


Dans le domaine de la vision par ordinateur, mesurer avec précision la similarité des images est une tâche critique avec un large éventail d'applications pratiques. Des moteurs de recherche d’images aux systèmes de reconnaissance faciale en passant par les systèmes de recommandation basés sur le contenu, la capacité de comparer et de trouver efficacement des images similaires est importante. Le réseau siamois combiné à la perte contrastive fournit un cadre puissant pour apprendre la similarité des images de manière basée sur les données. Dans cet article de blog, nous plongerons dans les détails des réseaux siamois, explorerons le concept de perte contrastive et explorerons comment ces deux composants fonctionnent ensemble pour créer un modèle de similarité d'image efficace. Premièrement, le réseau siamois se compose de deux sous-réseaux identiques partageant les mêmes poids et paramètres. Chaque sous-réseau code les images d'entrée en vecteurs de caractéristiques qui capturent les caractéristiques clés de l'image. Nous utilisons ensuite une perte contrastive pour mesurer la similarité entre les deux images d'entrée. La perte contrastive est basée sur la métrique de distance euclidienne et adopte un terme de restriction pour garantir que la distance entre les échantillons de la même classe est inférieure à la distance entre les échantillons de classes différentes. Grâce à des algorithmes de rétropropagation et d’optimisation, les réseaux siamois sont capables d’apprendre automatiquement les représentations des caractéristiques, ce qui rend la capacité à ressembler à des images très importante. L'innovation de ce modèle réside dans sa capacité à apprendre relativement peu d'échantillons dans l'ensemble d'apprentissage et à les transférer via l'apprentissage par transfert. Les réseaux de neurones siamois sont une classe de réseaux de neurones qui comparent et mesurent la similarité entre des paires d'architectures de réseau d'entrée. Le terme « siamois » vient du concept d'une architecture de réseau composée de deux réseaux neuronaux siamois structurés de manière identique et partageant le même ensemble de poids. Chaque réseau traite l'un des échantillons de l'entrée correspondante et détermine la similitude ou la dissemblance entre eux en comparant leurs sorties. Chaque échantillon du réseau siamois traite de la similarité ou de la dissemblance entre les échantillons d'entrée des échantillons d'entrée correspondants. Cette mesure de similarité peut être déterminée en comparant leurs résultats. Les réseaux siamois sont couramment utilisés pour des tâches de reconnaissance et de vérification, telles que la reconnaissance faciale, la reconnaissance d'empreintes digitales et la vérification de signature. Il peut automatiquement apprendre les similitudes entre les échantillons d'entrée et prendre des décisions basées sur les données d'entraînement. Avec un réseau siamois, chaque réseau traite l'un des échantillons d'entrée correspondants et compare leurs sorties pour déterminer à quel point ils sont similaires ou différents. La motivation des