


L'estimation de la pose d'un objet joue un rôle clé dans de nombreuses applications pratiques, notamment dans des domaines tels que l'intelligence incorporée, le fonctionnement des robots et la réalité augmentée.
Dans ce domaine, la première tâche à retenir est l'Estimation de pose 6D au niveau de l'instance, qui nécessite des données annotées sur l'objet cible pour la formation du modèle, rendant le modèle profond spécifique à l'objet et incapable d'être transféré à de nouveaux objets. supérieur. Plus tard, l'accent de la recherche s'est progressivement tourné vers l'estimation de pose 6D au niveau de la catégorie, qui est utilisée pour traiter des objets invisibles, mais nécessite que l'objet appartienne à une catégorie d'intérêt connue. Et
estimation de pose 6D zéro tirest un paramètre de tâche plus général, étant donné un modèle CAO de n'importe quel objet, visant à détecter l'objet cible dans la scène et à estimer sa pose 6D. Malgré son importance, ce paramètre de tâche sans tir est confronté à des défis importants en matière de détection d'objets et d'estimation de pose.

Figure 1. Tâche d'estimation de la pose d'un objet 6D à échantillon nul Récemment, la segmentation de tous les modèles SAM [1] a attiré beaucoup d'attention, et son excellente capacité de segmentation sans échantillon est accrocheuse. SAM réalise une segmentation de haute précision grâce à divers indices, tels que des pixels, des cadres de délimitation, du texte et des masques, etc., qui fournissent également un support fiable pour la tâche d'estimation de la pose d'objet 6D à échantillon nul, démontrant ainsi son potentiel prometteur.
Par conséquent, un nouveau cadre d'estimation de pose d'objet 6D à échantillon nul, SAM-6D, a été proposé par des chercheurs de Cross-Dimensional Intelligence, de l'Université chinoise de Hong Kong (Shenzhen) et de l'Université de technologie de Chine du Sud. Cette recherche a été reconnue par CVPR 2024.

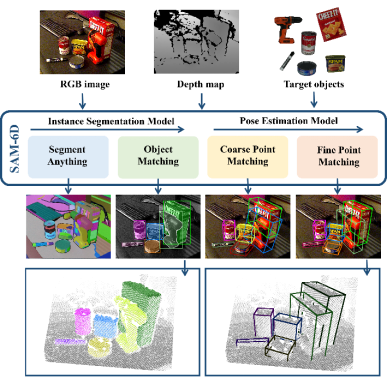
SAM-6D exploite la capacité de segmentation sans tir du modèle Segment Everything pour générer tous les candidats possibles et conçoit un nouveau score de correspondance d'objets pour identifier les candidats correspondant aux objets cibles.
SAM-6D traite l'estimation de pose comme un problème de correspondance d'ensembles de points local à local, adopte une conception de jeton d'arrière-plan simple mais efficace et propose d'abord un modèle de correspondance d'ensembles de points en deux étapes pour les objets arbitraires. une correspondance d'ensemble de points grossière pour obtenir la pose initiale de l'objet, et la deuxième étape utilise un nouveau transformateur d'ensemble de points clairsemé à dense pour effectuer une correspondance d'ensemble de points fine afin d'optimiser davantage la pose.Terme de correspondance sémantique - Pour l'objet cible, ISM restitue les modèles d'objet sous plusieurs perspectives et utilise DINOv2 [3] pour la pré-formation. Le modèle ViT extrait les caractéristiques sémantiques des objets candidats et des modèles d'objets, et calcule les scores de corrélation entre eux. Le score de correspondance sémantique est obtenu en faisant la moyenne des K scores les plus élevés, et le modèle d'objet correspondant au score de corrélation le plus élevé est considéré comme le meilleur modèle de correspondance.
Correspondance d'apparence - Pour le meilleur modèle de correspondance, le modèle ViT est utilisé pour extraire les caractéristiques du bloc d'image et calculer la corrélation entre elles et les caractéristiques du bloc de l'objet candidat pour obtenir le score de correspondance d'apparence, qui est utilisé pour distinguer sémantiquement similaire mais des objets correspondant à l'apparence.
