


Les grands modèles linguistiques (LLM) se sont développés rapidement au cours des deux dernières années, et certains modèles et produits phénoménaux ont émergé, tels que GPT-4, Gemini, Claude, etc., mais la plupart d'entre eux sont de source fermée. Il existe un écart important entre la plupart des LLM open source actuellement accessibles à la communauté des chercheurs et les LLM à source fermée. Par conséquent, l'amélioration des capacités des LLM open source et d'autres petits modèles pour réduire l'écart entre eux et les grands modèles à source fermée est devenue un point chaud de la recherche. dans ce champ.
Les puissantes capacités du LLM, en particulier du LLM à source fermée, permettent aux chercheurs scientifiques et aux praticiens industriels d'utiliser les résultats et les connaissances de ces grands modèles lors de la formation de leurs propres modèles. Ce processus est essentiellement un processus de distillation des connaissances (KD), c'est-à-dire la distillation des connaissances d'un modèle d'enseignant (tel que GPT-4) vers un modèle plus petit (tel que Llama), ce qui améliore considérablement les capacités du petit modèle. On peut constater que la technologie de distillation des connaissances des grands modèles de langage est omniprésente et constitue une méthode rentable et efficace permettant aux chercheurs de les aider à former et à améliorer leurs propres modèles.
Alors, comment les travaux actuels utilisent-ils le LLM à source fermée pour la distillation des connaissances et l'acquisition de données ? Comment intégrer efficacement ces connaissances dans de petits modèles ? Quelles compétences puissantes les petits modèles peuvent-ils acquérir auprès des modèles enseignants ? Comment la distillation des connaissances du LLM joue-t-elle un rôle dans l’industrie avec des caractéristiques de domaine ? Ces questions méritent une réflexion et des recherches approfondies.
En 2020, l'équipe de Tao Dacheng a publié « Knowledge Distillation : A Survey », qui explorait de manière approfondie l'application de la distillation des connaissances dans l'apprentissage profond. Cette technologie est principalement utilisée pour la compression et l’accélération des modèles. Avec l'essor des modèles linguistiques à grande échelle, les domaines d'application de la distillation des connaissances ont été continuellement élargis, ce qui peut non seulement améliorer les performances des petits modèles, mais également permettre l'auto-amélioration des modèles.