réseaux siamois est d'apprendre des représentations significatives d'échantillons d'entrée afin de capturer les caractéristiques essentielles requises pour leur comparaison de similarité. Ces réseaux excellent dans les tâches où la formation utilisant directement des exemples étiquetés est limitée ou difficile, car ils peuvent apprendre à classer des instances similaires et différentes sans afficher les étiquettes de classe. L'architecture d'un réseau siamois se compose généralement de trois composants principaux : un réseau de partage, une mesure de similarité et une fonction de perte contrastive. Les réseaux partagés se composent généralement de couches convolutionnelles et entièrement connectées pour extraire les représentations de caractéristiques de l'entrée. Il peut s'agir de réseaux pré-entraînés tels que VGG, ResNet, etc., ou de réseaux formés à partir de zéro. Le module de mesure de similarité est utilisé pour calculer la similarité ou la distance entre deux échantillons d'entrée. Les méthodes de mesure couramment utilisées incluent la distance euclidienne, la similarité cosinusoïdale, etc. La fonction de perte contrastive est utilisée pour mesurer la similitude ou la différence entre deux échantillons d'entrée. Une fonction de perte couramment utilisée est la perte contrastive, qui fonctionne en minimisant la distance entre des échantillons similaires et en maximisant la dissimilarité
在训练过程中,Siamese网络学会优化其参数以最小化对比损失,并生成能够有效捕捉输入数据的相似性结构的判别性embedding。
对比损失是Siamese网络中常用于学习输入样本对之间相似性或不相似性的损失函数。它旨在以这样一种方式优化网络的参数,即相似的输入具有在特征空间中更接近的embedding,而不相似的输入则被推到更远的位置。通过最小化对比损失,网络学会生成能够有效捕捉输入数据的相似性结构的embedding。
为了详细了解对比损失函数,让我们将其分解为其关键组件和步骤:
其中:
损失项 `(1 — y) * D²` 对相似对进行惩罚,如果它们的距离超过边际(m),则鼓励网络减小它们的距离。项 `y * max(0, m — D)²` 对不相似对进行惩罚,如果它们的距离低于边际,则推动网络增加它们的距离。
通过通过梯度下降优化方法(例如反向传播和随机梯度下降)最小化对比损失,Siamese网络学会生成能够有效捕捉输入数据的相似性结构的判别性embedding。对比损失函数在训练Siamese网络中发挥着关键作用,使其能够学习可用于各种任务,如图像相似性、人脸验证和文本相似性的有意义表示。对比损失函数的具体制定和参数可以根据数据的特性和任务的要求进行调整。
我们使用的数据集来自来自 :
http://vision.stanford.edu/aditya86/ImageNetDogs/
def copy_files(source_folder,files_list,des):for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.copy2(source_file,des_file)print(f"Copied {file} to {des}")return def move_files(source_folder,des):files_list=os.listdir(source_folder)for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.move(source_file,des_file)print(f"Copied {file} to {des}")return def rename_file(file_path,new_name):directory=os.path.dirname(file_path)new_file_path=os.path.join(directory,new_name)os.rename(file_path,new_file_path)print(f"File renamed to {new_file_path}")returnfolder_path=r"C:\Users\sri.karan\Downloads\images1\Images\*"op_path_similar=r"C:\Users\sri.karan\Downloads\images1\Images\similar_all_images"tmp=r"C:\Users\sri.karan\Downloads\images1\Images\tmp"op_path_dissimilar=r"C:\Users\sri.karan\Downloads\images1\Images\dissimilar_all_images"folders_list=glob.glob(folder_path)folders_list=list(set(folders_list).difference(set(['C:\\Users\\sri.karan\\Downloads\\images1\\Images\\similar_all_images','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\tmp','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\dissimilar_all_images'])))l,g=0,0random.shuffle(folders_list)for