Correspondances géométriques - En tenant compte de facteurs tels que les différences de forme et de taille des différents objets, ISM a également conçu un score de correspondance géométrique. La moyenne de la rotation correspondant au modèle le mieux adapté et au nuage de points de l'objet candidat peut donner une pose d'objet approximative, et le cadre de délimitation peut être obtenu en transformant et en projetant de manière rigide le modèle CAO d'objet à l'aide de cette pose. Le calcul du rapport d'intersection sur union (IoU) entre le cadre englobant et le cadre englobant candidat peut obtenir le score de correspondance géométrique.
Modèle d'estimation de pose (PEM)
Pour chaque objet candidat qui correspond à un objet cible, SAM-6D utilise un modèle d'estimation de pose (PEM) pour prédire sa pose 6D par rapport au modèle CAO de l'objet.
Désignons les ensembles de points d'échantillonnage des objets candidats segmentés et des modèles CAO d'objets respectivement par 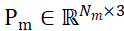 et
et 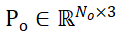 , où N_m et N_o représentent le nombre de leurs points en même temps, représentent les caractéristiques de ces deux ensembles de points par
, où N_m et N_o représentent le nombre de leurs points en même temps, représentent les caractéristiques de ces deux ensembles de points par 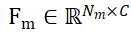 et
et 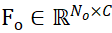 , C représente le nombre de canaux de la fonctionnalité. L'objectif de PEM est d'obtenir une matrice d'affectation qui représente la correspondance locale à locale de P_m à P_o ; en raison de l'occlusion, P_o ne correspond que partiellement à P_m, et en raison de l'imprécision de la segmentation et du bruit du capteur, P_m ne correspond que partiellement aux correspondances ET partielles. P_o.
, C représente le nombre de canaux de la fonctionnalité. L'objectif de PEM est d'obtenir une matrice d'affectation qui représente la correspondance locale à locale de P_m à P_o ; en raison de l'occlusion, P_o ne correspond que partiellement à P_m, et en raison de l'imprécision de la segmentation et du bruit du capteur, P_m ne correspond que partiellement aux correspondances ET partielles. P_o.
Afin de résoudre le problème de l'attribution de points qui ne se chevauchent pas dans deux ensembles de points, ISM les équipe de jetons d'arrière-plan, notés 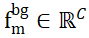 et
et 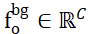 , qui peuvent établir efficacement une correspondance locale à locale basée sur la similarité des caractéristiques. Plus précisément, la matrice d'attention peut d'abord être calculée comme suit :
, qui peuvent établir efficacement une correspondance locale à locale basée sur la similarité des caractéristiques. Plus précisément, la matrice d'attention peut d'abord être calculée comme suit :
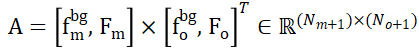
Ensuite, la matrice de distribution
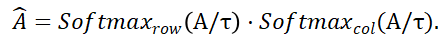
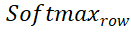 et
et 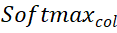 représentent l'opération softmax le long des lignes et des colonnes respectivement, et
représentent l'opération softmax le long des lignes et des colonnes respectivement, et 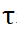 représente une constante. La valeur de chaque ligne de
représente une constante. La valeur de chaque ligne de 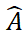 (sauf la première ligne) représente la probabilité de correspondance de chaque point P_m dans l'ensemble de points P_m avec l'arrière-plan et le point médian de P_o. En localisant l'indice du score maximum, le point correspondant à P_m (y compris. l'arrière-plan) peut être trouvé ).
(sauf la première ligne) représente la probabilité de correspondance de chaque point P_m dans l'ensemble de points P_m avec l'arrière-plan et le point médian de P_o. En localisant l'indice du score maximum, le point correspondant à P_m (y compris. l'arrière-plan) peut être trouvé ).
Une fois  calculé, toutes les paires de points correspondantes {(P_m,P_o)} et leurs scores correspondants peuvent être rassemblés, et enfin le SVD pondéré est utilisé pour calculer la pose de l'objet.
calculé, toutes les paires de points correspondantes {(P_m,P_o)} et leurs scores correspondants peuvent être rassemblés, et enfin le SVD pondéré est utilisé pour calculer la pose de l'objet.