Début 2024, l'équipe de Tao Dacheng a collaboré avec l'Université de Hong Kong et l'Université du Maryland pour publier la dernière revue « A Survey on Knowledge Distillation of Large Language Models », qui résumait 374 travaux connexes et discutait de la manière d'obtenir des connaissances de grands modèles de langage. Formation de modèles plus petits et rôle de la distillation des connaissances dans la compression des modèles et l'auto-formation. Dans le même temps, cette revue couvre également la distillation des grandes compétences en matière de modèles de langage et la distillation des champs verticaux, aidant les chercheurs à pleinement comprendre comment former et améliorer leurs propres modèles.

Titre de l'article : A Survey on Knowledge Distillation of Large Language Models
Lien de l'article : https://arxiv.org/abs/2402.13116
Lien du projet : https://github. com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
Overview Architecture
Le cadre global de la distillation des connaissances des grands modèles de langage est résumé comme le montre la figure ci-dessous :
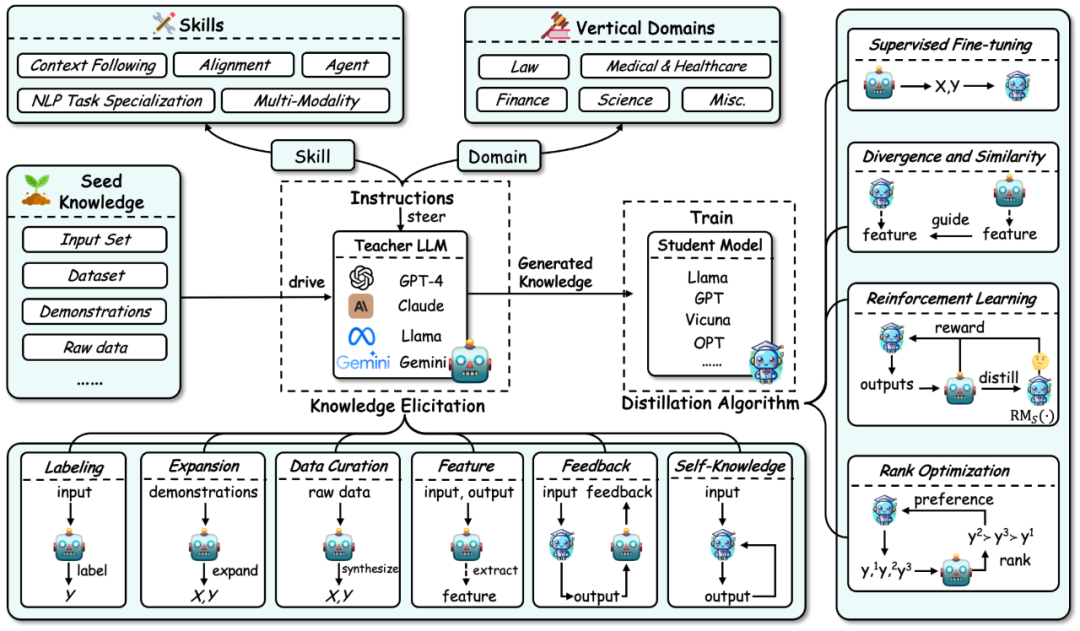
Premièrement, basé sur Processus de distillation des connaissances sur un grand modèle de langage, cette revue décompose la distillation des connaissances en deux étapes :
1.Élicitation des connaissances : c'est-à-dire comment obtenir des connaissances à partir du modèle de l'enseignant. Le processus comprend principalement : a) Premières instructions de construction pour identifier les aptitudes ou compétences verticales à distiller à partir du modèle d'enseignant.
b) Utilisez ensuite les connaissances initiales (telles qu'un certain ensemble de données) comme entrée pour piloter le modèle de l'enseignant et générer les réponses correspondantes, guidant ainsi les connaissances correspondantes.
c) Parallèlement, l'acquisition de connaissances inclut certaines technologies spécifiques : annotation, expansion, synthèse, extraction de fonctionnalités, feedback et connaissances propres.
2.
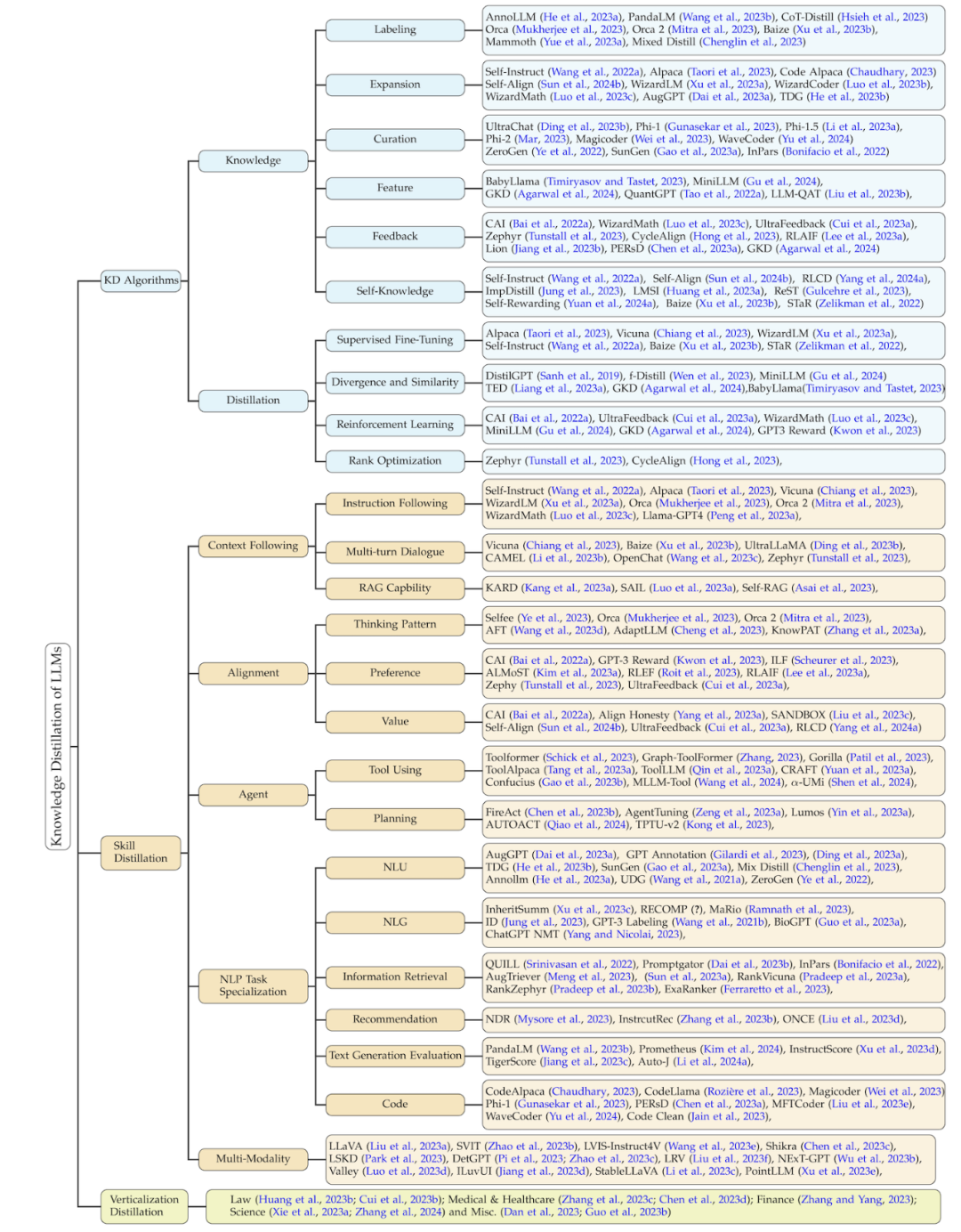
Algorithmes de distillation: C'est-à-dire comment injecter les connaissances acquises dans le modèle de l'étudiant. Les algorithmes spécifiques de cette partie incluent : le réglage fin supervisé, la divergence et la similarité, l'apprentissage par renforcement (c'est-à-dire l'apprentissage par renforcement à partir du feedback de l'IA, RLAIF) et l'optimisation du classement. La méthode de classification de cette revue résume les travaux connexes en trois dimensions basés sur ce processus : les algorithmes de distillation des connaissances, la distillation des compétences et la distillation du champ vertical. Ces deux derniers sont distillés sur la base d’algorithmes de distillation des connaissances. Les détails de cette classification et un résumé des travaux associés correspondants sont présentés dans la figure ci-dessous.