i in glob.glob(folder_path):if i in ['C:\\Users\\sri.karan\\Downloads\\images1\\Images\\similar_all_images','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\tmp','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\dissimilar_all_images']:continuefile_name=i.split('\\')[-1].split("-")[1]picked_files=pick_random_files(i,6)copy_files(i,picked_files,tmp)for m in range(3):rename_file(os.path.join(tmp,picked_files[m*2]),"similar_"+str(g)+"_first.jpg")rename_file(os.path.join(tmp,picked_files[m*2+1]),"similar_"+str(g)+"_second.jpg")g+=1move_files(tmp,op_path_similar)choice_one,choice_two=random.choice(range(len(folders_list))),random.choice(range(len(folders_list)))picked_dissimilar_one=pick_random_files(folders_list[choice_one],3)picked_dissimilar_two=pick_random_files(folders_list[choice_two],3)copy_files(folders_list[choice_one],picked_dissimilar_one,tmp)copy_files(folders_list[choice_two],picked_dissimilar_two,tmp)picked_files_dissimilar=picked_dissimilar_one+picked_dissimilar_twofor m in range(3):rename_file(os.path.join(tmp,picked_files_dissimilar[m]),"dissimilar_"+str(l)+"_first.jpg")rename_file(os.path.join(tmp,picked_files_dissimilar[m+3]),"dissimilar_"+str(l)+"_second.jpg")l+=1move_files(tmp,op_path_dissimilar)我们挑选了3对相似图像(狗品种)和3对不相似图像(狗品种)来微调模型,为了使负样本简单,对于给定的锚定图像(狗品种),任何除地面实况狗品种以外的其他狗品种都被视为负标签。
注意: “相似图像” 意味着来自相同狗品种的图像被视为正对,而“不相似图像” 意味着来自不同狗品种的图像被视为负对。
代码解释:
完成所有这些后,我们可以继续创建数据集对象。
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom PIL import Imageimport numpy as npimport randomfrom torch.utils.data import DataLoader, Datasetimport torchimport torch.nn as nnfrom torch import optimimport torch.nn.functional as Fclass ImagePairDataset(torch.utils.data.Dataset):def __init__(self, root_dir):self.root_dir = root_dirself.transform = T.Compose([# We first resize the input image to 256x256 and then we take center crop.transforms.Resize((256,256)), transforms.ToTensor()])self.image_pairs = self.load_image_pairs()def __len__(self):return len(self.image_pairs)def __getitem__(self, idx):image1_path, image2_path, label = self.image_pairs[idx]image1 = Image.open(image1_path).convert("RGB")image2 = Image.open(image2_path).convert("RGB")# Convert the tensor to a PIL image# image1 = functional.to_pil_image(image1)# image2 = functional.to_pil_image(image2)image1 = self.transform(image1)image2 = self.transform(image2)# image1 = torch.clamp(image1, 0, 1)# image2 = torch.clamp(image2, 0, 1)return image1, image2, labeldef load_image_pairs(self):image_pairs = []# Assume the directory structure is as follows:# root_dir# ├── similar# │ ├── similar_image1.jpg# │ ├── similar_image2.jpg# │ └── ...