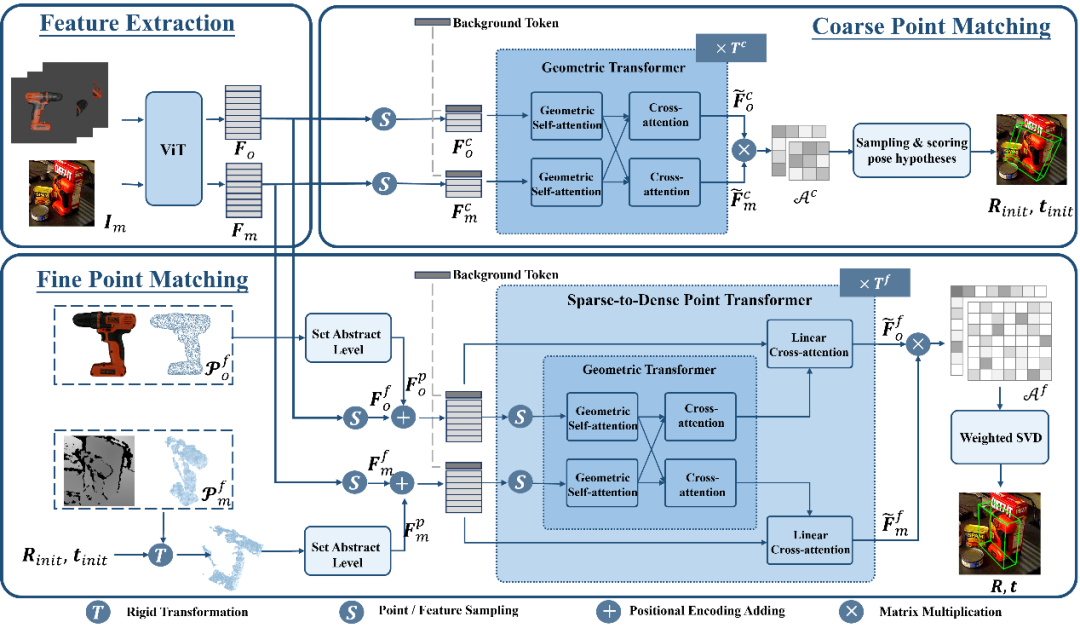
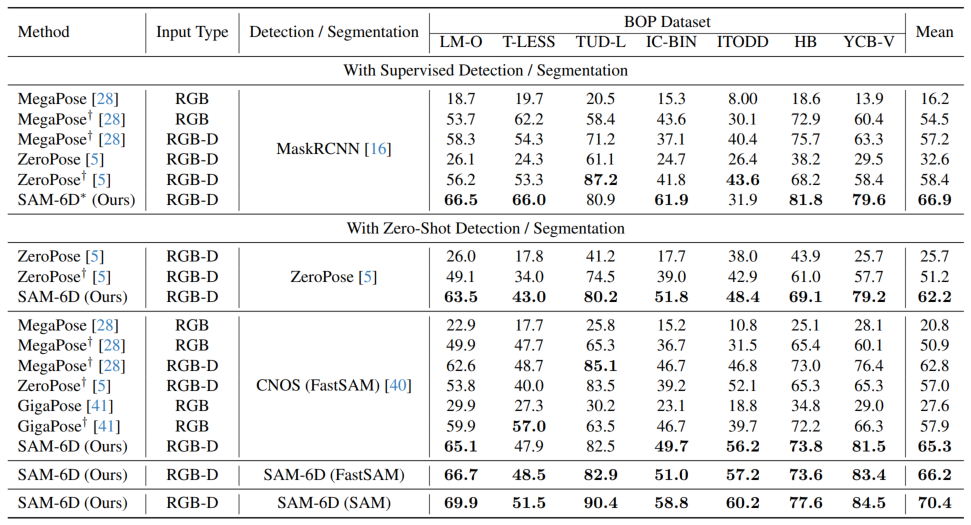
En utilisant la stratégie ci-dessus basée sur le jeton d'arrière-plan, deux étapes de correspondance d'ensembles de points sont conçues dans PEM. La structure du modèle est illustrée dans la figure 3, qui comprend l'extraction de caractéristiques, la correspondance d'ensembles de points grossiers et la correspondance d'ensembles de points finstrois modules. Le module de correspondance d'ensemble de points approximatifs implémente une correspondance clairsemée pour calculer la pose initiale de l'objet, puis utilise cette pose pour transformer l'ensemble de points de l'objet candidat afin d'obtenir un apprentissage du codage de position. Le module de correspondance d'ensembles de points fins combine le codage de position des ensembles de points d'échantillonnage de l'objet candidat et de l'objet cible, injectant ainsi la correspondance approximative dans la première étape et établissant davantage une correspondance dense pour obtenir une pose d'objet plus précise. Afin d'apprendre efficacement les interactions denses à ce stade, PEM introduit un nouveau transformateur d'ensemble de points clairsemé à dense, qui implémente des interactions sur des versions clairsemées de caractéristiques denses, et utilise le transformateur linéaire [5] pour transformer les caractéristiques clairsemées améliorées en diffusion en dense. caractéristiques. Résultats expérimentaux Pour les deux sous-modèles de SAM-6D, le modèle de segmentation d'instance (ISM) est construit sur la base de SAM sans nécessiter de recyclage et de réglage du réseau, tandis que le modèle d'estimation de pose (PEM) utilise MegaPose. [4] fournit des ensembles de données synthétiques ShapeNet-Objects et Google-Scanned-Objects à grande échelle pour la formation. Pour vérifier sa capacité à échantillon zéro, SAM-6D a été testé sur sept ensembles de données de base de BOP [2], notamment LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB et YCB-V. . Les tableaux 1 et 2 montrent