Élicitation des connaissances
Selon la manière d'acquérir les connaissances à partir du modèle de l'enseignant, cette revue divise sa technologie en étiquetage, expansion et synthèse de données (data Curation), extraction de fonctionnalités. (Feature), feedback (Feedback), connaissances auto-générées (Self-Knowledge). Des exemples de chaque méthode sont présentés ci-dessous :
Étiquetage : L'étiquetage des connaissances signifie que les enseignants LLM utilisent les entrées données comme connaissances initiales pour générer le résultat correspondant basé sur des instructions ou des exemples. Par exemple, la connaissance initiale est l'entrée d'un certain ensemble de données, et le modèle de l'enseignant étiquette la sortie de la chaîne de réflexion.
Expansion : Une caractéristique clé de cette technologie est d'utiliser les capacités d'apprentissage contextuel des LLM pour générer des données similaires à l'exemple basé sur l'exemple de départ fourni. L’avantage est que des ensembles de données plus diversifiés et plus étendus peuvent être générés à partir d’exemples. Cependant, à mesure que les données générées continuent d’augmenter, des problèmes d’homogénéité des données peuvent survenir.
Synthèse de données (Data Curation) : Une caractéristique distinctive de la synthèse de données est qu'elle synthétise les données à partir de zéro. Il utilise une grande quantité de méta-informations (telles que des sujets, des documents de connaissances, des données originales, etc.) en tant que quantités diverses et énormes de connaissances initiales pour obtenir des ensembles de données à grande échelle et de haute qualité provenant des LLM des enseignants.
Acquisition de fonctionnalités (Feature) : La méthode typique pour obtenir la connaissance des fonctionnalités consiste à transmettre les séquences d'entrée et de sortie aux LLM de l'enseignant, puis à extraire sa représentation interne. Cette méthode convient principalement aux LLM open source et est souvent utilisée pour la compression de modèles.
Feedback : Les connaissances de rétroaction fournissent généralement un retour au modèle de l'enseignant sur le résultat de l'élève, par exemple en fournissant des préférences, des informations d'évaluation ou de correction pour guider les élèves à générer un meilleur résultat.
