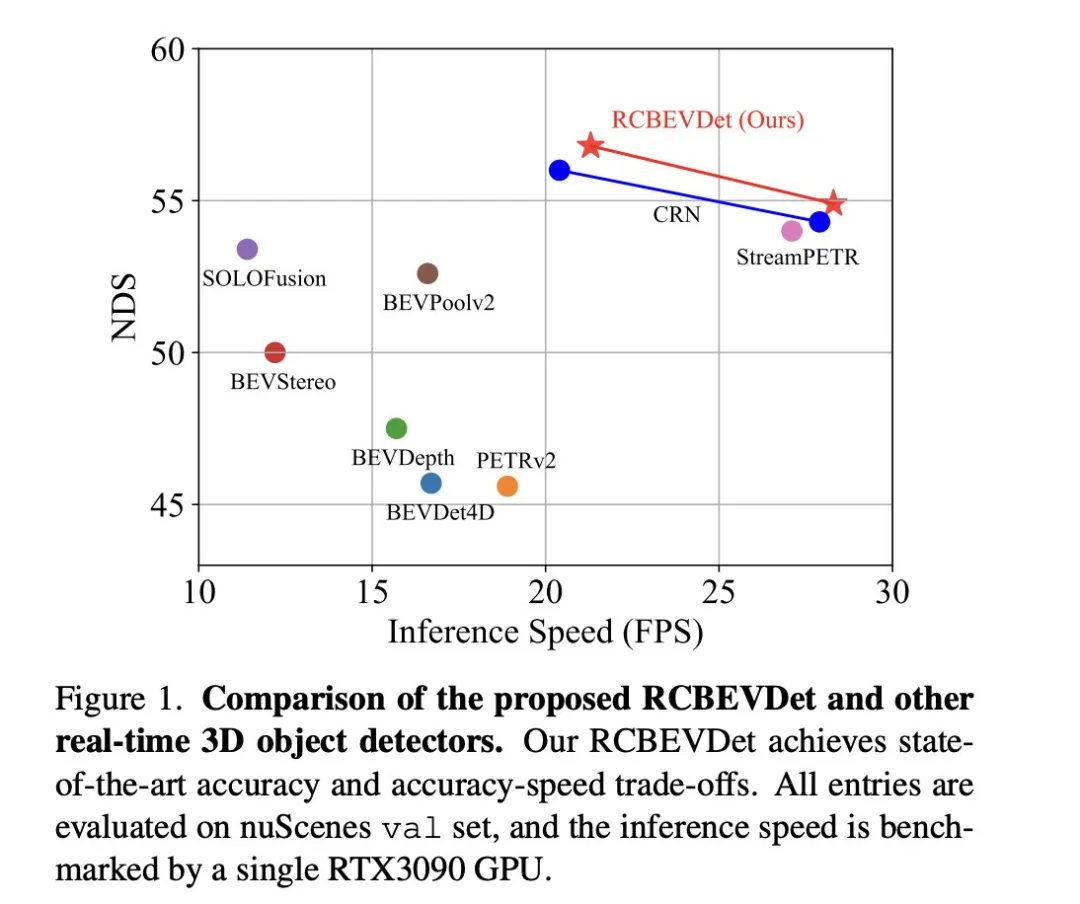
La nouvelle méthode proposée dans l'article résout les problèmes existants à travers les points suivants :
Les principales contributions de l'article sont les suivantes :
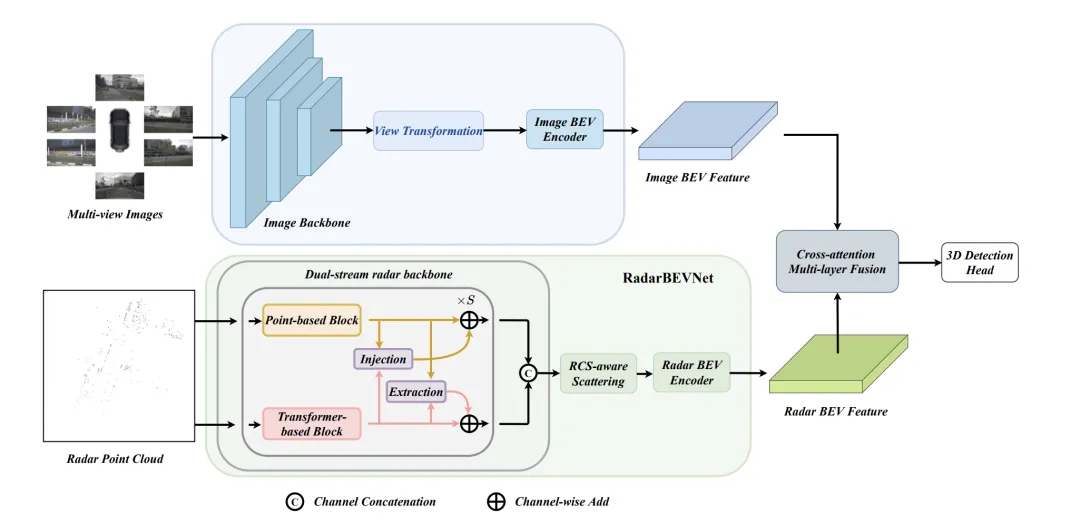
RadarBEVNet est une architecture de réseau proposée dans cet article pour l'extraction efficace des caractéristiques BEV (carte d'apparence des oiseaux). Elle comprend principalement deux composants de base : le double. Réseau de base de radar de flux et encodeur BEV compatible RCS (Radar Cross Section). Un réseau fédérateur de radar à double flux est utilisé pour extraire des représentations de caractéristiques riches à partir de données radar multicanaux. Il est construit sur un réseau neuronal convolutif profond (CNN), alternant entre des couches de convolution imbriquées et de regroupement pour les opérations d'extraction de caractéristiques et de réduction de dimensionnalité afin d'obtenir progressivement la dorsale radar à double flux
Afin de résoudre le problème de rareté des fonctionnalités BEV causé par les encodeurs BEV radar traditionnels, un encodeur BEV compatible RCS est proposé. Il utilise le RCS comme information préalable sur la taille de la cible et répartit les caractéristiques des points radar sur plusieurs pixels de l'espace BEV au lieu d'un seul pixel pour augmenter la densité des caractéristiques BEV. Ce processus est mis en œuvre à travers la formule suivante :
où est la carte de poids gaussienne BEV basée sur RCS, qui est optimisée en maximisant la carte de poids de tous les points radar. Enfin, les fonctionnalités obtenues par répartition RCS sont connectées et traitées par MLP pour obtenir les fonctionnalités BEV finales compatibles RCS.