# └── dissimilar# ├── dissimilar_image1.jpg# ├── dissimilar_image2.jpg# └── ...similar_dir = os.path.join(self.root_dir, "similar_all_images")dissimilar_dir = os.path.join(self.root_dir, "dissimilar_all_images")# Load similar image pairs with label 1similar_images = os.listdir(similar_dir)for i in range(len(similar_images) // 2):image1_path = os.path.join(similar_dir, f"similar_{i}_first.jpg")image2_path = os.path.join(similar_dir, f"similar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 0))# Load dissimilar image pairs with label 0dissimilar_images = os.listdir(dissimilar_dir)for i in range(len(dissimilar_images) // 2):image1_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_first.jpg")image2_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 1))return image_pairsdataset = ImagePairDataset(r"/home/niq/hcsr2001/data/image_similarity")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)在上述代码的第8到10行:对图像进行预处理,包括将图像调整大小为256。我们使用批量大小为32,这取决于您的计算能力和 GPU。
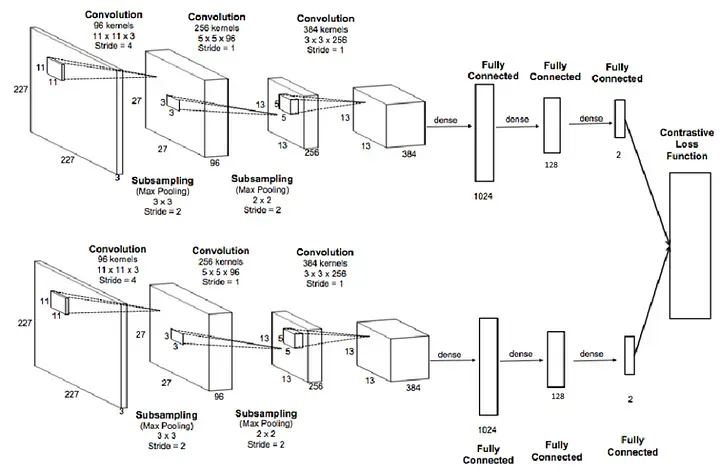
#create the Siamese Neural Networkclass SiameseNetwork(nn.Module):def __init__(self):super(SiameseNetwork, self).__init__()# Setting up the Sequential of CNN Layers# self.cnn1 = nn.Sequential(# nn.Conv2d(3, 256, kernel_size=11,stride=4),# nn.ReLU(inplace=True),# nn.MaxPool2d(3, stride=2),# nn.Conv2d(256, 256, kernel_size=5, stride=1),# nn.ReLU(inplace=True),# nn.MaxPool2d(2, stride=2),# nn.Conv2d(256, 384, kernel_size=3,stride=1),# nn.ReLU(inplace=True)# )self.cnn1=nn.Conv2d(3, 256, kernel_size=11,stride=4)self.relu = nn.ReLU()self.maxpool1=nn.MaxPool2d(3, stride=2)self.cnn2=nn.Conv2d(256, 256, kernel_size=5,stride=1)self.maxpool2=nn.MaxPool2d(2, stride=2)self.cnn3=nn.Conv2d(256, 384, kernel_size=3,stride=1)self.fc1 =nn.Linear(46464, 1024)self.fc2=nn.Linear(1024, 256)self.fc3=nn.Linear(256, 1)# Setting up the Fully Connected Layers# self.fc1 = nn.Sequential(# nn.Linear(384, 1024),# nn.ReLU(inplace=True),# nn.Linear(1024, 32*46464),# nn.ReLU(inplace=True),# nn.Linear(32*46464,1)# )def forward_once(self, x):# This function will be called for both images# Its output is used to determine the similiarity# output = self.cnn1(x)# print(output.view(output.size()[0], -1).shape)# output = output.view(output.size()[0], -1)# output = self.fc1(output)# print(x.shape)output= self.cnn1(x)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool1(output)# print(output.shape)output= self.cnn2(output)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool2(output)# print(output.shape)output= self.cnn3(output)output=self.relu(output)# print(output.shape)output=output.view(output.size()[0], -1)# print(output.shape)output=self.fc1(output)# print(output.shape)output=self.fc2(output)# print(output.shape)output=self.fc3(output)return outputdef forward(self, input1, input2):# In this function we pass in both images and obtain both vectors# which are returnedoutput1 = self.forward_once(input1)output2 = self.forward_once(input2)return output1, output2
我们的网络称为 SiameseNetwork,我们可以看到它几乎与标准 CNN 相同。唯一可以注意到的区别是我们有两个前向函数(forward_once 和 forward)。为什么呢?
我们提到通过相同网络传递两个图像。forward_once 函数在 forward 函数中调用,它将一个图像作为输入传递到网络。输出存储在 output1 中,而来自第二个图像的输出存储在 output2 中,正如我们在 forward 函数中看到的那样。通过这种方式,我们设法输入了两个图像并从我们的模型获得了两个输出。
我们已经看到了损失函数应该是什么样子,现在让我们来编码它。我们创建了一个名为 ContrastiveLoss 的类,与模型类一样,我们将有一个 forward 函数。