Connaissance de soi : Les connaissances peuvent également être obtenues auprès des étudiants eux-mêmes, c'est ce qu'on appelle les connaissances auto-générées. Dans ce cas, le même modèle agit à la fois comme enseignant et comme élève, s’améliorant de manière itérative en distillant des techniques et en améliorant ses propres résultats générés précédemment. Cette approche fonctionne bien pour les LLM open source.
Résumé : À l'heure actuelle, la méthode d'extension est encore largement utilisée et la méthode de synthèse de données est progressivement devenue courante car elle peut générer une grande quantité de données de haute qualité. Les méthodes de rétroaction peuvent fournir des connaissances qui aident les modèles d'étudiants à améliorer leurs capacités d'alignement. Les méthodes d’acquisition de fonctionnalités et de connaissances autogénérées sont devenues populaires en raison de l’utilisation de grands modèles open source comme modèles pour les enseignants. La méthode d'acquisition de fonctionnalités permet de compresser les modèles open source, tandis que la méthode de connaissances auto-générées peut améliorer continuellement les grands modèles de langage. Il est important de noter que les méthodes ci-dessus peuvent être combinées efficacement et que les chercheurs peuvent explorer différentes combinaisons pour obtenir des connaissances plus efficaces.
Algorithmes de distillation
Après avoir acquis des connaissances, celles-ci doivent être distillées dans le modèle de l'étudiant. Les algorithmes de distillation comprennent : le réglage fin supervisé, la divergence et la similarité, l'apprentissage par renforcement et l'optimisation du classement. Un exemple est présenté dans la figure ci-dessous :
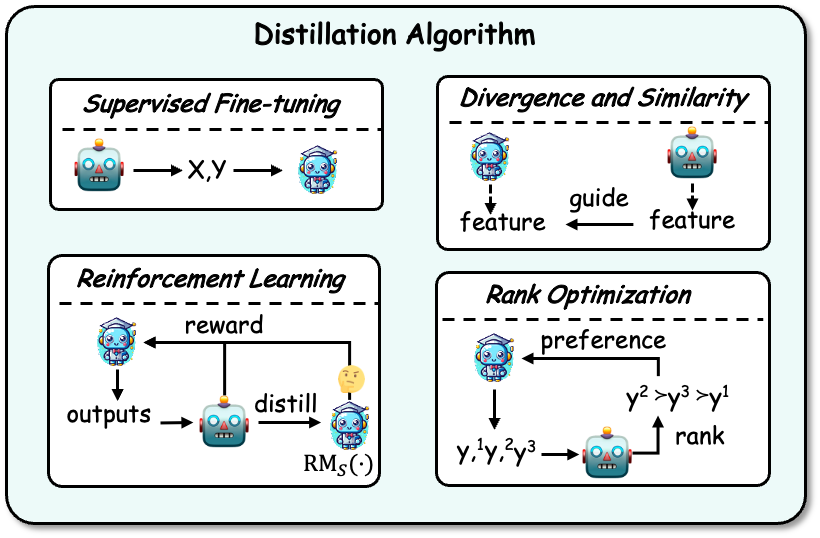
Réglage fin supervisé : Le réglage fin supervisé (SFT) affine le modèle de l'élève en maximisant la probabilité des séquences générées par le modèle de l'enseignant, permettant à l'élève modèle pour imiter le modèle de l’enseignant. Il s’agit actuellement de la technique la plus couramment utilisée pour distiller les connaissances des LLM.
Divergence et similarité : Cet algorithme utilise la connaissance des paramètres internes du modèle d'enseignant comme signal de supervision pour la formation du modèle d'étudiant et convient aux modèles d'enseignant open source. Les méthodes basées sur la divergence et la similarité alignent respectivement les distributions de probabilité et les états cachés.
Apprentissage par renforcement : Cet algorithme convient à l'utilisation des connaissances des commentaires des enseignants pour former des modèles d'élèves, c'est-à-dire la technologie RLAIF. Il y a deux aspects principaux : (1) utiliser les données de rétroaction générées par l'enseignant pour former un modèle de récompense de l'élève, (2) optimiser le modèle de l'élève en maximisant la récompense attendue grâce au modèle de récompense entraîné. Les enseignants peuvent également servir directement de modèles de récompense.
Optimisation du classement : L'optimisation du classement peut également injecter des connaissances sur les préférences dans le modèle étudiant. Ses avantages sont la stabilité et une efficacité de calcul élevée, comme certains algorithmes classiques tels que DPO, RRHF, etc.