Dans l'ensemble, RadarBEVNet extrait efficacement les caractéristiques des données radar en combinant le réseau fédérateur de radar à double flux et l'encodeur BEV compatible RCS, et utilise RCS comme a priori de la taille cible pour optimiser la distribution des caractéristiques de l'espace BEV, fournissant une base pour une fusion multimodale ultérieure constitue une base solide.
Le module de fusion multicouche à attention croisée (CAMF) est une structure de réseau avancée pour l'alignement dynamique et la fusion de fonctionnalités multimodales, en particulier pour le radar et l'alignement dynamique. et la conception de fusion des fonctionnalités Bird's Eye View (BEV) générées par la caméra. Ce module résout principalement le problème du désalignement des caractéristiques causé par l'erreur d'azimut des nuages de points radar. Grâce au mécanisme d'attention croisée déformable (Deformable Cross-Attention), il capture efficacement les petits écarts des points radar et réduit l'attention croisée standard. complexité informatique.
CAMF utilise un mécanisme d'attention croisée déformé pour aligner les caractéristiques BEV des caméras et des radars. Étant donné une somme de fonctionnalités BEV pour une caméra et un radar, les intégrations de positions apprenables sont d'abord ajoutées à la somme, puis converties en points de requête et de référence sous forme de clés et de valeurs. Le calcul de l'attention croisée de déformation multi-têtes peut être exprimé comme suit :
où représente l'indice de la tête d'attention, représente l'indice de la clé d'échantillonnage et est le nombre total de clés d'échantillonnage. Représente le décalage d'échantillonnage et est le poids d'attention calculé par et .