respectivement la comparaison de la segmentation des instances et les résultats de l'estimation de pose de différentes méthodes sur ces sept ensembles de données. Comparé à d’autres méthodes, SAM-6D fonctionne très bien sur les deux méthodes, démontrant pleinement sa forte capacité de généralisation. B Tableau 1. Le résultat de stérilisation de différentes méthodes sur les sept ensembles de données de base sur BOP Tableaux 2. Différentes méthodes sur l'attitude des différentes méthodes sur les sept ensembles de données de base de BOP Comparaison des résultats Pour plus de détails sur la mise en œuvre de SAM-6D, n'hésitez pas à lire l'article original. [1] Alexander Kirillov et al., "Segment any." [2] Martin Sundermeyer et. al., "Bop challenge 2022 sur la détection, la segmentation et l'estimation de pose d'objets rigides spécifiques." [3] Maxime Oquab et al., "Dinov2 : Learning Fonctionnalités visuelles robustes sans supervision. . . al., "Les transformateurs sont des RNN : des transformateurs autorégressifs rapides avec une attention linéaire."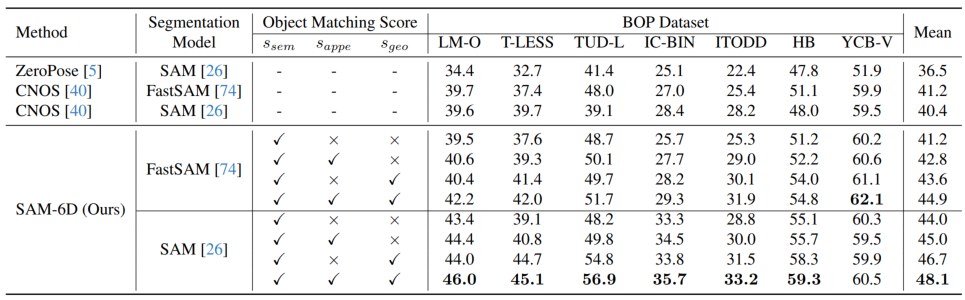

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 pagination mysql
pagination mysql
 Quelle est la touche de raccourci pour changer d'utilisateur ?
Quelle est la touche de raccourci pour changer d'utilisateur ?
 Comment résoudre le problème selon lequel le dossier Win10 ne peut pas être supprimé
Comment résoudre le problème selon lequel le dossier Win10 ne peut pas être supprimé
 Comment ouvrir le disque virtuel
Comment ouvrir le disque virtuel
 Que faire si votre adresse IP est attaquée
Que faire si votre adresse IP est attaquée
 Comment couper de longues photos sur les téléphones mobiles Huawei
Comment couper de longues photos sur les téléphones mobiles Huawei
 Cache mybatis de premier niveau et cache de deuxième niveau
Cache mybatis de premier niveau et cache de deuxième niveau
 Utilisation de la fonction get en langage C
Utilisation de la fonction get en langage C








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