Distillation des compétences
Il est bien connu que les grands modèles de langage possèdent de nombreuses excellentes capacités. Grâce à la technologie de distillation des connaissances, des instructions sont fournies pour contrôler les enseignants afin qu'ils génèrent des connaissances contenant les compétences correspondantes et forment des modèles d'élèves afin qu'ils puissent acquérir ces capacités. Ces fonctionnalités incluent principalement des fonctionnalités telles que le suivi du contexte (tel que les instructions), l'alignement, les agents, les tâches de traitement du langage naturel (NLP) et la multimodalité.
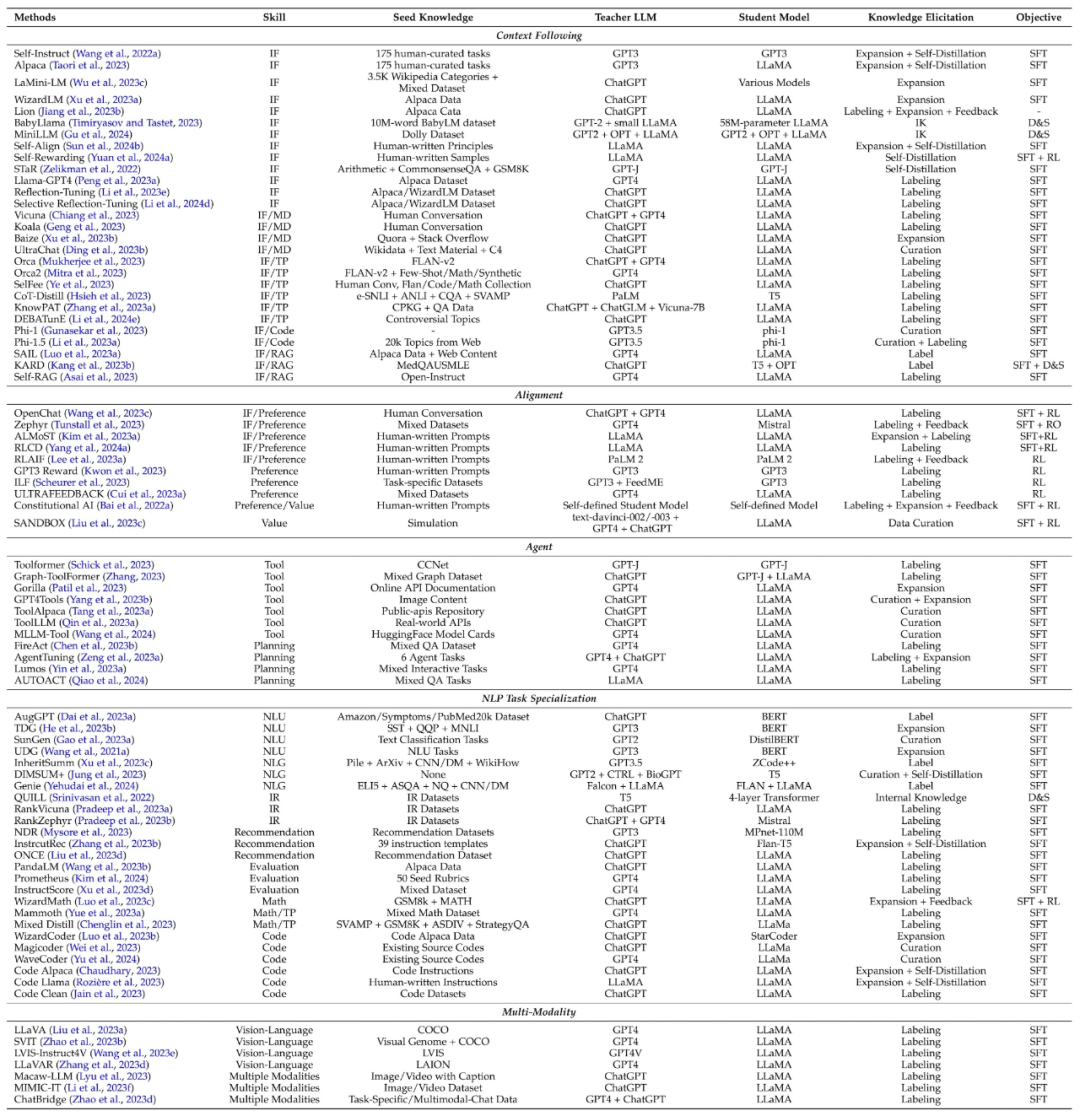
Le tableau suivant résume le travail classique de distillation des compétences, et résume également les compétences, les connaissances de départ, le modèle de l'enseignant, le modèle de l'étudiant, les méthodes d'acquisition des connaissances et les algorithmes de distillation impliqués dans chaque travail.