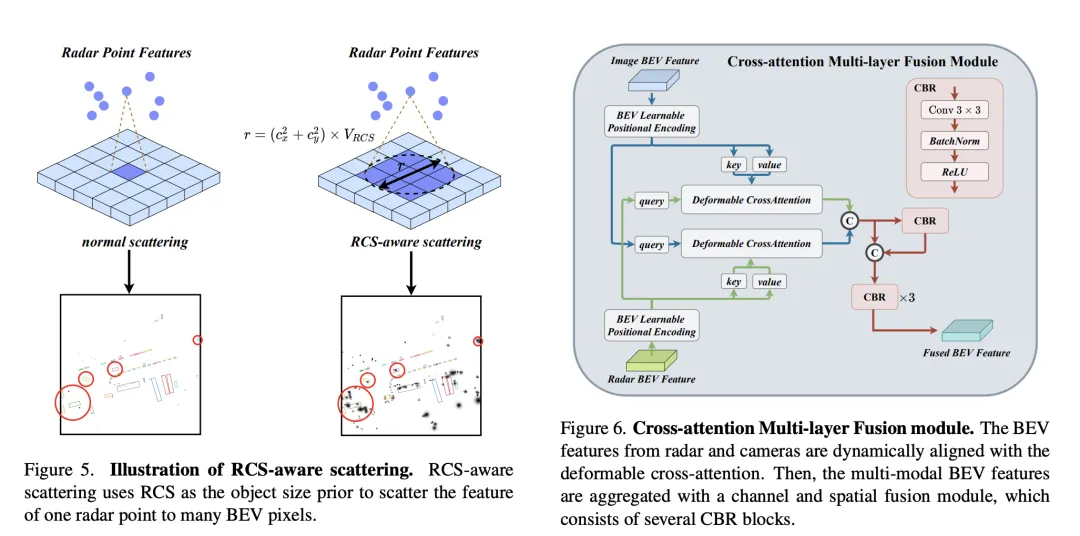
Après avoir aligné les fonctionnalités BEV de la caméra et du radar grâce à une attention croisée, CAMF utilise des couches de fusion de canaux et spatiales pour agréger les fonctionnalités BEV multimodales. Plus précisément, deux fonctionnalités BEV sont d'abord concaténées, puis introduites dans le bloc CBR (convolution-batch normalization-activation function) et les fonctionnalités fusionnées sont obtenues via une connexion résiduelle. Le bloc CBR se compose séquentiellement d'une couche convolutive, d'une couche de normalisation par lots et d'une fonction d'activation ReLU. Après cela, trois blocs CBR sont appliqués consécutivement pour fusionner davantage les fonctionnalités multimodales.
Grâce au processus ci-dessus, CAMF réalise efficacement un alignement précis et une fusion efficace des fonctionnalités du radar et de la caméra BEV, fournissant des informations riches et précises sur les fonctionnalités pour la détection de cibles 3D, améliorant ainsi les performances de détection.
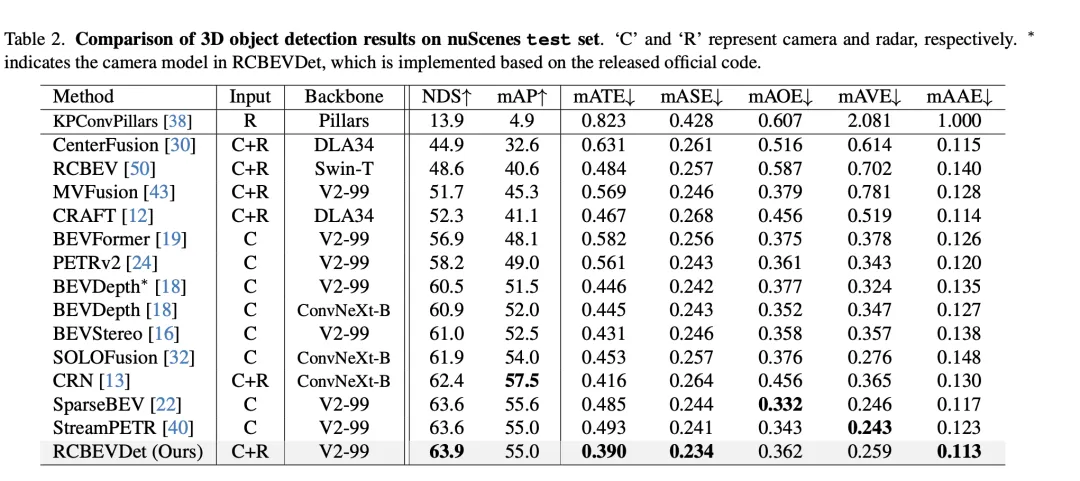
Dans la comparaison des résultats de détection de cibles 3D sur l'ensemble de validation VoD, RadarBEVNet a obtenu à la fois des performances de précision moyenne (mAP) dans l'ensemble de la zone d'annotation et dans la zone d'intérêt en fusionnant la caméra et données radar. Excellentes performances démontrées. Plus précisément, pour l'ensemble de la zone annotée, RadarBEVNet a atteint des valeurs AP de 40,63 %, 38,86 % et 70,48 % respectivement dans la détection des voitures, des piétons et des cyclistes, augmentant le mAP complet à 49,99 %. Dans la zone d'intérêt, c'est-à-dire dans le canal de conduite proche du véhicule, les performances de RadarBEVNet sont encore plus remarquables, atteignant 72,48 %, 49,89 % et 87,01 % des valeurs AP dans la détection des voitures, des piétons et cyclistes respectivement, et le mAP global a atteint 69,80 %.