class ContrastiveLoss(torch.nn.Module):def __init__(self, margin=2.0):super(ContrastiveLoss, self).__init__()self.margin = margindef forward(self, output1, output2, label):# Calculate the euclidean distance and calculate the contrastive losseuclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))return loss_contrastivenet = SiameseNetwork().cuda()criterion = ContrastiveLoss()optimizer = optim.Adam(net.parameters(), lr = 0.0005 )
按照顶部的流程图,我们可以开始创建训练循环。我们迭代100次并提取两个图像以及标签。我们将梯度归零,将两个图像传递到网络中,网络输出两个向量。然后,将两个向量和标签馈送到我们定义的 criterion(损失函数)中。我们进行反向传播和优化。出于一些可视化目的,并查看我们的模型在训练集上的性能,因此我们将每10批次打印一次损失。
counter = []loss_history = [] iteration_number= 0# Iterate throught the epochsfor epoch in range(100):# Iterate over batchesfor i, (img0, img1, label) in enumerate(train_loader, 0):# Send the images and labels to CUDAimg0, img1, label = img0.cuda(), img1.cuda(), label.cuda()# Zero the gradientsoptimizer.zero_grad()# Pass in the two images into the network and obtain two outputsoutput1, output2 = net(img0, img1)# Pass the outputs of the networks and label into the loss functionloss_contrastive = criterion(output1, output2, label)# Calculate the backpropagationloss_contrastive.backward()# Optimizeoptimizer.step()# Every 10 batches print out the lossif i % 10 == 0 :print(f"Epoch number {epoch}\n Current loss {loss_contrastive.item()}\n")iteration_number += 10counter.append(iteration_number)loss_history.append(loss_contrastive.item())show_plot(counter, loss_history)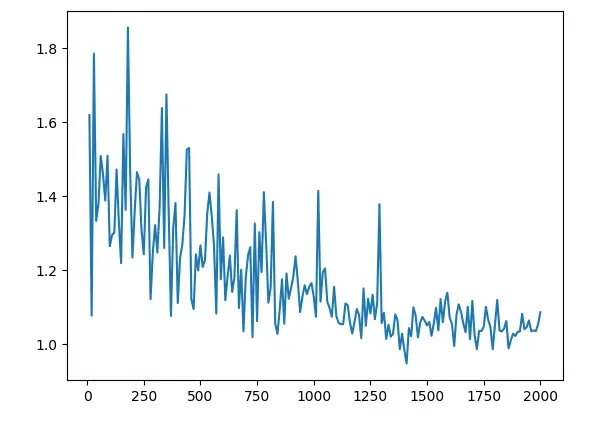
我们现在可以分析结果。我们能看到的第一件事是损失从1.6左右开始,并以接近1的数字结束。看到模型的实际运行情况将是有趣的。现在是我们在模型之前没见过的图像上测试我们的模型的部分。与之前一样,我们使用我们的自定义数据集类创建了一个 Siamese Network 数据集,但现在我们将其指向测试文件夹。
作为接下来的步骤,我们从第一批中提取第一张图像,并迭代5次以提取接下来5批中的5张图像,因为我们设置每批包含一张图像。然后,使用 torch.cat() 水平组合两个图像,我们可以清楚地可视化哪个图像与哪个图像进行了比较。
我们将两个图像传入模型并获得两个向量,然后将这两个向量传入 F.pairwise_distance() 函数,这将计算两个向量之间的欧氏距离。使用这个距离,我们可以作为衡量两张脸有多不相似的指标。
test_loader_one = DataLoader(test_dataset, batch_size=1, shuffle=False)dataiter = iter(test_loader_one)x0, _, _ = next(dataiter)for i in range(5):# Iterate over 5 images and test them with the first image (x0)_, x1, label2 = next(dataiter)# Concatenate the two images togetherconcatenated = torch.cat((x0, x1), 0)output1, output2 = net(x0.cuda(), x1.cuda())euclidean_distance = F.pairwise_distance(output1, output2)imshow(torchvision.utils.make_grid(concatenated), f'Dissimilarity: {euclidean_distance.item():.2f}')view raweval.py hosted with ❤ by GitHub
Siamese 网络与对比损失结合,为学习图像相似性提供了一个强大而有效的框架。通过对相似和不相似图像进行训练,这些网络可以学会提取能够捕捉基本视觉特征的判别性embedding。对比损失函数通过优化embedding空间进一步增强
了模型准确测量图像相似性的能力。随着深度学习和计算机视觉的进步,Siamese 网络在各个领域都有着巨大的潜力,包括图像搜索、人脸验证和推荐系统。通过利用这些技术,我们可以为基于内容的图像检索、视觉理解以及视觉领域的智能决策开启令人兴奋的可能性。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 winkawaksrom
winkawaksrom
 Java est-il front-end ou back-end ?
Java est-il front-end ou back-end ?
 Comment définir la zone de texte en lecture seule
Comment définir la zone de texte en lecture seule
 Comment remplacer tous les arrière-plans ppt
Comment remplacer tous les arrière-plans ppt
 La différence entre passerelle et routeur
La différence entre passerelle et routeur
 Utilisation régulière de grep
Utilisation régulière de grep





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