Distillation sur champ vertical
En plus des grands modèles linguistiques dans les domaines généraux, de nombreux efforts sont désormais déployés pour former de grands modèles linguistiques dans des domaines verticaux, ce qui aide la communauté de recherche et l'industrie à appliquer et à déployer de grands modèles linguistiques. Bien que les grands modèles de langage (tels que GPT-4) aient une connaissance limitée du domaine dans les domaines verticaux, ils peuvent toujours fournir certaines connaissances et capacités du domaine ou améliorer les ensembles de données de domaine existants. Les domaines concernés ici comprennent principalement (1) le droit, (2) la santé médicale, (3) la finance, (4) la science et quelques autres domaines. La taxonomie et les travaux connexes de cette partie sont présentés dans la figure ci-dessous :

Orientations futures
Cette revue explore les problèmes actuels de distillation des connaissances des grands modèles de langage et les orientations de recherche futures potentielles, comprenant principalement :
Sélection des données : Comment sélectionner automatiquement les données pour obtenir de meilleurs résultats de distillation ?
Distillation multi-enseignants : Explorez la distillation des connaissances de différents modèles d'enseignants en un seul modèle d'élève.
Connaissances plus riches dans le modèle de l'enseignant : vous pouvez explorer des connaissances plus riches dans le modèle de l'enseignant, y compris les commentaires et les connaissances sur les fonctionnalités, et explorer une combinaison de plusieurs méthodes d'acquisition de connaissances.
Surmonter l'oubli catastrophique lors de la distillation : La capacité à préserver efficacement le modèle original lors de la distillation ou du transfert de connaissances reste un défi.
Trusted Knowledge Distillation : Actuellement, KD se concentre principalement sur la distillation de diverses compétences et accorde relativement peu d'attention à la crédibilité des grands modèles.
Distillation faible à forte(Distillation faible à forte). OpenAI propose le concept de « généralisation faible à fort », qui nécessite d'explorer des stratégies techniques innovantes afin que les modèles les plus faibles puissent guider efficacement le processus d'apprentissage des modèles plus forts.
Auto-alignement (auto-distillation). Les instructions peuvent être conçues de manière à ce que le modèle de l'étudiant améliore et aligne de manière autonome son contenu généré en générant des commentaires, des critiques et des explications.
Conclusion
Cette revue fournit un résumé complet et systématique de la façon d'utiliser la connaissance des grands modèles de langage pour améliorer les modèles d'étudiants, tels que les grands modèles de langage open source, et inclut également la technologie d'auto-distillation récemment populaire . Cette revue divise la distillation des connaissances en deux étapes : l'acquisition des connaissances et l'algorithme de distillation, et résume également la distillation des compétences et la distillation sur le terrain vertical. Enfin, cette revue explore l'orientation future de la distillation de grands modèles de langage, dans l'espoir de repousser les limites de la distillation des connaissances des grands modèles de langage et d'obtenir de grands modèles de langage plus accessibles, efficaces, efficients et crédibles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre le problème de la non-suppression de fichiers sur l'ordinateur
Comment résoudre le problème de la non-suppression de fichiers sur l'ordinateur
 vcruntime140.dll est introuvable et l'exécution du code ne peut pas continuer
vcruntime140.dll est introuvable et l'exécution du code ne peut pas continuer
 Comment utiliser le stockage cloud
Comment utiliser le stockage cloud
 Comment verrouiller l'écran sur oppo11
Comment verrouiller l'écran sur oppo11
 Le câble réseau est débranché
Le câble réseau est débranché
 Tutoriel sur l'ajustement de l'espacement des lignes dans les documents Word
Tutoriel sur l'ajustement de l'espacement des lignes dans les documents Word
 utilisation de la fonction de rééchantillonnage
utilisation de la fonction de rééchantillonnage
 Plateforme de trading quantitatif de devises numériques
Plateforme de trading quantitatif de devises numériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