Ces résultats révèlent plusieurs points clés. Premièrement, en fusionnant efficacement les entrées de la caméra et du radar, RadarBEVNet est en mesure de tirer pleinement parti des avantages complémentaires des deux capteurs et d'améliorer les performances globales de détection. Comparé aux méthodes qui utilisent uniquement le radar, telles que PointPillar et RadarPillarNet, RadarBEVNet présente une amélioration significative en termes de mAP complet, ce qui montre que la fusion multimodale est particulièrement importante pour améliorer la précision de la détection. Deuxièmement, RadarBEVNet fonctionne particulièrement bien dans les zones d'intérêt, ce qui est particulièrement critique pour les applications de conduite autonome, car les cibles dans les zones d'intérêt ont généralement le plus grand impact sur les décisions de conduite en temps réel. Enfin, bien que la valeur AP de RadarBEVNet soit légèrement inférieure à celle de certaines méthodes monomodales ou multimodales pour la détection des voitures et des piétons, RadarBEVNet montre ses avantages globaux en termes de performances en matière de détection des cyclistes et de performances mAP complètes. RadarBEVNet atteint d'excellentes performances sur l'ensemble de vérification VoD en fusionnant les données multimodales des caméras et des radars, démontrant notamment de fortes capacités de détection dans les zones d'intérêt critiques pour la conduite autonome, prouvant ainsi son efficacité en tant que potentiel des méthodes de détection d'objets 3D.
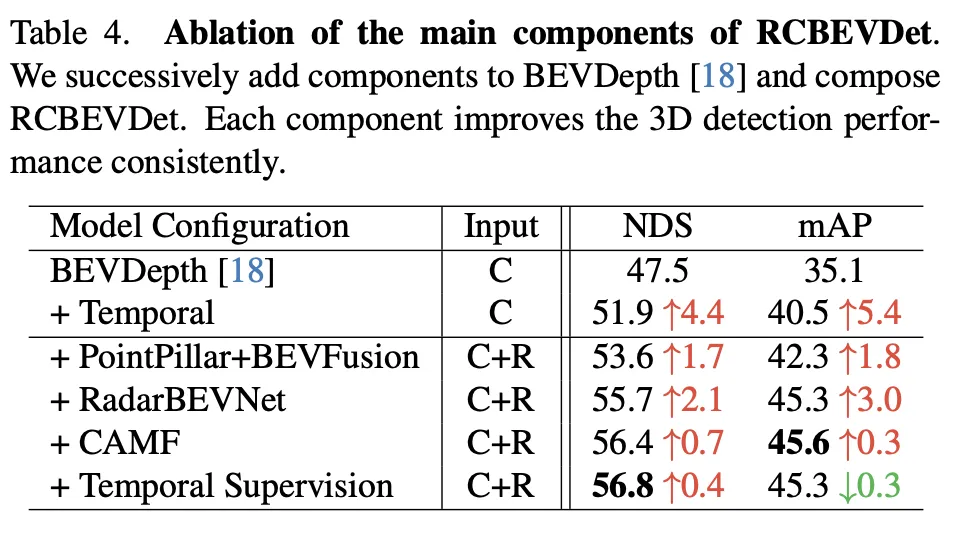
Cette expérience d'ablation démontre l'amélioration continue de RadarBEVNet dans les performances de détection d'objets 3D à mesure qu'il ajoute progressivement des composants majeurs. À partir du modèle de base BEVDepth, les composants ajoutés à chaque étape améliorent considérablement le NDS (métrique de base, reflétant la précision et l'exhaustivité de la détection) et le mAP (précision moyenne, reflétant la capacité du modèle à détecter des objets).
Dans l'ensemble, cette série d'expériences d'ablation démontre clairement la contribution de chaque composant majeur de RadarBEVNet à l'amélioration des performances de détection d'objets 3D, de l'introduction d'informations temporelles à la stratégie de fusion multimodale complexe, chaque étape apporte des améliorations de performances au modèle. En particulier, les stratégies sophistiquées de traitement et de fusion des données radar et caméra prouvent l’importance du traitement des données multimodales dans des environnements de conduite autonome complexes.
La méthode RadarBEVNet proposée dans l'article améliore efficacement la précision et la robustesse de la détection de cibles 3D en fusionnant les données multimodales des caméras et des radars, en particulier dans des scénarios de conduite autonome complexes. En introduisant RadarBEVNet et le module de fusion multicouche à attention croisée (CAMF), RadarBEVNet optimise non seulement le processus d'extraction des caractéristiques des données radar, mais réalise également un alignement précis des caractéristiques et une fusion entre les données du radar et de la caméra, surmontant ainsi le problème de l'utilisation d'un seul les limitations des données des capteurs, telles que les erreurs de relèvement radar et la dégradation des performances de la caméra en cas de faible luminosité ou de conditions météorologiques défavorables.
En termes d'avantages, la principale contribution de RadarBEVNet est sa capacité à traiter et utiliser efficacement des informations complémentaires entre les données multimodales, améliorant ainsi la précision de la détection et la robustesse du système. L'introduction de RadarBEVNet rend le traitement des données radar plus efficace et le module CAMF assure la fusion efficace des différentes données de capteurs, compensant ainsi leurs lacunes respectives. En outre, RadarBEVNet a démontré d'excellentes performances sur plusieurs ensembles de données lors d'expériences, en particulier dans des domaines d'intérêt cruciaux pour la conduite autonome, démontrant ainsi son potentiel dans des scénarios d'application pratiques.
En termes d'inconvénients, bien que RadarBEVNet ait obtenu des résultats remarquables dans le domaine de la détection de cibles 3D multimodale, la complexité de sa mise en œuvre a également augmenté en conséquence et peut nécessiter plus de ressources de calcul et de temps de traitement, ce qui limite son utilisation à un certain Déploiement dans des scénarios d’application en temps réel. De plus, bien que RadarBEVNet soit performant en matière de détection des cyclistes et de performances globales, il reste encore des possibilités d'amélioration des performances sur des catégories spécifiques (telles que les voitures et les piétons), ce qui peut nécessiter une optimisation plus poussée de l'algorithme ou des stratégies de fusion de fonctionnalités plus efficaces pour être résolues.
En résumé, RadarBEVNet a démontré des avantages de performance significatifs dans le domaine de la détection d'objets 3D grâce à sa stratégie innovante de fusion multimodale. Bien qu’il existe certaines limites, telles qu’une complexité informatique plus élevée et une marge d’amélioration des performances sur des catégories de détection spécifiques, son potentiel d’amélioration de la précision et de la robustesse des systèmes de conduite autonome ne peut être ignoré. Les travaux futurs pourront se concentrer sur l’optimisation de l’efficacité informatique de l’algorithme et sur l’amélioration de ses performances sur diverses détections de cibles afin de promouvoir le déploiement généralisé de RadarBEVNet dans les applications réelles de conduite autonome.
Le document présente RadarBEVNet et le module de fusion multicouche à attention croisée (CAMF) en fusionnant les données de caméra et de radar, montrant des améliorations significatives des performances dans le domaine de la détection de cibles 3D, en particulier dans la clé de la conduite autonome. Excellentes performances dans la scène. Il utilise efficacement les informations complémentaires entre les données multimodales pour améliorer la précision de la détection et la robustesse du système. Malgré les défis liés à une grande complexité informatique et aux possibilités d'amélioration des performances dans certaines catégories, notre système a montré un grand potentiel et une grande valeur pour promouvoir le développement de la technologie de conduite autonome, notamment en améliorant les capacités de perception des systèmes de conduite autonome. Les travaux futurs pourront se concentrer sur l’optimisation de l’efficacité des algorithmes et sur l’amélioration continue des performances de détection afin de mieux s’adapter aux besoins des applications de conduite autonome en temps réel.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Vérifiez le statut en ligne de vos amis sur TikTok
Vérifiez le statut en ligne de vos amis sur TikTok
 Utilisation des commandes NTSD
Utilisation des commandes NTSD
 Comment résoudre le problème signalé par le lien MySQL 10060
Comment résoudre le problème signalé par le lien MySQL 10060
 WeChat restaure l'historique des discussions
WeChat restaure l'historique des discussions
 La différence entre ancrer et viser
La différence entre ancrer et viser
 Quelle est la différence entre Douyin et Douyin Express Edition ?
Quelle est la différence entre Douyin et Douyin Express Edition ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



